R���Ի�����1������ʹ�ü���&��
advancer
������ѧ����ѧ+����ѧѧ��һö~
��ע��
1. ʹ�ý��ܺͼ���
1.1 R�Ļ�ȡ�Ͱ�װ��
Comprehensive R Archive Network CRAN
http://cran.r-project.org
•Linux �� Mac OS X �� Windows ������Ӧ����õĶ����ư汾��
•��װ���� package ����Ϊ��ѡģ��ͬ���ɴ� CRAN ���أ�����ǿ R �Ĺ��ܡ�
•Windows ����ϵͳ���˵����ϰ�װ R ������ƽ̨��R gui & R studio
���ѡ��Windows ϵͳ����Ҫ�ٰ�װ Rtools:
•Rtools is a toolchain bundle used for building R packages from source (those that need compilation of C/C++ or Fortran code) and for build R itself.
RTools: Toolchains for building R and R packages from source on Windows
https://cran.r-project.org/bin/windows/Rtools/rtools43/files/rtools43-5493-5475.exe
1.2 ʹ�ü���
r studio�������R Markdownд������rmd�ļ��������ڱ���
����Ҫ���е������ǰ������ĸ����book������Ctrl+���Ϲ��������Ϳ�����ʾ��ʷ��������book��ͷ���������������һ������һ�����Զ����Ƶ�������
Rmd �ļ�����```{r} ��ͷ����```��β�Ķ����� R����Σ�
����ʾ�ij���ε��Ҳ���һ�����Ҽ�ͷ��״��Сͼ��
��������ý�岥��ͼ�꣩�������ͼ��Ϳ������иó���Ρ�
2. ����package��
2.1 ����
•���� R ���������ݡ�Ԥ���������һ�ֶ������Ƶĸ�ʽ��ɵļ��ϡ�������ϴ洢����Ŀ¼��Ϊ�⣨library��
•���� libPaths() �ܹ���ʾ�����ڵ�λ�ã�
•���� library() �������ʾ���а�װ����Щ����
•R �Դ���һϵ��Ĭ�ϰ������� base �� datasets �� utils �� grDevices ��graphics �� stats �Լ� methods �������ṩ��������Ĭ�Ϻ��������ݼ���
���� search() ���Ը�������Щ���Ѽ��ز���ʹ�á�
R studio���½ǿ��Բ��ҡ������
2.2 ��װ
install.packages(" ")
������ɹ�����CRAN�������أ�
install.packages ("gclus", repos = "https://mirrors.tuna.tsinghua.edu.cn/CRAN/")
2.3 ���£�update.packages(" ")
2.4 �鿴�Ѿ���װ�İ���installed.packages()
2.5 ���룺library( )
library �� require ������ ����� �������ߴ�������
���һ���������ڣ�ִ�е�library ����ִֹͣ�У� require ������ִ�У�����False
2.6 �鿴��
���� help ( package = "package_name") �������ij�����ļ�������Լ����еĺ������ƺ����ݼ����Ƶ��б�
2.7 ж�غ�ж��
ж�أ�detach������ʹ��
ж����remove������ʹ��
R���Ի�����2��������������
advancer
������ѧ����ѧ+����ѧѧ��һö~
��ע��
2 ����ͬ�˸�����
1. ��ֵ
x <- ����
��age <- c(20,21,30,50)
2. ����
3. ���ù���Ŀ¼
setwd ("C:/myprojects/��") ������ \\ ��\��һ��ת�����
��ʾ��ǰ����Ŀ¼λ�ã�getwd()
4. ������ʷ��¼/���������ռ�
savehistory() �����������ʷ��¼���浽�ļ� Rhistory �У�
save.image() ���������ռ䣨�������� x �����浽�ļ� RData �С�

�� options(digits=3)�����ֱ���ʽ��ΪС�����3λ��Ч���ֵĸ�ʽ
���ʹ��RStudio ������Ҳ��Ҫ�Ѳ�ͬ��Ŀ���ڲ�ͬ�ļ��У�����ÿ����Ŀ��RStudio �е�������һ������Ŀ����project����Ҫ�����ĸ���Ŀ�����ݣ��ʹ��ĸ���Ŀ����ͬ��Ŀʹ�ò�ͬ�Ĺ����ռ䡣
5. �������
1. ִ���ⲿ�ű�
source ("myscript.R")
��ִ�а������ļ� myscript.R �е� R ��伯�ϡ����չ������ű��ļ��� .R ��Ϊ��չ��
�������⣺
�� MS Windows ����ϵͳ�У�Ĭ�ϵ����ı����� GB18030 ���롣R Դ�����ļ������ı�������� GB18030Ҳ������ UTF-8��UTF-8 �������緶Χ��ͨ�õı��롣
���������������������ʱ�����������룬��������ΪԴ�������� UTF-8 ���룬
��ʱ source() ����Ҫ���ϱ���ѡ�����£�
source("myprog.R", encoding="UTF-8")
File �C Save/Reopen with Encoding
2. ����ı������ָ���ļ��У��ɸ���/��
sink(" filename")
�ļ��Ѿ����ڣ����������ݽ������ǡ�
ʹ�ò��� append=TRUE ���Խ��ı��ӵ��ļ������Ǹ�������
���� split=TRUE �ɽ����ͬʱ���͵���Ļ������ļ��С�
sink()������Ļ��ʾ������/�ر��ļ����ټ�¼
�� cat() ������ʾ�������ݣ�������ֵ���ı����ı�����������Ʋ�Ż�����˫Ʋ���У���:
cat("sin(pi/2)=", sin(pi/2), "\n")
## sin(pi/2)= 1
cat() �������һ��һ����"\n", ��ʾ���С����Դ�������С�
3. ���ͼ�ν����ָ���ļ���
dev.off()��������ն�
���º�������չ��("�ļ���")

R���Ի�����3����������������
advancer
������ѧ����ѧ+����ѧѧ��һö~
��ע��
1. �������ͺͽṹ
1. ��������
��ֵ�ͣ�numeric��
�ַ��ͣ�character��Ҳ����string
�����ͣ�date��
c<-as.Date ("2021 03 08")
class(c)
d<-as.POSIXct ("2021 03 08 13:00") �����ں�ʱ��
class(d)
4. ����logical��
e<- TRUE; f<- FALSE
��������class()�鿴�����е��������ͣ�
2. ���ݽṹ
���� vector ����С��λ��
�洢 ��ֵ�� ���ַ��� ������ ��һά���顣
����ʾ����
a <- c(1, 2, 5, 3, 6, -2, 4)
x < - 1:10

����matrix��������
�ú���matrix����
y <- matrix (vector, nrow=��, ncol=��, byrow = TRUE)
����array�����Զ�ά
���ݿ�dataframe����ͬ���������Ϳ��Բ�ͬ
�ú���data.frame()����

���ʱ�����LEC. 1 P59)
�����ݿ�
����factor�������ͱ�����categorial��
status <-c("Poor", "Improved", "Excellent", "Poor")
status <-factor(status, ordered=TRUE )
��ordered=TRUE ѡ�factor��ͨ���ӱ�� ���������
����������Ϊ(3, 2, 1, 3)�������ڲ�����Щֵ����Ϊ 1=Excellent �� 2=Improved �Լ� 3=Poor ��
��Դ��������е��κη������Ὣ����Ϊ�����ͱ����Դ������Զ�ѡ����ʵ�ͳ�Ʒ���������ͨ��ָ�� levels ѡ��������Ĭ������
status <- factor (status, order=TRUE , levels=c("Poor", "Improved", "Excellent"))
��ָ��1=Poor �� 2=Improved �� 3=Excellent
�б�list�������Ƕ����������͵����
2. �������롪�������ļ�
1. ��ȡ�ļ�
data<- read.table (file, header=TRUE, sep= "delimiter", row.names="namelist")
data <- read.csv ("xxx.csv", header=TURE, as.is = "TRUE")
��������read_csv()
print(head(tax.tab))
file ��һ�����ָ����� ASCII �ı��ļ���
header ��һ�����������Ƿ�����˱���������ֵ�� TRUE �� FALSE��
as.is=TRUE ˵���ַ�����Ҫԭ�����������ת��Ϊ����(factor)
sep ����ָ���ָ����ݵķָ�����
row.names ��һ����ѡ����������ָ��һ��������ʾ�б�ʶ���ı�����
head() �����������ݿ��������ǰ����
2. ���ݿ�Xд���ļ�
write.table (x, file = "", append = FALSE, quote = TRUE, sep = "", eol = "\n", na = "NA", dec = ".", row.names = TRUE, col.names = TRUE, qmethod = c("escape", "double"), fileEncoding = "")
3. web��ַ���ļ���������
• file <- http://162.105.145.16/rs/R_data_samples/export2020.csv
• pop<-read.csv(file, header=TRUE, sep = ",", stringsAsFactors = F)
• file <- http://162.105.145.16/rs/R_data_samples/export2020-1.csv
• pop<-read.csv(file, header=TRUE, sep = ",", stringsAsFactors = F) #����
• pop<-read.csv(file, header=TRUE, sep = ",", stringsAsFactors = F, fileEncoding
= "UTF-8") #�ӱ����ʽ
4. �������뷽ʽ
• Excel������
• ����XML
• ����ҳץȡ����
• ����SPSS
• ����SAS
• ����Stata
• ����NetCDF
• ����HDF5
R���Ի�����4��������ֵ���������㺯��
advancer
������ѧ����ѧ+����ѧѧ��һö~
��ע��
1. ����
�������ȳ��������������㣬
1. ����䳤��Ϊ������ϵ��������ÿ�δ�ͷ�ظ����ö̵�һ����
�������������㣬R ��������������������Ԫ��һһ��Ӧ����ij�������������ʱ������������Ȳ�ͬ��һ�㶼���������Ĺ���
2. ������������ij��Ȳ��DZ�����ϵ�������������Ϣ��
2. ��ѧ����
Ϊ�˲鿴��Щ��������ѧ�������б�����������help.start()��������ӡ�Search Engine and Keywords�����ҵ���Mathematics�� ��Ŀ��������еġ�arith�� �͡�math�� �����е�˵����
• ���룺ceiling, floor, round, signif, trunc, zapsmall
• ���ź��� sign
• ����ֵ abs
• ƽ���� sqrt
• ������ָ������ log, exp, log10, log2
• ���Ǻ��� sin, cos, tan
• �����Ǻ��� asin, acos, atan, atan2
• ˫������ sinh, cosh, tanh
• ��˫������ asinh, acosh, atanh
• �������� beta, lbeta
• ٤�꺯�� gamma, lgamma, digamma, trigamma, tetragamma, pentagamma
• ����� choose, lchoose
• ����Ҷ�任�;��� fft, mvfft, convolve
• ��������ʽ poly
• ��� polyroot, uniroot
• ���Ż� optimize, optim
• Bessel ���� besselI, besselK, besselJ, besselY
• ������ֵ spline, splinefun
• ���� deriv
3. ������
sort(x) ���ذ�˳�������Ľ��
rev(x) ���ذѸ�Ԫ�����д��� ��ת��Ľ��
order(x) ���������õ��±꣨��ʾ��С����������Ԫ��ԭ������λ�õ���ţ�
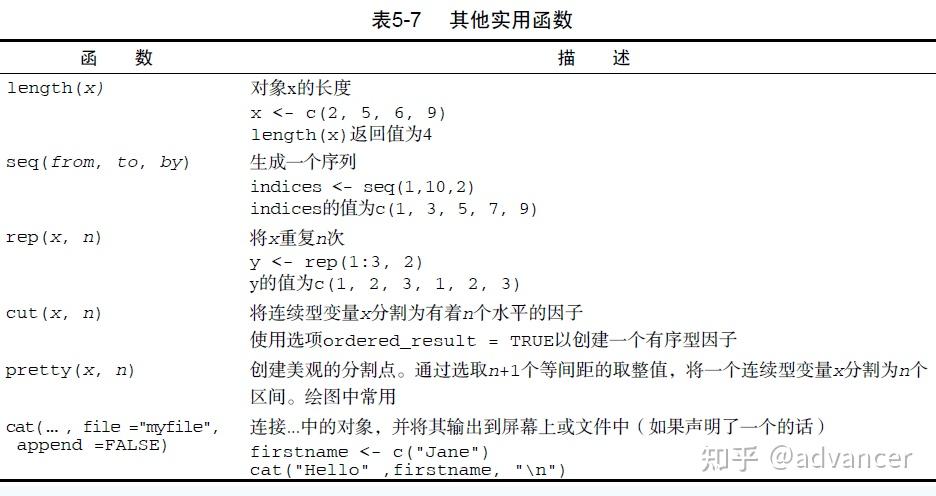
4. ��������
seq ������ð����������ƹ㡣
���磺
seq(5) ��ͬ��1:5��
seq(2,5) ��ͬ��2:5��
seq(11, 15, by=2) ����11,13,15
seq(0, 2*pi, length.out=100) ������0 ��2 �ĵȼ�����У����г���ָ��Ϊ100
����seq(to=5, from=2)} ��ͬ��2:5
rep() �������������ظ���ֵ��
Ϊ�˲���һ����ֵΪ��ij���Ϊn ���������� x <- rep(0, n)��
rep(c(1,3),2) �ѵ�һ���Ա����ظ����Σ�����൱��c(1,3,1,3)��
rep(c(1,3), c(2,4)) ����Ҫ����R ��һ�����������ѵ�һ�Ա����ĵ�һ��Ԫ��1 ���յڶ��Ա����е�һ��Ԫ��2 �Ĵ����ظ����ѵ�һ�Ա����еڶ���Ԫ��3 ���յڶ��Ա����еڶ���Ԫ��4 �Ĵ����ظ�������൱��c(1,1,3,3,3,3)��
���ϣ���ظ���һ��Ԫ�غ����ظ���һԪ�أ���each= ѡ�
����rep(c(1,3), each=2) ����൱��c(1,1,3,3)��
��һ�㼼���Ե�С���⣺1:5 ��seq(5) �Ľ�������ͣ�integer���ģ�c(1,3,5) ��seq(1, 5, by=2) �Ľ���Ǹ����ͣ�double���ġ�
5. ͳ�ƺ�������������ͳ�ơ���
summary(tax.tab[[" Ӫҵ��"]])
���Ը�����Сֵ�����ֵ����λ�����ķ�֮һ��λ�����ķ�֮����λ����ƽ��ֵ
mean()
sd()
sum(���)
var(����������)
min(����Сֵ)
max(�����ֵ)
range(����Сֵ�����ֵ)
prod ������Ԫ�صij˻�
cumsum ��cumprod �����ۼӺ��۳˻�
pmax, pmin, cummax, cummin
����na.rm=TRUE ѡ������������ȱʧֵ������ɾȥȱʧֵ�����ͳ����
6. ��������
ָ��ʵ���鲿��complex (real = c(1,0,-1,0), imaginary = c(0,1,0,-1))
ָ��ģ�ͷ��ǣ�complex (mod=1, arg=(0:3)/2*pi)
���ɽ����c(1+0i, 1i, -1+0i, -1i)
��Re(z) ��z ��ʵ������Im(z) ��z ���鲿��
��Mod(z) ��abs(z) ��z ��ģ����Arg(z) ��z �ķ��ǣ�
��Conj(z) ��z ���
R���Ի�����5����������&�ַ�������&�������㺯��
advancer
������ѧ����ѧ+����ѧѧ��һö~
��ע��
1. ��������
��һ�����ԱȽϣ�
��NA�Ƚϻ����NA
Ϊ���ж�����ÿ��Ԫ���Ƿ�NA����is.na() ����
< <= > >= == != %in%
�ֱ��ʾС�ڡ�С�ڵ��ڡ����ڡ����ڵ��ڡ����ڡ������ڡ����ڡ�Ҫע����ڱȽ����������Ⱥš�
%in% �DZȽ�����ıȽϣ�x %in% y ����������� y ���ɼ��ϣ���������һ������������x�ĵ�i��Ԫ���Ƿ�����y������ֵ���������ֵ����=x������Ԫ��������
&, | �� ! , �ֱ��ʾ��ͬʱ��������������������һ���������������ķ��桱
xor(x, y) ��ʾx ��y ��������㣬��ֵ�����ʱΪ��ֵ�����ʱΪ��ֵ����ȱʧֵ�μ�����ʱΪȱʧֵ��
��all() ��������Ԫ��Ϊ�棻��any() ��������һ��Ԫ��Ϊ�档������ȱʧֵ���������Ϊȱʧֵ
����which() ������ֵ��Ӧ�������±�
����identical(x,y) �Ƚ�����R ����x ��y �������Ƿ���ȫ��ͬ�����ֻ��ȡ����TRUE ��FALSE ���֡�
����all.equal() ��identical() ���ƣ������ڱȽ���ֵ��ʱ��������������ʵ���ͣ�������ͬʱ���ر���TRUE�����Dz�ͬʱ�᷵��һ��˵���кβ�ͬ���ַ�����
����duplicated() ����ÿ��Ԫ���Ƿ�Ϊ�ظ�ֵ�Ľ��
�ú���unique() ���Է���ȥ���ظ�ֵ�Ľ����
2. �ַ�������
ע����ַ����������Զ���Ϊ��ȱʧֵ���ַ��͵�ȱʧֵ����NA ��ʾ��
paste()��һ��һ�������������ַ�������
��Ĭ���ÿո����ӣ������趨sep=""��
collapse="" ��������һ���ַ����������ڲ��ĸ���Ԫ�����ӳ�һ����һ���ַ���
toupper() �������ַ�����������תΪ��д��tolower() ����תΪСд
��nchar(x, type='bytes') �����ַ�������x ��ÿ���ַ��������ֽ�Ϊ��λ�ij��ȣ�
��һ�����Ӣ�����в��ģ�����ͨ��һ������ռ�����ֽڣ�Ӣ����ĸ�����֡����ռһ���ֽڡ�
substr(x, start, stop) ���ַ���x ��ȡ���ӵ�start ������stop �����Ӵ�
substr(x, start,stop) ���ַ�������x��ÿ��Ԫ��ȡ�ӵ�start ������stop �����Ӵ�
substring(x, start) ���Դ��ַ���x ��ȡ���ӵ�start ����ĩβ���Ӵ���
as.numeric() �����������ֵ��ַ���ֵת��Ϊ��ֵ
as.character() ��������ֵ��ת��Ϊ�ַ���
��ָ���ĸ�ʽ��ֵ��ת�����ַ��ͣ�����ʹ��sprintf() ����
��gsub() �����滻�ַ����е��Ӵ��������Ĺ��ܾ����������������С�
���磬�������е����ı���ΪӢ�ı�㣬ȥ���ոȵȡ�
x <- '1, 3; 5'
gsub(';', ',', x, fixed=TRUE)
## [1] "1, 3, 5"
�ַ���x �зָ������ж������зֺţ�����ij�����gsub() �ѷֺŶ����ɶ��š�
�������ʽ
R ��֧��perl ���Ը�ʽ���������ʽ��grep() ��grepl() �������ַ����в�ѯij��ģʽ��sub() ��gsub() �滻ijģʽ��
��������
unique(x) ���Ի��x �����в�ֵͬ
a %in% x �ж�a ��ÿ��Ԫ���Ƿ���������x
match(x, table) ������x ��ÿ��Ԫ�أ�������table �в������״γ���λ�ò�������Щλ�á�û��ƥ�䵽��Ԫ��λ�÷���NA
intersect(x,y) ��������в����ظ�Ԫ��
union(x,y) ��������в����ظ�Ԫ��
setdiff(x,y) ������x ��Ԫ���в�����y ��Ԫ����ɵļ��ϣ�����в����ظ�Ԫ��
setequal(x,y) �ж����������Ƿ���ȣ����ܴ������ظ�Ԫ�ص�Ӱ��
R���Ի�����6���������ӣ�factor��
advancer
������ѧ����ѧ+����ѧѧ��һö~
��ע��
���ӣ�factor��
R�е����ݽṹ֮һ��R �������Ӵ��������з������, ���Ա�ʡ�ݡ�ְҵ���������Ӵ����������ȣ����ֽ�����������س̶ȵȡ�
1. ��������
1. factor() �������ַ�������ת��������
factor (x, levels = sort(unique(x), na.last = TRUE),
labels, exclude = NA, ordered = FALSE)
��������ѡ��levels ����ָ����ˮƽֵ, ��ָ��ʱ��x �IJ�ֵͬ����á�
������ѡ��labels ָ����ˮƽ�ı�ǩ, ��ָ��ʱ�ø�ˮƽֵ�Ķ�Ӧ�ַ�����
������exclude ѡ��ָ��Ҫת��Ϊȱʧֵ(NA) ��Ԫ��ֵ���ϡ����ָ���� levels, ���Ա���x ��ij��Ԫ�ص��ڵ� ��ˮƽֵʱ��������Ӷ�ӦԪ��ֵȡ���� , �����Ԫ��ֵû�г�����levels ������������Ӷ�ӦԪ��ֵȡNA��
ordered ȡ��ֵʱ��ʾ����ˮƽ���д����(���������)��
��ʹ��factor() ������������ʱ�����֪���Ա���Ԫ�ص����п���ȡֵ��Ӧ������ʹ��levels= ����ָ����Щ��ͬ����ȡֵ����������ʹij��ȡֵû�г��֣��˱��������ĺ����Ƶ����ϢҲ�������ġ��Լ�ָ��levels= ����һ�ô��ǿ�����ȷ�Ĵ�����ʾ���ӵķ���ͳ��ֵ����Ϊһ�����ӵ�levels �����Ǹ����Ӷ��еģ�������c() ����rbind() �ϲ����������п�����ɴ����յ��������ڶ�����������ʱ��levels ����ָ����ͬ��ˮƽֵ���ϡ����°汾��R �����Ѿ������������⡣��
2. levels() ��������levels����
levels(sex)
## [1] " ��" " Ů"
���ӵ�levels ���Կ��Կ�����һ��ӳ�䣬������ֵ1,2,�� ӳ�����Щˮƽֵ�������ڱ���ʱ�ᱣ�������ֵ1,2,������ˮƽֵ��Ӧ�ı�š�
1) as.numeric() ��������ת��Ϊ���������ֵ
as.numeric(sex)
## [1] 1 2 1 1 2
2) as.character() ��������ת����ԭ�����ַ���
3. cut()����
����ȡֵ�ı�����������cut() ��������ֶΣ�ת�������ӡ�ʹ��breaks() ����ָ���ֵ㣬��С�ֵ�ҪС�����ݵ���Сֵ�����ֵ�Ҫ���ڵ������ݵ����ֵ��Ĭ��ʹ�����ұ��������
Ϊ��ʵ�ָ�������Ƚ�ƽ���ķ��飬quantile() ���������λ����Ϊ����
table()��ͳ�����Ӹ�ˮƽ�ij��ִ�������ΪƵ����Ƶ�ʣ���Ҳ���Զ�һ�������ͳ��ÿ����ͬԪ�صij��ִ���
tapply() ������
���������ӷ���Ȼ��ÿ�������һ�����ĸ���ͳ��
����������������һ�����飬����һ����ͳ������
h <- c(165, 170, 168, 172, 159)
tapply(h, sex, mean)
## ��Ů
## 168.3333 164.5000
2. forcats ��
fct_reorder() ���Ը��ݲ�ͬ����ˮƽ�ֳɵ�������һ��ֵ�ͱ�����ͳ����ֵ����
fct_reorder() ����������ͳ�����������������
fct_relevel()������������ˮƽ���϶�ʱ���뽫�ض���һ����ˮƽ����ŵ�����ˮƽ��ǰ��
fct_reorder2(f, x, y) Ҳ��������f ��ˮƽ�Ĵ����Ǹ�����ÿ��������x ֵ���Ӧ��y ֵ��С�����������������������ˮƽ��Ӧ������ͼʱ���ԱȽ��������ֶ������ߡ�
fct_recode() ������ÿ��ˮƽ������
����ϲ��ܶ࣬������fct_collapse() ����
���ij������Ƶ���ٵ�ˮƽ�ܶ࣬��ͳ��ʱ�й���ˮƽ����չʾ��Ҫ����𣬿�����fct_lump(f) �ϲ���ȱʡ�ش����ٵ���ϲ�һֱ���������� �೬��������С����֮ǰ��������n= ����ָ��Ҫ�������ٸ��ࡣ
R���Ի�����7�������б���list��
advancer
������ѧ����ѧ+����ѧѧ��һö~
��ע��
1 ����ͬ�˸�����
�б������ж��Ԫ�أ�������������ͬ���ǣ��б��IJ�ͬԪ�ص����Ϳ��Բ�ͬ
1. ����/����
list()
rec <- list(name=" ����", age=30, scores=c(85, 76, 90))
2. ����Ԫ��
�����б�Ԫ�ر����� [[���ط�����]] ��ʽ����
rec[[3]]
## [1] 85 76 90
rec[[3]][2]
## [1] 76
rec[["age"]]
## [1] 30
�б��ĵ���Ԫ��Ҳ������$ ��ʽ���ʣ���
rec$age
## [1] 30
���ʹ�õ��ط����Ŷ��б�ȡ�Ӽ�����������б��������б�Ԫ��
rec[3]
## $scores
## [1] 85 76 90
�б�һ�㶼Ӧ����Ԫ������Ԫ�������Կ����DZ��������б��е�ÿ��Ԫ�ؿ���һ����������names() �����鿴����Ԫ����
3. ��/����/ɾ��Ԫ��
rec[[" ���Ʒ���"]][2] <- 0
## $ ���Ʒ���
## [1] 85 0 90
��ij���б�Ԫ�ظ�ֵΪNULL ��ɾ�����Ԫ�ء���
rec[["age"]] <- NULL
��list() ��������������Ԫ��ΪNULL��������Ԫ���Ǵ��ڵ�
4. �б�����ת��
��as.list() ��һ���������͵Ķ���ת�����б���
��unlist() �������б�ת���ɻ���������
5. ���
strsplit() ����һ���ַ���������ָ��һ���ָ���������һ���������ַ�������Ԫ�ظ�����ͬ���б����б�ÿ���Ӧ���ַ���������һ��Ԫ�صIJ�ֽ��
sapply() �������Ѳ�ֽ�������������б��ı�������һ��ת����һ����ֵ�;���
R���Ի�����8��������������飨matrix&array��
��������飺
������matrix �������壬ʵ�ʴ洢��һ�����������ݱ����������������Ӧ�������Ԫ�أ��洢����Ϊ���д洢�����ϵ��£������ң���
1. ����
A <- matrix(11:16, nrow=3, ncol=2)
matrix() �����Ѿ���Ԫ����һ����������ʽ����
��nrow ��ncol �涨������������
����Ԫ����������ȱʡ�����ǰ������룬
��byrow=TRUE ѡ�����ת���ɰ������롣
����t(A) ���� A ��ת�á�
2. ����
nrow() ��ncol() �������Է��ʾ��������������
dim() ������dim() ���ԣ�����������Ԫ�ص�����������Ԫ�طֱ�Ϊ�����������������
3. �Ӽ�
ע���ڶԾ���ȡ�Ӽ�ʱ�����ȡ�����Ӽ�����һ�л����һ�У�����Ͳ����Ǿ�����DZ����R ������R �����Ȳ���������Ҳ�������������������������Ĺ��������ã���Ҫ�ڷ������±��м�ѡ��drop=FALSE
1. ����ֵ�±���ȡ
��A[1,] ȡ��A �ĵ�һ�У����һ����ͨ������
��A[,1] ȡ��A �ĵ�һ�У����һ����ͨ������
��A[c(1,3),1:2] ȡ��ָ���С��ж�Ӧ���Ӿ���
2. ���ַ��������±���ȡ
A[,'Y']
A['b',]
A[c('a', 'c'), 'Y']
colnames() �������Ը�����ÿ��������Ҳ���Է��ʾ���������
rownames() �������Ը�����ÿ��������Ҳ���Է��ʾ�������
3. �����±꣨�ж���������ȡ
A[A[,1]>=12,'Y']
4. ��һ��������������������ȡ
�������һ������ȡ�Ӽ�����������һ�������������ľ���ȡ�Ӽ�
A[c(1,3,5)] ����Ĭ���е�����˳��
5. ��һ�����еľ�����Ϊλ���±꣬һ�б�ʾ������һ�б�ʾ������ ��ȡ
ind <- matrix(c(1,1, 2,2, 3,2), ncol=2, byrow=TRUE)
A
## X Y
## a 11 14
## b 12 15
## c 13 16
ind
## [,1] [,2]
## [1,] 1 1
## [2,] 2 2
## [3,] 3 2
A[ind]
## [1] 11 15 16
6. ����ȡ��������
�Ծ���A��diag(A) ����A �����Խ���Ԫ����ɵ�������
��x Ϊ������ֵ������diag(x) ����x��λ��
��x Ϊ���ȴ���1 ��������diag(x) ������x ��Ԫ��Ϊ���Խ���Ԫ�صĶԽǾ���
4. ����任���ϲ�
��x ��������cbind(x) ��x �����������������Ϊ1 �ľ���rbind(x) ��x �����������
��x1, x2, x3 �ǵȳ���������cbind(x1, x2, x3) �����ǿ�������������һ�����һ�����������б�������ʱ�˱������ظ�ʹ�á�rbind()����
5. ����
��������
���������������������㣬���Ϊÿ��Ԫ�ؽ�����Ӧ����
������Ϊ�������һ������ʱ���������Դ����еľ�����������㡣
����ͬ��״�ľ�����мӡ������㣬����ӦԪ����ӡ����
������ͬ��״�ľ�����* ��ʾ���������ӦԪ�����(ע���ⲻ�����Դ����еľ���˷�)
2. ��/��ʾ���������ӦԪ�������
��%*% ��ʾ����˷���������* ��ʾ
�ڻ���sum(x*y)
�����x %o% y
�����solve()��solve(A,b) ������Է����� = �е�
6. apply() ����
apply(A, 2, FUN) �Ѿ���A ��ÿһ�зֱ����뵽����FUN �У��õ���Ӧ��ÿһ�еĽ����
apply(A, 1, FUN) �Ѿ���A ��ÿһ�зֱ����뵽����FUN �У��õ���ÿһ�ж�Ӧ�Ľ����
�������FUN ���ض�������������Ϊ����
7. ������
����/���ɣ�
������<- array(����Ԫ��, dim=c(��һ�±����, �ڶ��±����, ..., ��s�±����))
ara <- array(1:24, dim=c(2,3,4))
4 ��2 �� 3 ����ȡ������һ����ara[ , , 2](ȡ���ڶ�������)��ara[,2, 2:3]
R���Ի�����9���������ݿ�dataframe��
advancer
������ѧ����ѧ+����ѧѧ��һö~
��ע��
2 ����ͬ�˸�����
���ݿ�
���ݿ����Excel ���ݱ�����ʽ
����data.frame() �����������ݿ�
as.data.frame(x) ����x���������б�������ת�������ݿ�
1. ����
d <- data.frame(
name=c(" ����", " �Ŵ�", " ����"),
age=c(30, 35, 28),
height=c(180, 162, 175),
stringsAsFactors=FALSE)
��ѡ��stringsAsFactors=FALSE ���Ա��⽫�ַ�����ת��������
������ݿ��ijһ��Ϊ������������data.frame() �����н������и�һ��ֵ�����ɵĽ�����Զ��ظ����ֵʹ
�ø����������еȳ���
nrow(d) ��d ��������ncol(d) ��length(d) ��d ��������
names(d) ��colnames(d) ���Է���/������
2. �ϲ�/����
����order�������������ݺ����㺯����������ֵ�����㡪��������
�ϲ���
����
merge(A, B, by=c("colname1", "colname2")); by=�ظ�����
cbind (A, B)
����rbind (A, B)
3. ����Ԫ��/ȡ�Ӽ���drop=FALSE��
���ݿ�����þ����ʽ���ʣ���
d[2,3]
## [1] 162
���ʵ���Ԫ�ء�
d[[2]]
## [1] 30 35 28
���ʵڶ��У����Ϊ������
(Ϊ����ȡһ��Ϊ����Ӧʹ��˫�����Ÿ�ʽ��$��ʽ������tibble)
����ǰ����attach��detach����ֱ���ñ���������$��
���������������
d[["age"]]
## [1] 30 35 28
d[ ,"age"]
## [1] 30 35 28
d$age
## [1] 30 35 28
>myvars<- c("q1", "q2", "q3", "q4", "q5")
>newdata<- leadership[myvars]
>myvars<- paste("q", 1:5, sep ="")
>newdata<- leadership[myvars]
����ͬʱȡ���Ӽ������Ӽ�
4. tibble����
һ�ָĽ������ݿ�readr ����read_csv() ������read.csv() ������һ���Ľ��汾��
����CSV�ļ�����Ϊtibble ����
��as_tibble() ���Խ�һ�����ݿ�ת��Ϊtibble,
dplyr ���ṩ��filter()��select()��arrange()��mutate()�Ⱥ���
������tibble ѡȡ���Ӽ������Ӽ��������Ļ����±���
��tribble ( ) ����������CSV ��ʽ����һ��tibble, ��
tribble(
~`���`,~`����ѹ`,
1,145,
5,110,
6,NA,
9,150,
10,NA,
15,115
) |> knitr::kable()
read_csv() Ҳ֧�ִ�һ�������ַ���ֱ�Ӷ������ݣ��磺
readr::read_csv(" ���, ����ѹ
1,145
5,110
6,NA
9,150
10,NA
15,115
") |> knitr::kable()
R���Ի�����10�������������ݹ���
advancer
������ѧ����ѧ+����ѧѧ��һö~
�����Ĵ���/�ر���/������
ʹ��ԭ�б��������±�����
ֱ�Ӵ�����dataframe$newcol1 = dataframe$oldcol1 + dataframe$oldcol2
transform����
dataframe <- transform(dataframe, newcol1 = oldcol1 + oldcol2, newcol2 = oldcol1 - oldcol2)
3. mutate����
dataframe <- mutate(dataframe, newcol1 = oldcol1 + oldcol2)
dataframe <- mutate(dataframe, newcol2 = oldcol1 - oldcol2)
�ر��루��ԭ�б�������ȴ����±�����
�ֱ����
leadership$agecat agecat[leadership$age > 75] <-"Elder"
2. ��within������������
dataframe <-within(dataframe, {
agecat[age > 75] <-"Elder"
agecat[age >= 55 & age <= 75]<-"Middle"})
������
1. >library(plyr) # ���� library(reshape)
>rename( dataframe , oldname="newname", oldname="newname")
ע�����������ʱ��û�иı� dataframe ���� ������һ���µ����ݿ�
��ͬ���е�ͬ���������ܵ��÷�ʽ�����ط�ʽ����һ����
>library(dplyr) # ����صİ���ߵĺ���������ǰ���
>rename( dataframe , newname= oldname , newname= oldname, ��)
Ϊ����ȷ���ò��������� dplyr:: rename( ��
2. names() ����
>names (leadership)[2] <-"testDate"
>names (leadership)[6:10] <- c("item1", "item2", "item3", "item4", "item5")
ȱʧֵ��NA��NAN��
NA�Dz����õ�ȱʧֵ��
NAN�Dz����ܳ��ֵ�ֵ����0��������
�жϣ�is.na()
�������Ҳ����ȱʧֵ
����ʱ�ų�ȱʧֵ�� na.rm = TRUE
ɾ������NA����/�У�newdata <- na.omit(data)
ɾ������
ɾ����8�͵�9�У�����q3&q4����
>newdata <- leadership[ c(-8, -9) ]
����ֱ�Ӹ�ֵNULL :
>leadership$q3 <- leadership$q4 <- NULL
R���Ի�����10�������������ݹ�����2��
advancer
������ѧ����ѧ+����ѧѧ��һö~
�ϲ�������
����order�������������ݺ����㺯����������ֵ�����㡪��������
�ϲ���
merge(A, B, by=c("colname1", "colname2"))
by=�ظ�����
merge(data_A, data_B, by=c(colname1,colname2,...), all=___ )
all=TRUE ��Ӧ�������ϲ�������������ƥ����δƥ�������
cbind (A, B)
����rbind (A, B)
ɸѡijЩ�н���۲�
1) ɸѡ��
which( )����
> dataframe [which (dataframe$colname1 + ����1 & dataframe$colname2 + ����2 , ]
> ������ ID
which����ʡ�ԣ�ֱ�ӷ�����[]ȡ
2) ѡ��۲⣬subset() ��Ӧ��
���������ݿ�ɸѡ�е�����������ֵ���������ļ��У�����������select = )
newdata<- subset(leadership, age >= 35 | age < 24, select=c(q1, q2, q3, q4))
��select=gender:q4)
������ȡ
sample ���� , replace=FALSE ��ʾ���Ż�
��leadership���ݼ��������ȡһ����СΪ3��������
mysample <- leadership[sample(1:nrow(leadership), 3, replace=FALSE),]
����ʵ�ú���
R���Ի�����11������ѭ��&����ִ��
advancer
������ѧ����ѧ+����ѧѧ��һö~
1. ѭ��
�ڴ��������ݼ��е��к���ʱ��R�е�ѭ�����ܱȽϵ�Ч��ʱ��
���Ӧ��R�е�������ֵ/�ַ�����������apply�庯����
ѭ���еĸ��
���statement��һ�� �� ʹ�ã������{}�еĶ��
����cond�������жϱ���ʽ
����ʽexpr��������е���ֵ���
����seq����ֵ/�ַ�������
for �ṹ
for (var in seq) statement �磺
for (i in 1:10) print("Hello")
while�ṹ
while (cond) statement �磺
i <- 10
while( i>0 ) { print("Hello") ; i<- i-1}
2. ����
if-else�ṹ
• if (cond) statement
• if (cond) statement1 else statement2
�磺
if (is.character(grade)) grade <- as.factor(grade)
if (!is.factor(grade)) grade <- as.factor(grade) else print("Grade already is a factor")
ifelse�ṹ: if-else�ṹ�Ľ�����ʽ
• ifelse (cond, statement1, statement2)
• �� if (cond) statement1 else statement2 ������ͬ
�磺
>ifelse(score > 0.5, print("Passed"), print("Failed"))
>outcome <- ifelse (score > 0.5, "Passed", "Failed")
switch�ṹ�����ݱ���ʽ��ֵ��ѡ��ִ��
switch (expr, list)
expr Ϊ����ʽ����ֵ��Ϊһ�� ����ֵ ��Ϊһ�� �ַ����� list Ϊһ���б���
���� list ���������� ʱ���� expr ����Ԫ���� ʱ�����ر�������Ӧ��ֵ������û�з���ֵ��
�Զ��庯��
myfunction <- function(arg1,arg2, ... ){
statements
return(object)
}
R���Ի�����12���������ں�ʱ��
advancer
������ѧ����ѧ+����ѧѧ��һö~
1. �������ͣ�
Date�����ڣ�һ�����������棬��ֵΪ��1970-1-1 ���������������ԼӼ���������Ϊ�����Ӽ���
POSIXct��������ʱ�䱣��Ϊ��1970 ��1 ��1 ����ʱ��������ʱ���ʱ���������з��ŵ������� ���������ԼӼ�һ��������
POSIXlt��������ʱ�䱣��Ϊһ�������ꡢ�¡��ա����ڡ�ʱ���֡���ȳɷֵ��б�����������Щ�ɷֿ��Դ�POSIXlt ��ʽ���ڵ��б������л�á�
����Ǽ�ȥ1900�����ֵ��mon���·ݣ��Ǵ�0��ʼ
>lt >c (1900 + lt$year , lt$mon+1 , lt$mday, lt$hour, lt$min, lt$sec)
[1] 1980 9 30 10 11 12
2. ���ɣ�
as.Date()�����Ѷ��yyyy-mm-dd ��yyyy/mm/dd ��ʽ���ַ���ֱ��ת��ΪDate���ͣ�������ʽ����ָ�� "format="�������ȶ���һ���ַ���Ϊ��ʽ��PPT2-P24��
as.POSIXct()���Ѷ�������ո�ʽ������ת��ΪR �ı�����
3. ��չ��lubridate
3.1 ������ת����
today() ��Sys.date() ���ص�ǰ����
now() , date() ��Sys.time() ���ص�ǰ����ʱ�� (CST��ʱ��������ʹ���˲���ϵͳ�ṩ�ĵ�ǰʱ��)
������tz= ָ��ʱ��
>with_tz (meeting, "GMT")
>mistake < force_tz (meeting, "UTC")
unclass() ������ʱ�䳤�����ݵ�����ת��Ϊ����Ϊ��λ����ͨ��ֵ
ymd(), mdy(), dmy() ��������ַ�������ת��Ϊ����������
����hms��hm��h �Ⱥ����������ڽ��ض���ʽ���ַ���ת��������ʱ�䡣�磺
ymd_hms("1998-03-16 13:15:45")
## [1] "1998-03-16 13:15:45 UTC"
ymd (20110101)��ymd("2011-01-01")
make_date(year, month, day) ���Դ������������ֵ������������
make_datetime(year, month, day, hour, min, sec)
as_date() ���Խ�����ʱ����ת��Ϊ������
as_datetime() ���Խ�����������ת��Ϊ����ʱ����
as.character() ����������������ת��Ϊ�ַ���
��format ѡ��ָ����ʾ��ʽ��
�磺
as.character(x, format='%m/%d/%Y')
%A�����ڼ�
3.2 ȡ��/�ı�/��ֵ �����ͻ�����ʱ���������е���ɲ��֣�
• year() ȡ����
• month() ȡ���·���ֵ
• mday() ȡ������ֵ
• yday() ȡ��������һ���е���ţ�Ԫ��Ϊ1
• wday() ȡ��������һ�������ڵ���ţ�����һ�����ڴ������쿪ʼ��������Ϊ1, ����һΪ2��������Ϊ7��
• hour() ȡ��Сʱ
• minute() ȡ������
• second() ȡ����
update() �����п�����year, month, mday, hour, minute, second �Ȳ��������ڵ���ɲ���
3.3 �����������
floor_date()������ȥ
round_date()����ȡ��
ceiling_date()�����������루�����
unit= ָ��һ��ʱ�䵥λ�������롣
ʱ�䵥λΪ�ַ�������seconds, 5 seconds, minutes, 2 minutes, hours, days, weeks, months, years �ȡ�
�����λ�����ڣ����漰��һ���������ڵĿ�ʼ�������ջ�������һ�����⡣�ò���week_start=7 ָ����ʼ�������գ�week_start=1 ָ����ʼ������һ��
3.4 �����������㣨�Ӽ��˳���
�������ͣ�
• ʱ�䳤��(duration)�����������
• ʱ������(period)�����ա���
• ʱ������(interval)������һ����ʼʱ���һ������ʱ��
POSIXct���� ����ʱ��֮�������Ӽ���
�������ڲ���ֱ�Ӽ��㡣��һ�����ڼӼ�һ������������ͨ���Ӽ�����ʵ��
as.POSIXct(c('1998-03-16 13:15:45')) + 3600*24*2
## [1] "1998-03-18 13:15:45 CST"
as.duration(d1-d2)��������������֮��IJ�𣬵õ�������������difftime
����ֱ��d1-d2
difftime(time1, time2, units='days') ������time1 ��ȥtime2 �����������������c() ������ת��Ϊ��ֵ, �������е�λ��
interval(time1, time2)������ʱ����
�ȼ���time1 % -- % time2
������ʱ�䳤��֮����ӣ�Ҳ���Զ�ʱ�䳤�ȳ�����������
���Ը�һ�����ڼӻ���ȥһ��ʱ�䳤�ȣ�����ϸ����Ƶ���������
dseconds(), dminutes(), dhours(), ddays(), dweeks(), dyears() ��������ֱ������ֵ����ʱ�䳤�����͵����ݣ�������Ϊ��λ��
seconds(), minutes(), hours(), days()��weeks(), years() ������������������������������Ϊ��λ��ʱ�䳤�ȣ�����Ҫ����������ϵ��
��������ʱ���ǰ�����ơ���Щʱ�����ڵĽ��������ӡ���������������
R���Ի�����12��������ͼ��1��
• �Զ�����š���������ɫ��������
��ɫ
• ����ͨ����ɫ�±ꡢ��ɫ���ơ�ʮ��������ɫֵ��RGBֵ��HSVֵ��ָ����ɫ��
���磬col=1��col="white"��col="#FFFFFF"��col=rgb(1,1,1)��col=hsv(0,0,1)����ʾ��ɫ��
• ����rgb()�ɻ��ں졪�̡�����ɫֵ������ɫ����hsv()�����ɫ�ࡪ���Ͷȡ�����ֵ��������ɫ��
• ������������ɫ�����ĺ���������rainbow()��heat.colors()��terrain.colors()��
topo.colors()�Լ�cm.colors()
���磬rainbow(10)��������10�������ġ��ʺ��͡���ɫ����Ҷ�ɫ��ʹ��gray()��������

• ��ע�ı��ͱ���
�ı�
par (font.lab=3, cex.lab=1.5, font.main=4, cex.main=2)
֮��������ͼ�ζ���ӵ��б�塢1.5����Ĭ���ı���С���������ǩ��
�Լ���б�塢2����Ĭ���ı���С�ı���


• ����ͼ��ά�� ���ߴ�ͱ߽磩

• par(pin=c(4,3), mai=c(1,.5, 1, .2))
• ����һ��4Ӣ�����3Ӣ��ߡ����±߽�Ϊ1Ӣ�硢��߽�Ϊ0.5Ӣ�硢�ұ߽�Ϊ 0.2Ӣ���ͼ�Ρ�
• ��϶��ͼ��
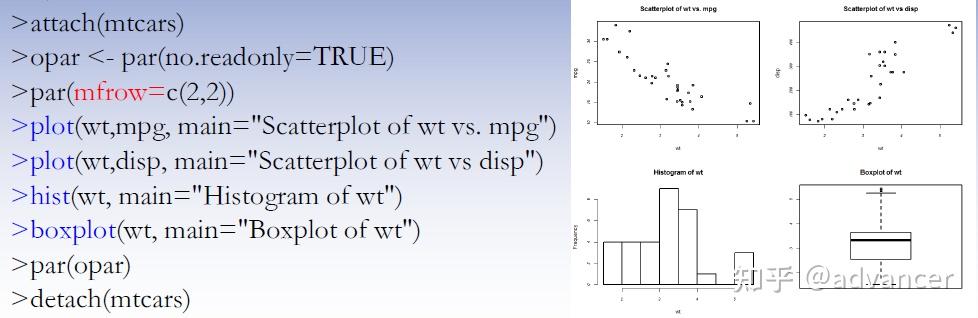
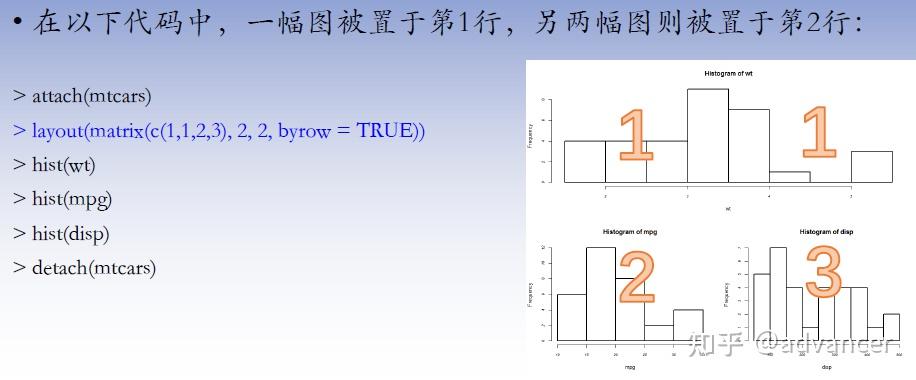
����par()��layout()
������par()������ʹ��ͼ�β���mfrow=c(nrows, ncols)�������������ġ�����Ϊnrows������Ϊncols��ͼ�ξ���ʹ��mfcol =c(nrows, ncols)����������