如何克服边缘设备中的硬件加速障碍
发布于2023-06-12 10:13:44 Efinix
AI发展进程中,将越来越多地在边缘实现机器学习和运算。不过,在边缘运行机器学习算法语言,在可重构性、功耗、延迟、成本、尺寸和易开发性等诸多方面,都遇到明显的技术瓶颈。本文讨论如何通过在创新量子计算架构上创建FPGA,实现灵活可重构性,并有效克服基于边缘设备的所有障碍,实现可扩展嵌入式处理解决方案。
针对在边缘运行机器学习算法而言,在可重构性、功耗、尺寸、速度和成本方面,FPGA超越了多种其他方式的人工智能芯片组。此外,与微体系架构无关的RISC-V指令集体系架构(ISA)能够与FPGA的体系架构灵活性无缝结合。然而,一个主要瓶颈就是明显缺乏成本效益高的中端FPGA,而且设计流程也比较复杂。另外,也很难找到用于实现完全自定义硬件描述语言(HDL)所需的软件技术,而且还往往伴随着陡峭的学习曲线。
Efinix利用在创新量子计算架构上建立的FPGA填补了这一空白,该架构由可重新配置模块组成,被称为可交换逻辑和路由(XLR)单元,作为逻辑或路由,重新优化了逻辑元件(LE)和路由资源的传统固定比率,从而支持在小型器件封装中利用高密度架构,其中FPGA的所有资源都被充分利用。该平台的潜力超越了当今基于边缘的设备面临的典型障碍:功耗、延迟、成本、尺寸和易开发性。
Efinix FPGA最引人注目的特点,可能是其周围的生态系统和最先进的工具流,这降低了开发门槛,使设计师能够利用同等的硅,在边缘轻松实现人工智能(从原型到量产)。通过采用RISC-V,从而允许用户在软件中创建应用程序和算法,利用该ISA的易编程性,而不必绑定到ARM等专有IP核上。由于这一切都是通过灵活的FPGA架构完成的,用户可以在硬件上大幅加速。另外,Efinix还同时支持低级别和更复杂的自定义指令加速。其中一些技术包括TinyML加速器和预定义的硬件加速器sockets。通过这样的方法,所实现的跳跃式加速既提供了硬件性能,同时又保留了软件定义模型,从而可以在不需要学习VHDL的情况下进行迭代和细化。其结果使得边缘设备的速度极快,同时功耗低,占位面积小。本文详细讨论了Efinix平台如何简化整个设计和开发周期,让用户能够利用灵活的FPGA架构,来实现可扩展的嵌入式处理解决方案。
边缘面临的设计障碍
从大规模的无线传感器网络,到流式传输高分辨率360度沉浸式AR或VR体验,现实世界中大多数数据都处于边缘。将运算负荷从云中剥离出来,并使其更接近边缘设备,为自动驾驶、沉浸式数字体验、自动化工业设施、远程手术等下一代带宽密集型、超低延迟等应用打开了大门。一旦避开了从云端传输数据的巨大障碍,用例就会层出不穷。
然而,对于边缘而言,低延迟、高耗能运算这类决定性因素,正是对这些体积小且功率有限的设备带来重大设计挑战的主要因素。那么,如何设计一种设备,既能处理耗电的ML算法,而又不需要采用复杂的技术呢?该解决方案的硬件可以是任何类型(例如,CPU、GPU、ASIC、FPGA、ASSP),但资源要足以运行合适的应用程序和算法,同时又能够加速密度更高的运算任务,并能平衡运算时间(延迟)和所用资源(功耗)。
与任何创新一样,随着模型和优化技术的更新,深度学习的环境也在不断变化,这就需要利用更灵活的硬件平台。这些平台的变化速度几乎与在其上运行的程序一样快,而且几乎不能有风险。FPGA的并行处理和灵活性/可重新配置性,似乎与这一需求完全匹配。然而,要使这些设备用于大规模的主流应用,还需要降低加速FPGA架构和配置的设计门槛――这是一个耗时的过程,通常需要高级专业知识。此外,传统的加速器一般来说细粒度都不够,并且通常还包含不易扩展的大模型块。另外,这类设备通常比较耗能,而且往往是独家制造的,这使得工程师必须重新学习如何利用这类定制平台。
Sapphire RISC-V内核
利用C/C++即可在RISC-V内核上创建应用程序
Efinix通过以直观的方式克服了AI/ML社区利用FPGA方面的挑战,从而直接解决了所有这些潜在的障碍。可通过Efinity GUI对RISC-V Sapphire内核进行完全用户配置。通过这种方式,用户不必全部知道在FPGA中实现RISC-V背后的所有VHDL,而可以利用通用软件语言(例如C/C++)的直接可编程性,这使得团队能够在软件中快速生成应用程序和算法。所需的所有外围设备和总线,都可以与Sapphire内核一起指定、配置和实例化,从而能提供完全可配置的SoC(见图1)。这种RISC-V功能包括多个内核(最多四核),支持Linux功能,为设计师的FPGA应用程序提供高性能处理器集群,并能够直接在Linux操作系统上运行应用程序。通过软硬件分区,下一步的硬件加速被大大简化。一旦设计师在软件中完善了算法,就可以在灵活的Efinix FPGA架构中实现稳步加速。不过,在进入下一步的硬件加速之前,重要的是要了解RISC-V架构的固有优势,以及如何在FPGA架构中充分利用。
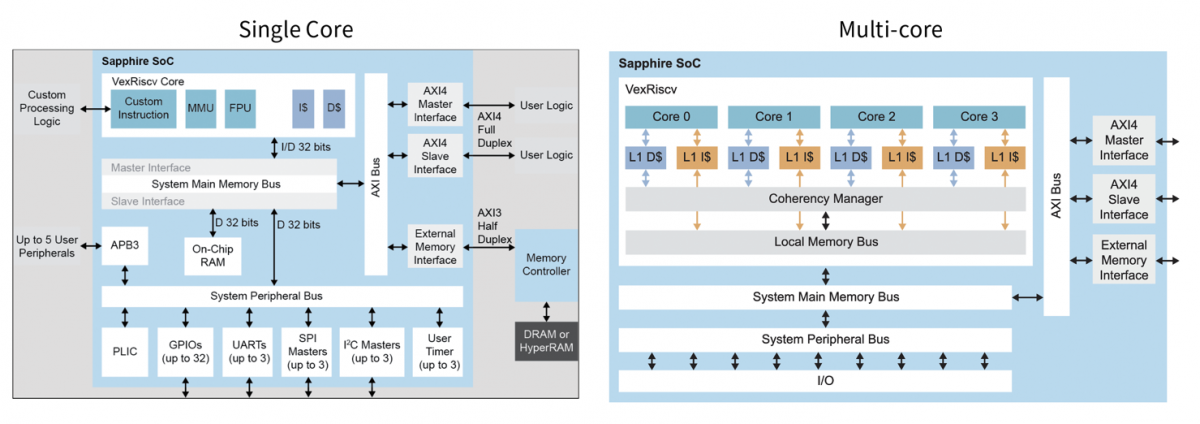
图1:Efinity GUI支持开发人员利用熟悉的编程语言,为完全可配置的SoC配置Sapphire RISC-V内核(左)以及所有所需的外围设备和总线。此功能可扩展到多达四个RISC-V内核。
支持自定义指令的RISC-V
RISC-V架构的独特之处在于,它并没有对所有指令都进行定义,而是预留了一些指令,开放给设计师自定义和实现。换句话说,可以创建一个自定义算术逻辑单元(ALU),当调用自定义指令时,可执行自定义的任意功能(见图2)。这些自定义指令,将具有与其他指令相同的体系架构(例如,两个寄存器输入,一个寄存器输出),总共支持使用八个字节的有效数据,其中四个字节的数据可以回传至RISC-V。
然而,由于ALU是在FPGA中构建的,它既可以访问FPGA,也可以从FPGA中提取数据,从而支持用户扩展超过8字节的数据,使ALU变得任意复杂,并支持访问以前送入FPGA上的数据(例如来自传感器的数据)。当涉及到硬件加速时,这种能力(能够使ALU任意复杂)则正是速度的倍增因素。Efinix利用了定制指令的这种能力,并通过TinyML平台将其发布到AI和ML社区。
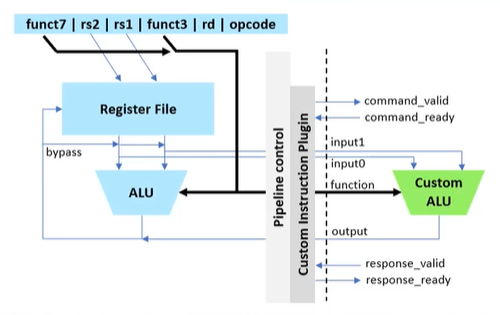
图2:可以利用RISC-V创建自定义ALU,其标准配置包括两个四字节宽的源寄存器(rs1和rs2)和一个四字节宽的目标寄存器(rd)。
TinyML平台-自定义指令库
利用TinyML平台的硬件加速
TinyML平台简化了硬件加速过程,其中Efinix采用了TensorFlow Lite模型中所用的计算原语,并创建了自定义指令,使得在FPGA架构中实现的加速器上的执行得以优化(见图3)。从而将TensorFlow的标准软件定义模型吸收到了RISC-V复合体中,以硬件速度进行加速,并利用了开源TensorFlow Lite社区的丰富优势。使用流行的Ashling工具流,简化了整个开发流程,使设置、应用程序创建和调试过程变得既简单又直观。
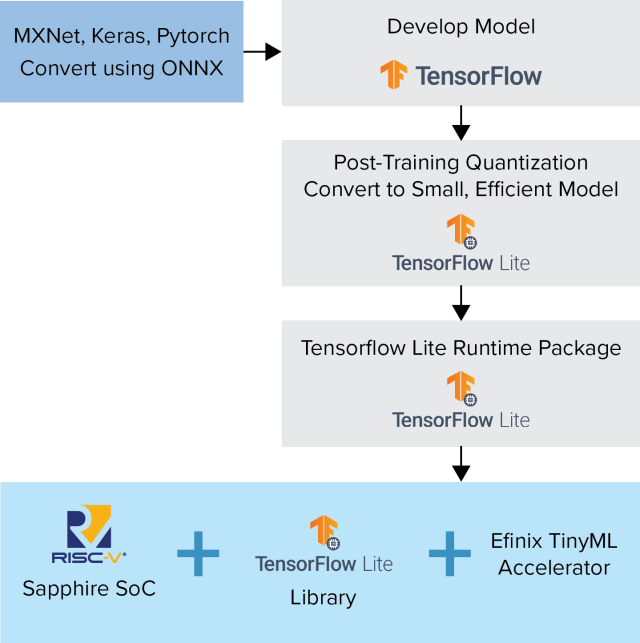
图3:TensorFlow Lite模型示意图。
TensorFlow Lite创建了标准TensorFlow模型的量化版本,并利用函数库,支持这些模型在边缘MCU上运行。Efinix TinyML采用这些TensorFlow Lite模型,并利用RISC-V内核的自定义指令功能,在FPGA硬件中实现加速。
许多TinyML平台的自定义指令库,都可供Efinix GitHub上的开源社区免费访问,可以访问设计和开发大幅加速边缘AI应用所需的Efinix Sapphire内核以及其他任何东西。
加速策略
由于RISC-V内核、Efinix FPGA架构和丰富的开源TensorFlow社区的有机结合,从而支持创造性的加速策略,这些策略可以分解为几个步骤(图4):
步骤1:利用Efinity RISC-V IDE运行TensorFlow Lite模型
步骤2:利用TinyML加速器
步骤3:用户自定义的指令加速器
步骤4:硬件加速器模板
如上所述,“步骤1”是贯穿Efinity GUI的标准流程,用户可以利用Tensorflow Lite模型,并在RISC-V上的软件中运行它,采用的是与标准MCU中相似且设计师非常熟悉的流程,而根本不必担心VHDL。在步骤1之后,设计师通常会发现,他们正在运行的算法性能不是最优的,因此需要加速。“步骤二”涉及硬件-软件分区,用户可以在TensorFlow Lite模型中实现基本构建块,然后点击并拖动以实例化自定义指令,并在Sapphire RISC-V内核上对运行中的模型大幅加速。
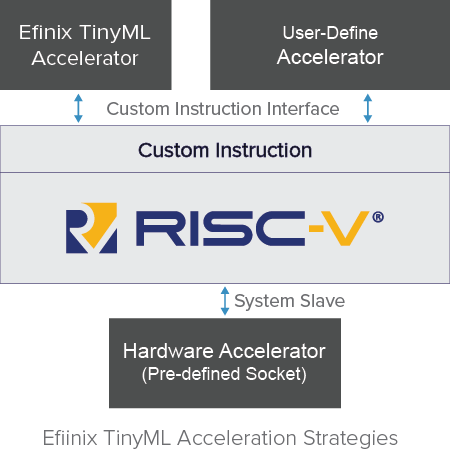
图4:Efinix TinyML平台的加速策略。
用户定义的自定义指令加速器
“步骤3”支持设计师在没有利用TinyML平台中模板的情况下,创建自己的自定义指令,支持用户在RISC-V内核上进行创新并实现加速。
硬件加速器模板
最后,所需的基本单元在RISC-V上被加速之后,“步骤4”利用加速“sockets”,将它们掩藏在免许可的Efinix SoC框架中。量子加速器sockets支持用户“指向”数据、检索数据、并对内容进行编辑,或者说对更大的数据块执行卷积运算。
Sapphire SoC可用于执行整体系统控制,并执行固有顺序或需要灵活性的算法。如前所述,通过硬件-软件代码设计,支持用户选择该运算是在RISC-V处理器中执行,还是在硬件中执行。在这种加速方法中,预定义的硬件加速器sockets连接到直接存储器访问(DMA)控制器和SoC从接口,用于数据传输和CPU控制,也可以用于AI推理之前或之后的预处理/后处理。为了设计中简化外部存储器与其他构建块之间的通信(参见图5),DMA控制器采用以下方式:
・将数据帧存储到外部存储器中
・向硬件加速块发送数据并从硬件加速块接收数据
・将数据发送到后处理引擎
在图像信号处理应用中,这看起来像是让RISC-V处理器作为嵌入式软件执行RGB到灰度的转换,而硬件加速器则在FPGA的流水线以及流式架构中执行Sobel边缘检测、二进制侵蚀和二进制扩展。这可以扩展到多摄像头视觉系统,使开发商能够快速地将其设计转化为产品并得以部署。
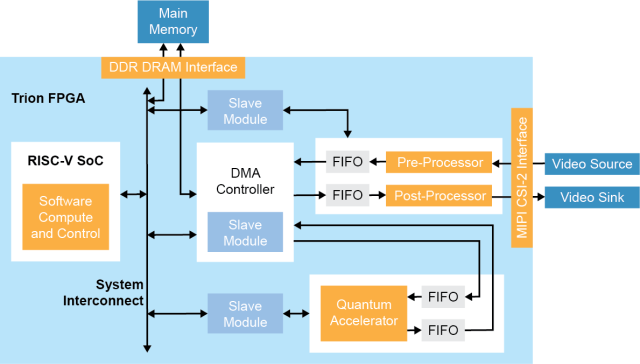
图5:采集边缘视觉SoC架构方框图。
MediaPipe Face Mesh用例
通过一个例子可以更好地凸显该流程的简单性。该例中,MediaPipe Face Mesh ML模型对数百个不同的三维面部标志进行实时估计。Efinix采用了这个模型,并将其部署在Titanium Ti60开发套件上,时钟频率为300MHz。在总延迟中,RISC-V内核上的卷积运算所产生的延迟占比最大,如图6所示。值得注意的是,图6中所显示的高达近60%的FPGA资源利用率,实际上并不能反映ML模型的大小。相反,引起的原因是由于整个相机子系统已经在FPGA中实例化,目的是为了使加速度基准测试能够实时执行。
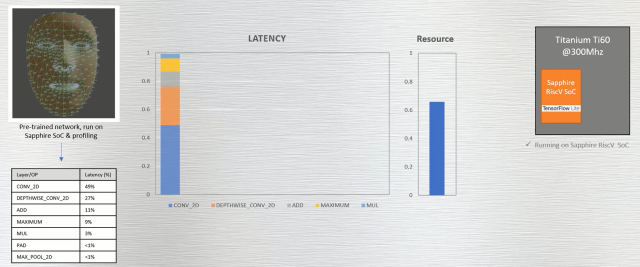
图6:在Ti60开发套件上运行MediaPipe Face Mesh预训练网络时的延迟和所占资源。
利用TinyML平台的简单自定义指令(步骤2)
创建并运行一个简单的、自定义的两个寄存器输入、一个寄存器输出卷积指令,可以将延迟性能改善四到五倍。随着用于加速ADD、MAXIMUM和MUL功能的自定义指令的利用,这种改进仍在继续。然而,由于RISC-V实现这些操作花费时间本身就较少,故延迟改进步入了平稳期(图7)。
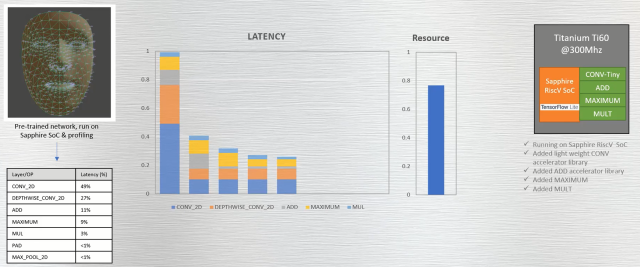
图7:通过为CONV、ADD、MAXIMUM和MUL函数创建简单的自定义指令,显著改善了延迟。
利用DMA的复杂指令(步骤4)
另外还生成了一个任意复杂的ALU来替换原始CONV。这改变了原始曲线的斜率,并再次显著改进了延迟。然而,由于复杂指令占用了FPGA内部更多资源,FPGA的资源利用率也大幅上升。同样,资源条显示也接近100%。其实原因也很简单,因为这里的FPGA包含了用于演示的整个相机子系统。需要着重注意的是,延迟的相对减少对应的正是资源利用率的增加(图8)。
更重要的是,如果切换到更大规模的FPGA(如Ti180)来运行所有这些复杂的指令,并进行大规模加速,所用的FPGA资源甚至还不到50%。这些明显的权衡,让工程师能够容易地看到在FPGA的延迟、功耗、成本、以及规模之间的平衡行为。对于具有严格延迟要求但功率限制较为宽松的边缘应用,可以选择大幅度加速设计,来充分提高性能。而在功率受限的应用中,则可以通过降低时钟速率,来实现更温和的性能改进,换取功耗的显著降低。
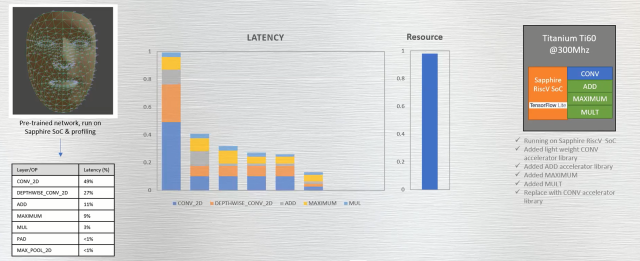
图8:利用自定义卷积指令实现加速时的资源消耗示意图。
图8中,利用更大的自定义卷积指令来获得更多的加速,但所消耗的资源急剧增加。请注意,FPGA资源的几乎全部利用,是因为FPGA包含整个相机子系统,如果Ti60只是运行ML模型,资源利用率将大幅降低。
人工智能/机器学习发展的范式转变
简而言之,Efinix结合了熟悉的RISC-V ISA开发环境,并利用其自定义指令功能,在架构灵活的FPGA中发挥作用。与许多硬件加速器不同,这种方法不需要任何第三方工具或编译器。利用机器指令实现的加速,加速也是细粒度的,而这一级别的粒度,只有FPGA才能实现。
边缘设备可以原型化,并部署在Efinix FPGA的创新设计架构上,这意味着该解决方案经得起未来考验。新的模型和更新的网络架构,可以在熟悉的软件环境中表达,并且只需少量的VHDL(具有可用模板库以用于指导),就可以在自定义指令级别上实现加速。这种程度的硬件-软件分区,其中90%的模型保留在RISC-V上运行的软件中,从而可以保证非常快的上市时间。
由于所有这些方法的完美结合,导致了一个优异解决方案的产生,从而真正降低了边缘设备的实现门槛。设计师如今可以利用世界级的嵌入式处理能力,还可以利用最先进的工具流进行访问,并在革命性的Efinix Quantum架构上进行实例化。
(参考原文:How Efinix is Conquering the Hurdle of Hardware Acceleration for Devices at the Edge)
本文为《电子工程专辑》2023年6月刊杂志文章,版权所有,禁止转载。点击申请免费杂志订阅