,景行锐创的怎么样?
国内的HPC,整体方案的话推荐曙光,曙光在2008年到2016年都蝉联亚洲超算第一。
相关产品有曙光Gridview HPC版、曙光集群配置管理运维工具Clusconf、曙光集群软件环境自动部署工具Clussoft。
其中Clussoft提供包括编译器、常用函数库、并行库、GPGPU开发环境、HPC benchmark工具机、以及HPC各领域的常用软件的自动安装部署。
国内的不了解,不过slurm之类的免费不是也挺好的么?其实感觉这些scheduler 真心大同小异,规模小的话用哪个都区别不大,规模大的话不管用哪个坑是肯定有的,所以要么雇一个真正懂得人来搞,要么买厂商的服务。
slurm安装配置_SLURM 超级计算机作业调度工具
时间静默
于 2021-01-09 04:31:49 发布
748
文章标签: slurm安装配置
版权
第一台超级计算机是 1964 年发布的(由 Seymour Cray 设计)Control Data Corporation (CDC) 6600。6600 使用硬件、Freon 冷却系统和能完成每秒浮点操作数为 3 百万的单个 CPU 填充了四个机柜。虽然并不缺少美感,但它的机柜却明显可见很多用于将外围单元处理器连接到单个 CPU 上以使其尽量繁忙的彩色电线。 快速发展至今,目前的超级计算机的领先者是日本的 Kei 计算机(由 Fujitsu 构建)。此系统注重于蛮力计算功能,使用了超过 88,000 个 SPARC64 处理器,占用了 864 个机柜。Kei 超级计算机的一个显著特点是突破了 10 千万亿次的障碍。与 CDC 6600 类似,Kei 使用的是水冷加气冷。
什么是超级计算机
超级计算机不是关于任何特定的架构,它只是处在计算性能尖端的一种设计。如今,这意味着如果以 LINPACK 基准度量,该系统能够在千万亿次(或百万之四次方的 FLOPS)的性能范围内运行。 无论超级计算机如何实现这些 FLOPS,任何超级计算机架构的一个低层目标都是在有工作可做时最佳地保持计算资源忙碌。与 CDC 6600 用来保持其单个 CPC 忙碌的外围处理器类似,现代的超级计算机需要同样的基本性能。让我们来看这样一个计算节点资源管理的实现,其名为 Simple Linux® Utility for Resource Management (SLURM)。
SLURM 简介
Slurm 任务调度工具(前身为极简Linux资源管理工具,英文:Simple Linux Utility for Resource Management,取首字母,简写为SLURM),或 Slurm,是一个用于 Linux 和 Unix 内核系统的免费、开源的任务调度工具,被世界范围内的超级计算机和计算机群广泛采用。它提供了三个关键功能。第一,为用户分配一定时间的专享或非专享的资源(计算机节点),以供用户执行工作。第二,它提供了一个框架,用于启动、执行、监测在节点上运行着的任务(通常是并行的任务,例如 MPI),第三,为任务队列合理地分配资源。 大约60%的500强超级计算机上都运行着Slurm,包括2016年前世界上最快的计算机天河-2。 Slurm使用基于Hilbert曲线调度或肥胖 网络拓扑结构的最适算法,以便优化并行计算机中的任务分配。 SLURM 是一种可用于大型计算节点集群的高度可伸缩和容错的集群管理器和作业调度系统。SLURM 维护着一个待处理工作的队列并管理此工作的整体资源利用。它还以一种排他或非排他的方式管理可用的计算节点(取决于资源的需求)。最后,SLURM 将作业分发给一组已分配的节点来执行工作并监视平行作业至其完成。 本质上,SLURM 是一个强健的集群管理器(更关注于对功能丰富性的需求方面),它高度可移植、可伸缩至大型节点集群、容错好,而且更重要的是它是开源的。SLURM 最早是一个开源的资源管理器,由几家公司(包括 Lawrence Livermore National Laboratory)协作开发。如今,SLURM 已经成为了很多最强大的超级计算机上使用的领先资源管理器。
SLURM 架构
SLURM 实现的是一种非常传统的集群管理架构。在顶部是一对冗余集群控制器(虽然冗余是可选项)。这些集群控制器可充当计算集群的管理器并实现一种管理守护程序,名为 slurmctld。slurmctld 守护程序提供了对计算资源的监视,但更重要的是,它将进入的作业(工作)映射到基本的计算资源。
每个计算节点实现一个守护程序,名为 slurmd。slurmd 守护程序管理在其上执行的节点,包括监视此节点上运行的任务、接受来自控制器的工作,以及将该工作映射到节点内部核心之上的任务。如果控制器发出请求,slurmd 守护程序也可以停止任务的执行。

此架构内还存在其他的守护程序,比如,实现安全的身份验证。但是集群并不仅仅是节点的随机组合,因为这些节点可以是逻辑相关的,以适时实现平行计算。
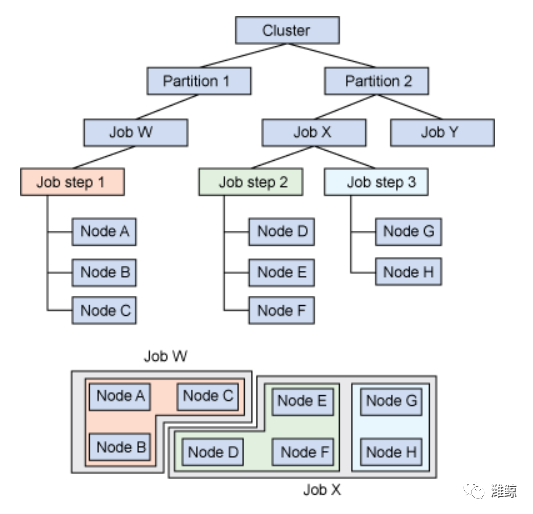
一组节点也可以组成一个逻辑组,称为分区,分区通常会包含进入工作的队列。分区也可以配置各种约束条件,比如哪个用户可以使用它,分区支持的时限的作业大小。分区的更进一步优化,就是将分区内的一组节点在工作的一段时间内映射到一个用户,这就是一个作业。一个作业内,是一个或多个作业步骤,即在节点子集上执行的任务集。
图 3 展示了这个层次结构,进一步说明了资源的 SLURM 分区。请注意,这种分区包含了对资源的感知,相当于确保协作节点间的低延迟通信。
SLURM 内的资源分区
安装 SLURM
如何安装 SLURM 最终取决于您特定的 Linux 环境,但过程与使用一个包管理器一样简单。SLURM 是完全打包的,这就使其很容易进行安装和配置。对于我所钟爱的 distro、Ubuntu,我使用了 Advanced Packaging Tool (APT) 来安装 SLURM 包及其所有的依赖项:
$ sudo apt-get install slurm-llnl
此操作会使用少于 40MB 的空间且不只包含了 SLURM,还包含了依赖项、基础插件以及其他所需的包。
配置 SLURM
启动 SLURM 之前,必须根据特定的环境配置它。为了创建我的配置文件,我使用了在线的 SLURM 配置器,由它为我生成基于表单数据的配置文件。请注意此文件需要在末尾处进行修改以删除不再受支持的选项。下面显示了我的结果配置文件(存储于 /etc/slurm-llnl/slurm.conf)。
面向单节点集群的 SLURM 配置文件
# slurm.conf file generated by configurator.html.# Put this file on all nodes of your cluster.# See the slurm.conf man page for more information.#ControlMachine=mtj-VirtualBox#AuthType=auth/noneCacheGroups=0CryptoType=crypto/opensslMpiDefault=noneProctrackType=proctrack/pgidReturnToService=1SlurmctldPidFile=/var/run/slurmctld.pidSlurmctldPort=6817SlurmdPidFile=/var/run/slurmd.pidSlurmdPort=6818SlurmdSpoolDir=/tmp/slurmdSlurmUser=slurmStateSaveLocation=/tmpSwitchType=switch/noneTaskPlugin=task/none## TIMERSInactiveLimit=0KillWait=30MinJobAge=300SlurmctldTimeout=120SlurmdTimeout=300Waittime=0## SCHEDULINGFastSchedule=1SchedulerType=sched/backfillSchedulerPort=7321SelectType=select/linear## LOGGING AND ACCOUNTINGAccountingStorageType=accounting_storage/noneClusterName=clusterJobCompType=jobcomp/noneJobCredentialPrivateKey = /usr/local/etc/slurm.keyJobCredentialPublicCertificate = /usr/local/etc/slurm.certJobAcctGatherFrequency=30JobAcctGatherType=jobacct_gather/noneSlurmctldDebug=3SlurmdDebug=3## COMPUTE NODESNodeName=mtj-VirtualBox State=UNKNOWNPartitionName=debug Nodes=mtj-VirtualBox default=YES MaxTime=INFINITE State=UP
请注意在一个真实的集群内,NodeName 应指的是一组节点,比如 snode[0-8191],以表示此集群内的 8192 个独特的节点(名为 snode0 至 snode8191)。
最后一个步骤是为我的站点创建一组作业凭证密钥。我选择使用 openssl 作为我的凭证密钥(在 清单 1 内的配置文件中作为 JobCredential* 引用)。我只使用 openssl 来生成这些凭证,如下所示。
为 SLURM 创建凭证
$ sudo openssl genrsa -out /usr/local/etc/slurm.key 1024Generating RSA private key, 1024 bit long modulus.................++++++............................................++++++e is 65537 (0x10001)$ sudo openssl rsa -in /usr/local/etc/slurm.key -pubout -out /usr/local/etc/slurm.certwriting RSA key
这些步骤完成后,就万事齐备了,我就能告诉 SLURM 我的配置了。我现在就可以启动 SLURM 并与其交互。
启动 SLURM
要启动 SLURM,只需使用 /etc/init.d/slurm 内定义的管理脚本。此脚本接受 start、stop、restart 和 startclean(以忽略之前保存的所有状态)。用这种方法启动 SLURM 会导致 slurmctld 守护程序的启动(在这个简单配置中,还包括您节点上的 slurmd 守护程序):
$ sudo /etc/init.d/slurm-llnl start
为了验证 SLURM 是否在运行,可以使用 sinfo 命令。sinfo 命令会返回有关这些 SLURM 节点和分区的信息(在本例中,集群由单个节点组成),如 清单 3 所示。
清单 3. 使用 sinfo 命令来查看集群
$ sinfoPARTITION AVAIL TIMELIMIT NODES STATE NODELISTdebug* up infinite 1 idle mtj-VirtualBox$
更多的 SLURM 命令
SLURM 内还有更多的命令可用来获得有关 SLURM 集群的更多信息。在 启动 SLURM 这个章节内,您会看到 sinfo 命令,可用来了解您的集群。您还可以用 scontrol 命令获得更多信息,这就使您可以查看集群各方面的详细信息。
用 scontrol 获得有关集群的详细信息
$ scontrol show partitionPartitionName=debug AllocNodes=ALL AllowGroups=ALL Default=YES DefaultTime=NONE DisableRootJobs=NO Hidden=NO MaxNodes=UNLIMITED MaxTime=UNLIMITED MinNodes=1 Nodes=mtj-VirtualBox Priority=1 RootOnly=NO Shared=NO PreemptMode=OFF State=UP TotalCPUs=1 TotalNodes=1 $ scontrol show node mtj-VirtualBoxNodeName=mtj-VirtualBox Arch=i686 CoresPerSocket=1 CPUAlloc=0 CPUErr=0 CPUTot=1 Features=(null) Gres=(null) OS=Linux RealMemory=1 Sockets=1 State=IDLE ThreadsPerCore=1 TmpDisk=0 Weight=1 BootTime=2012-03-07T14:59:01 SlurmdStartTime=2012-04-17T11:10:43 Reason=(null)
要测试这个简单的 SLURM 集群,可以使用 srun 命令。srun 命令可以为您的作业分配一个计算资源并启动一个任务。请注意您也可以分别实现这两个目的(通过 salloc 和 sbatch)。如 清单 5 内所示,您可以提交一个简单的 shell 命令作为您的作业来演示 srun,然后再提交一个 sleep 命令(带参数)来演示 squeue 命令的使用,从而展示集群内存在的作业。
向集群提交作业并检查队列状态
$ srun -l hostname0: mtj-VirtualBox$ srun -l sleep 5 &[1] 24127$ squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 15 debug sleep mtj R 0:03 1 mtj-VirtualBox$[1]+ Done srun -l sleep 5$
注意以上,向集群提交的作业可以是一个简单的 Linux 命令、一个 shell 脚本文件或一个适当的可执行文件。
作为最后一个例子,让我们来看看如何停止一个作业。在本例中,您启动一个运行较长的作业并使用 squeue 来识别其 ID。然后,使用 scancel 命令与这个作业 ID 来终止该作业步骤
终止一个作业步骤
$ srun -l sleep 60 &[1] 24262$ squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 16 debug sleep mtj R 0:03 1 mtj-VirtualBox$ scancel 16srun: Force Terminated job 16$ srun: Job step aborted: Waiting up to 2 seconds for job step to finish.0: slurmd[mtj-VirtualBox]: error: *** STEP 16.0 CANCELLED AT 2012-04-17T12:08:08 ***srun: error: mtj-VirtualBox: task 0: Terminated [1]+ Exit 15 srun -l sleep 60$
最后,可以使用相同的 slurm-llnl 脚本来停止集群。
停止 SLURM 集群
$ sudo /etc/init.d/slurm-llnl stop * Stopping slurm central management daemon slurmctld [ OK ] * Stopping slurm compute node daemon slurmd [ OK ]slurmd is stopped$
与 Apache Hadoop 不同,SLURM 没有分布式文件系统的概念。因此,为了一个给定的计算,它需要更多的处理才能将数据分布到节点。SLURM 包含了这样一个命令,名为 sbcast,可用来将一个文件传递到一个 SLURM 作业分配的所有节点。跨 SLURM 集群的节点使用平行或分布式的文件系统是很有可能的(而且更为高效),这样一来,就不需要 sbcast 来分布要处理的数据了。
在这个简单 SLURM 的演示中,我们使用的只是可用命令的一个子集,以及这些命令可用选项的一个更小的子集(比如,参见 srun 命令的可用选项)。即便是用最少数量的可用命令,SLURM 都能实现一个有效和高效的集群管理器。
定制 SLURM
SLURM 并不是一个静态的资源管理器,而是一个可以结合新行为的高度动态的资源管理器。SLURM 实现了一个插件应用程序编程接口 (API),允许运行时库在运行时动态加载。这个 API 已经用于开发各种新行为,包括互连结构、身份验证和调度。插件接口支持各种其他功能,比如作业统计、加密功能、消息传递接口 (MPI)、过程跟踪以及资源选择。所有这些都允许 SLURM 可以轻松支持不同的集群架构和实现。
SLURM 的前景
2011 年,SLURM 因各种新特性的加入而得到了更新,包括对 IBM Blue Gene/Q 超级计算机和 Cray XT 以及 XE 计算机的支持。此外,还添加了对 Linux 控制组 (cgroups) 的支持,这对 Linux 过程容器提供了更大的控制。
2012 年,Blue Gene/Q 支持将会全面实现,同时实现的还有改进的资源选择,该资源选择取决于作业需求和资源功能(比如,节点特性 AMD)。一种新的工具计划用来报告调度统计,而且在不久的将来,还将会有一种基于 Web 的管理工具。SLURM 的另一个未来计划是在云爆发的上下文中,这会涉及到在云提供者中分配资源,以及将溢出的工作从一个本地集群迁移到云中(也要运行 SLURM 守护程序)。这个模型非常有用,而且支持某些超级计算机工作负载弹性的理念。
最后,SLURM 开发人员也在考虑使用功率和热量数据,以便更有效地分配集群内的工作,比如,将消耗大功率(也会产生更多热量)的作业放在集群内散热较好的区域。
总结
对 SLURM 的简单介绍阐明了这个开源资源管理器的简便性。虽然现代的超级计算机超出了大多数人的价格范围,SLURM 仍提供了可伸缩的集群管理器的基础,可将商用服务器转变成高性能集群。而且,SLURM 的架构还使得更易于对超级计算机(或商品集群)架构定制资源管理器。这可能也是其成为超级计算机领域内领先的集群管理器的原因。
相关资源:ansible-role-slurm:用于安装和配置SLURM-用于资源管理的简单...