1、引言
目前已经有很多学者和研究机构意识到网站日志数据巨大的潜在价值,试图通过对Web日志的研究来改善网站设计,理解用户的兴趣和真正动机等。多数现有的Web分析工具提供了用户在服务器上的活动情况及各种形式的过滤数据,使用这类工具可以确定对某个服务器或单个文件的访问次数、访问时间以及用户的域名和URL。但是对于Web日志数据仓库系统进行总体设计上的研究并不多,而这项工作对于研究用户访问模式和提高挖掘的效率是很有意义的。本文以某网站Web日志文件为例,在JAVA平台上对其数据仓库的建构进行了研究。
2、Web日志数据采集
服务器日志的格式根据Web服务的应用及安装时的选项而有所不同,一般用两种格式存储:一种是普通日志文件格式;另一种是扩展日志文件格式。普通日志文件存储的是客户端IP、用户名、状态、服务器名、协议版本等客户连接的物理信息。扩展日志文件格式主要支持关于日志文件元信息的指令,如版本号、会话监控开始时间和浏览器类型等。下面是一条典型的日志及其各字段详细解释:
2004-12-13 0:00:45 172.16.96.22 - 211.66.184.35
80 GET /~janyst/chat/chatUsers.php - 200 Mozilla/4.0+ (compatible;+MSIE+6.0;+Windows+NT+5.1)
● Date and Time:请求的日期、时间;
● c_ip:访问用户的 IP 地址或者用户使用的代理服务器 IP 地址;
● userName:用户名,由于通常用户没有进行注册,故一般都为占位符所替代;
● s_ip:客户端访问网站的IP 地址;
● s_port:客户端访问网站的端口号;
● cs_method:访问者的请求命令,常见的方法有三种,分别是 GET、POST 和 HEAD;
● cs_uri_stem:访问者请求的资源,即相对于服务器上根目录的途径,上例中为/~janyst/chat/chatUsers.php;
● query:协议类型,上例中为HTTP/1.1;
● Status:服务器返回的状态代码。一般而言,以2开头的状态代码表示成功,以3开头表示由于各种不同的原因用户请求被重定向到了其他位置,以4开头表示用户端存在某种错误,以5开头表示服务器遇到了某个错误;
● userAgent:附加信息,包括浏览器类型、操作系统等。
3、Web日志管理系统架构
Web日志管理系统功能是完成Web日志的预处理和存储,主要由数据采集模块、数据库创建模块、数据库清除模块和数据集生成模块等组成,图1为系统用户界面。
图1 Web日志管理系统用户界面
该系统是在Eclipse环境下搭建的,主要由四个模块组成,分别为数据库建立模块、数据采集模块、数据库清除模块和数据集生成模块组成。各模块功能介绍如下:
● 数据库生成模块:在已创建的空数据库里生成用于存储Web日志数据的各个二维表;
● 数据采集模块:功能主要是将Web日志导入已生成的数据库的各个表中。首先解析Web日志,即将文本格式的日志依次读入到数组中;其次对日志进行基本的预处理,具体的预处理过程会在下节中详细介绍;最后将预处理后的数据存储到数据库中;
● 数据库清除模块:可以清除数据库中已创建的各个表,数据库仍然保留;
数据集生成模块:可将Web日志以文本形式导出。
4、Web日志数据库
4.1 Web日志数据库介绍
Web日志数据仓库是基于Web日志数据库。根据分析需求,将数据库分为5个表,图2为其ER图,各表功能分别为:(1)IDTbl存储解析后日志的各个属性的 ID号;(2)UserTbl存储访问者的基本信息;(3)PathTbl存储访问路径的相关信息;(4)TimeTbl存储访问时间的相关信息;(5)ProtocolTbl:存储日志其它信息;
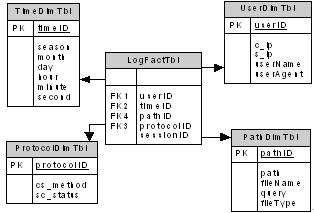
图2 Web日志数据库ER图
4.2 Web日志预处理
在将原始Web日志导入关系数据库之前必须进行清理、转换,计算一些必要的聚集信息。日志数据有其特殊性,它是一种半结构化的数据,因此预处理过程有其特殊性。本文在构建Web日志数据库时通过数据清洗、用户识别和会话识别这几个步骤。
4.2.1 数据清洗
Web日志的清洗工作很多文献都有讨论。当用户请求一个网页时,与这个网页有关的图片、音频等信息会自动下载,并记录在日志中。这些文件对于日志的分析是无用的,所以可以通过检查cs_uri_stem的后缀删除认为不相关的数据。同时无效记录还包括请求失败记录。本文在进行数据清洗时具体过程如图3所示:
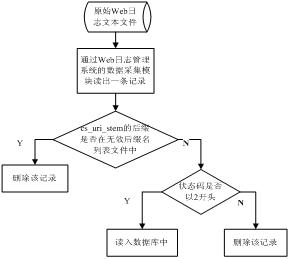
图3 数据清洗流程图
4.2.2 用户识别
用户识别是将用户和请求的页面相关联的过程。由于用户机器中缓存、防火墙、代理服务器的使用,使Web日志没有精确记录用户的浏览行为。因此从净化日志中识别用户工作相对比较复杂。主要的用户识别方法主要有三种,分别为基于cookie的技术、基于IP地址的用户识别以及基于网络拓扑结构的路径分析。方法一通过在Web日志文件中添加更多的附加信息如用户机器名、内部IP名来标示用户,从而能识别通过同一代理服务器上网的不同用户。方法二是指不同的IP地址代表不同的用户。方法三要求根据网络拓朴结构分析Web日志文件中的用户请求,构造用户浏览网页的路径,通过一些启发式规则来识别用户。由于本文用到的日志属性信息较多,包括浏览器和操作系统属性,所以系统采用基于IP地址和浏览器的方法进行用户识别,即不同的IP地址和浏览器类型代表不同的用户,并在数据库的表UserTbl以及表IDTbl中添加一个域userID,用于存储进行识别后的用户标识。具体的过程如图4所示:
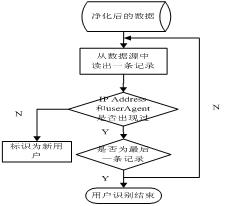
图4 用户识别流程图
4.2.3 会话识别
会话是指用户在访问网站期间从进入网站到离开网站所进行的一系列活动。要构造一个会话就是将每个用户的活动日志按照某种方法映射到会话中的过程。识别会话的方法主要有两种:基于时间的启发式方法和基于引用的启发式方法。前者利用会话的时间特性来构造会话候选集合;后者根据用户浏览特性和网页间链接关系确定用户会话集。
本文采用基于时间的启发式方法进行会话识别,即同一用户依次发出相邻的页面请求之间的时间间隔如不超过时间阈值,那么这两个页面请求属于同一个会话将时间阀值设定为20分钟。在数据库表中添加一个域sessionID,用于存储进行识别后的会话标识。进行会话识别的具体流程如图5所示。
5 Web日志数据仓库逻辑建模
要建立Web日志数据仓库,首先要进行逻辑建模。数据仓库一般有两种逻辑模式:星型模式和雪花模式。
星型模式是一种关系型数据库结构,其典型形式是由中间的一个主表和围绕在其周围的一组小表组成,中间的主表称为“事实表”,外围的小表称为“维度表”。事实表中存储数值型度量指标和连接到维度表的外键,它包含了描述特定商业事件的数据,例如产品销售、网站访问情况等;维度表中存储用于描述事物的文本属性信息及连接到事实表的主键,它包含了用于参考存储在事实表中数据的数据,如时间、地理位置等。雪花模式是星型模式的变种,将一个或多个维表分解成多个表,每个表都有连接到主维度表而不是事实数据表的相关性维度表。
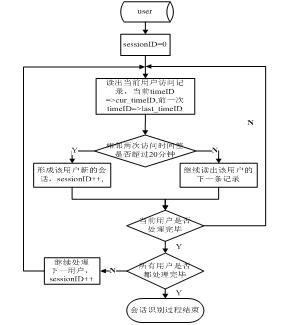
图5 会话识别流程图
根据分析主题的需要,Web日志数据仓库采用常用的星型模式,在SQL Sever 2000提供的Analysis Services平台下实现。结果如图6,它包括一个大的事实表和一组小的维表,事实表为FactTbl表,维度表为UserTbl、TimeTbl、PathTbl 以及ProtocolTbl,其中FactTbl表是由关系数据库中IDTbl表转换而来。
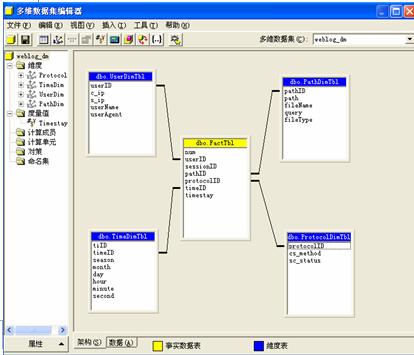
图6 Web日志数据仓库多维逻辑模型
在关系数据库中对IDTbl表进行聚集计算,可得到用户一次会话中每个页面的停留时间timestay,并通过离散化技术将timestay属性转化为每一页面的平均访问次数,定义为visit属性。关于这一过程,Cooley等在文献 [5] 中给出了详细步骤。将这两个属性及IDTbl表其它属性一起添加到FactTbl表,即形成了数据仓库的事实表,其中timestay和visit作为事实表的度量值,即希望在数据仓库中能查看并可以预测的数据。
6、结论
综上所述,实现一个Web日志数据仓库原型系统有两个关键点:预处理和逻辑建模。本文在解析Web日志时采取的一些预处理方法事实证明收到了良好的效果,可比较精确地识别用户及会话;在进行逻辑建模时采用星型逻辑模型,运用大量的冗余维度数据进行设计,大大提高了信息的检索性能。同时,文章实现了一个数据仓库原型系统,该系统简单实用,对原始的Web日志信息进行了维度上的分类,便于从特定时间段、特定用户等角度来实现对Web日志数据的进一步挖掘文章编辑。
该系统尚存在一些不足之处,还有很多地方需要改进。例如在预处理阶段可以考虑将Web 页面结构和 Web 日志结合起来构造用户访问会话,减小会话集中出现的错误,使得模式发现阶段的结果更加准确和可信。并且可以将单纯的Web日志与其他用户信息数据结合分析,这样可以更好地发现用户行为模式。
投稿人所留网址:www.jeep521.com