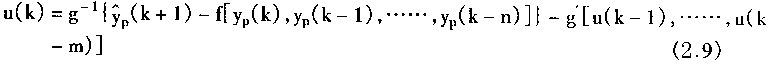[ע����վ���ص�ijЩ���²���������վ֧�ֻ���۵��϶�����ʵ��]
| ��һƪ ��������
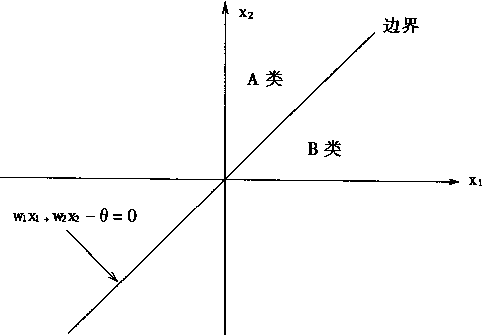
һ������
��������ԭ���о�
����������ͷֲ�ϵͳ
�ڶ�ƪ ϵͳģ��
ǰ��
��һ�� ����������ģ��
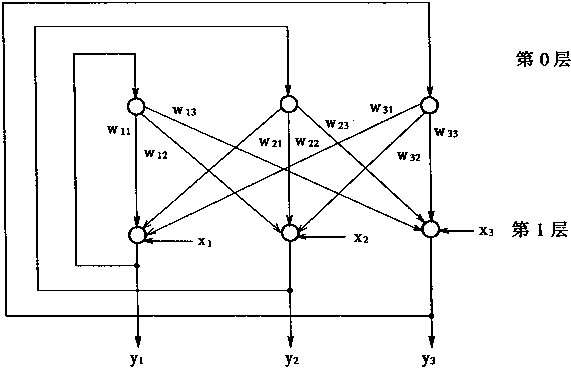
1��1 ������Ļ��������ͽṹ
1��2 ����BPģ��
1��3 Hopfieldģ��
1��4 ����Ӧ��������ARTģ��
1��5 Kohonenģ��
�ڶ��� ���������
2��1 ���������ϵͳ�Ľṹ
2��2 �������������ѧϰ
2��3 ���������ϵͳ
������ ģ��������
3��1 ģ�����������ͽṹ
3.2 �Ŵ��㷨
3��3 ģ���������ѧϰ
������ ��ģ������
4��1 ��ģ��������
4��2��ģ������ϵͳ
| ����������ϵͳ |
|
|
��һƪ ��������
һ�� ����
��������ԭ���о�
2-1.�����ṹ
�˹�����������ϵͳԴ�����������硣�˽��������������ɺ�ԭ���������ڶ��˹�����������⡣
2-1-1.��Ԫ
��������ʶ����������١��о��������˵���ʶ��˼ά����Ϊ���Եĸ����ܶ��������������ء���ѧ��ʼ���ϸ�����ĩ��1875�����������ѧ��C.Golgi��Ⱦɫ�巨����ʶ���������ϸ����1889��Caial��������Ԫѧ˵��ָ������ϵͳ���ɽṹ����Զ�������ϸ�����ɣ��������ʮ�������о������Ϊ���Ե���ԪЧ��Ϊ1013��ÿ����Ԫ���������¼����ṹ���ԣ�
2-1-1-1. ϸ����(Cell Body)�����С��5��100��ֱ�����ȡ�ϸ������ϸ���ˣ�ϸ���ʺ�ϸ��Ĥ��ɡ�
2-1-1-2. ��ͻ(Axon)����ϸ����������ϸ��������һ����֧��������ά���൱��ϸ���������ÿ����Ԫֻ��һ����
2-1-1-3. ��ͻ(Ҳ��֦����Dendrites)����ϸ�����������������϶̵���״��֧���൱��ϸ�������롣
2-1-1-4. ͻ��(Synaptic)������Ԫ֮�����ӵĽӿڡ���������ͻ������Ŀ��Լ��1014һ1015֮�䣬ͨ��ͻ�����������ӷ�ʽ��ͬ������������Ҳ��ͬ��ͻ������Ϣ�������Կɱ䣬���ϸ��֮�������ǿ�ȿɱ䣬����һ���������ӣ�Ҳ��Ϊ��Ԫ�ṹ�Ŀ����ԡ�
���⣬�о���������Ԫϸ��Ĥ����֮����ڵ�λ���ΪĤ��λ��Ĥ��Ϊ����Ĥ��Ϊ�������СԼΪ��ʮ����Ĥ��ѹ������������Ԫ�������λ�������½�����ת��嶯��ʱ�����Ͻ����ʹĤ��λ���������ҵ���������������λ����ֵʱ��ϸ�������˷�״̬�������嶯������ͻ�����������̳�Ϊ�˷ܡ�������ֵ��λԼΪ40��13����ij嶯ʱ�����Ͻ��ʹĤ��ѹ�½������ڶ�����ѹ����ֵʱ��ϸ����������״̬�����嶯�����
2-1-2.��Ϣ����
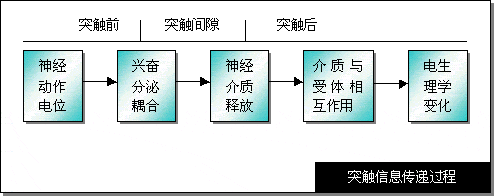
ͻ������ϸ���䴫����Ϣ�Ľṹ��ͻ���������ֹ��ɣ���ͻ��ǰ�ɷ֣�ͻ����϶��ͻ����ɷ֡�ͻ�������ݵ���Ϣ���õ紫�ݺͻ�ѧ�������ַ�ʽ��ͻ��ǰ�ɷ�����ĩ����һ���ػ��˵IJ��֡�ͻ��ĩ���γ��������ε�С�塣С����ֱ�ӽ���ͻ�����Ӳ��ֵ���Ĥ����ͻ��ǰĤ��С��ԭ���к��д�����ͻ��С�ݣ�С�ݵ�ֱ��ԼΪ200--800�����ں����ʡ�ͻ��ǰĤ������ͻ����϶����ͻ��ǰ��֮���һ�����������Ϊ100-500����ͻ����϶��Һ����ϸ����Һ������ͨ�ģ���˾�����ͬ��������ɡ�ͻ����ϸ����һ����ͻ����Ĥ������ͻ����ϸ����Ĥ�ػ��������д���ķ������塣ͻ���Ľṹʾͼ��ͻ����Ϣ���ݹ��̡� |
|
|
|
�ߵȶ�����ϵͳ�У�ͻ��ǰ�ĵ���ֱ������ͻ����ɷֵĻ�������ڵ�ѧ������ͻ������һ��ͨ������Ļ�ѧ�����н飬�������ʽ������ʻ���ʣ�ͻ������Ϣ����ֻ����ͻ��ǰ��ͻ�������ڷ����Ļ��ơ����ͻ�������ǵ�����ġ��˷�һ���������������ͷźͽ����ڼ�϶����ɢֱ��ͻ����Ĥ��ȥ����Լ��o��5-1���룬�����ͻ�ӳ١����缫�����о�����ǰ��ϸ����ģ��λ������ͻ�����λ�ķ�Ӧ����ͻ����Ϊ���֣��˷���ͻ����������ͻ������ĩ���ͷŽ���ʹͻ����Ĥ����������Ӧ�����˷���ͻ�����λ�������˷���ͻ��������ͷŽ���ʹͻ����Ĥ������������Ӧ����������ͻ�����λ������������ͻ������������˷ܵ�ϸ��֮�䷢�ֵ�ѧ����������֤������϶��������̬�ϴ���������������ѧͻ���ܹ��ṩ����Ĵ������ʣ�������ϸ��������������á�
�����о�Ҳ������������ĸ��Ӷ����ԣ�����������Ԫ��ͻ������������Ϸ�ʽ���Ӻ���ϵ�㷺��������ͻ�����ݻ����У��ͷ�������ʵ��ͻ�����ݻ��Ƶ����Ļ��ڣ���ͬ���������Ų�ͬ���������ʺ��ص㡣������ά�������������ܷ���������Ҫ�����ã�ͨ�����ź�-��ѧ��Ӧ�ź�ϵͳ��������Ϣ�����и��ӵ���Ϣ�ӹ���ʵ�ֶԻ���ĵ��ڿ��ơ�
2-2. ����֯
��Ԫ������ά���ɵ�����֯�������ֻ������ԣ����˷��봫��������Ԫ��ijһ�����ܵ�ij�ִ̼�ʱ�����ܴ̼��IJ�λ�Ͳ����˷ܡ������˷ܻ�������Ԫ��ɢ����������һ����������ͨ��ͻ�����ﵽ��������ϸ��������ά��һ�����˷�����ʱ������λ������ı仯�������������������о����˷�״̬�ı�־����λ�ı仯�dz�Ѹ���Ҷ��ݣ��������ε�λ�����˷ܵĽ�������嶯���嶯���������ݵ�һ�ַ�ʽ��ͨ����һ������ά����һ���ʶȵĴ̼�ʱ������һ���嶯��������һ���������д̼�ʱ���������������άͬʱ�嶯���̼�Խǿ�������嶯������άԽ�࣬��֮��Ȼ��ʵ��������嶯�������������Դ̼�����������ά���������ġ��̼�����������������ά�����嶯��
����������˵������硢�ڽ绷���̼��£�ͨ����ϵͳ������Դ̼����������Իش��ⲿ���ڲ��̼��������ڸ������������嶯���嶯���Ŵ������ﵽ�����ࡣͨ�����������ϵ���پ��������ﵽЧӦ���٣�����Ӧ�������һ�������ķ�����̡����������Ļ����ṹ����и������������������࣬������ЧӦ����������һ��������֯ĩ�ҵ�����ṹ�����Ѵ̼�������ת��Ϊ���˷ܹ��̣����Ը�������һ�ֻ���װ�á�
ijһ�ض��ķ����������ڴ̼��ض��ĸ�����������ģ����ض����������ڵIJ�λ��Ϊ����������ĸ���Ұ����������ָ����ijһ�ض��������ܵ���ϸ��Ⱥ��������Ļ����ͨ������άֱ��Ӱ��ЧӦ������ijЩ����£�Ҳ����ͨ����Һ�ĵ�·���Ӱ��ЧӦ����������Һ���ھ���ָ�ڷ����ٵĵ��ڡ���ʱ�����ǰ��������������������ࡢ�������ڷ����١�������ѪҺ��ת�ˡ�ЧӦ�������Ĺ��̽��С�
������Է�Ϊ���֣�������������������䡣�����������������Եģ�һ���̼�������һ���ĸ���Ұʱ��������һ���ķ��䡣���磬ʳ�����������Һ���ڷ��䣬��е�̼���Ĥ����գ�۷���ȡ�����������ʹ�����ܳ�����Ӧ�����������������ڻ�����������γɵģ����������Ż�����ⲿ�������ڲ�״���ı仯���仯����������Ľ��������չ�˻���ķ�Ӧ��Χ���������������и����Ԥ���Ժ�����ԣ�����Ӧ�ڸ��ӱ仯�����滷������ʵ�ʻ�У��������������������Ļ�������Ե����壬�����ÿһ������������ַ�������ʡ��ڼ����ڡ�����������ֻ��������ʱ���֣������Ժ������������䲻�Ͻ������������������������Խ��Խ���ɷָ���ں���һ��ÿ��������������֣���������������룬������������������������������Ļ����Ͻ����ģ����Ĺ����Ѿ���ijЩ����������ijɷְ����˽�ȥ�����ԣ��������е��������ܶ�������������������������л�ͳһ��
2-3. �Ӿ���
�����˽��������ⲿ��Ϣ������Ҫ�Ľ������٣�����Ϊ���ӵĸй����١��������Ĺ����������У��۽���������Ĥ�ϳ�������Ĥ�����嶯�ﵽ����Ƥ�������������Ӿ������۵ļ�Ҫˮƽ������ͼ��ʾ����Ĥ�뾧״��֮����ǰ������Ĥ�뾧״��֮���Ǻ�ǰ������֮�䶼����Һ��з�ˮ����״��ĺ�ֱ������Ĥ�������Ľ�״���ʣ��в����塣��Ĥ����ˮ�뾧״��ȹ����۹�ϵͳ������������֯���ܰ������γ�������Ĥ�ϡ������еĸй�ϵͳ�У�����Ĥ�Ľṹ��ӡ�����ĤΪ�й�ϵͳ���ܸ��ܹ�Ĵ̼��������嶯����������һ����Ԫ(�й�ϸ��)�����ж�����Ԫ(˫��ϸ��)����������(��ϸ��)��
�й�ϸ�������֣��Ӹ˺���ϸ�������߶���˫��ϸ���γ�ͻ����ϵ��˫��ϸ��������Ӹ�ϸ������ϸ���������ڶ�����ϸ����ӡ��й�ϸ���ķֲ��Dz����ȵģ���ϸ���ֲ�������Ĥ�����밼���֡�ǰ�Ӹ�ϸ����ֲ�������Ĥ�ıȽϱ�Ե���֡���������ĵط�û�и���ϸ�����γ�ä�㡣�Ӹ�ϸ�����ص��Ƕ������и߶ȵĸ����ԣ������ҹ�Ӿ������١���ϸ���Թ��ǿ���н����ĸ����ԣ���������Ӿ������١��Ӹ�ϸ���к���ҹ�Ӿ�����������Ϻ��ʡ���ϸ���к������Ӿ�������������ʡ���ϸ�����Ը��ܺͷֱ���ɫ��
�������ɳɼ�����ϸ������ͻ��ɣ�������������������´���ǰ����ϳ��ӽ��档���������ÿһ����������ά���ڽ�һ�������Բ�֮ǰ�����·��顣���������ٷ������������������������·���ʱ��������������Ĥ�Ҳ����ά�ϳ�һ�������Ե��Ұ벿��������������Ĥ������ά�ϳ���һ�������Ե���벿(��ͼ��ʾ)��
�����������������ά�Ӽ������������н�������ֹ�����Ե��������ֳ����ϥ״����ˡ��������ϸ����Ҫ�����࣬Ͷ��ϸ�����м���Ԫ����ϥ�����������Ϣ�����ϵĵ�һ�η��룬Ȼ���͵����Եĵ�һ�����͵ڶ���������ϥ�������ԣ����۵���Ƥ����м�վ��������Ӿ�ͨ·������Ĥ�ϵĹ����ϸ��ͨ���⻯ѧ��Ӧ�����ﻯѧ��Ӧ���������������λ�������壬������Ĥ���ش�ֱ��ˮƽ����������Ϣ����������Ϣ�����Ӿ�ͨ·���д������Ӿ��źŰ�����������мӹ���������ÿһˮƽ��ת�������ϡ�������Ұ��������Ա���Ƶķ�����������Ԫ�ĸ���Ұ��ָ��Ӱ��ijһ����Ԫ��Ӧ������Ĥ����Ұ������ÿ����Ƥ�㣬���ϥ״�����Ԫ������Ĥ��ϸ����ϸ��������Ĥ�Ͼ������ض��ĸ���Ұ������Ĥ����ϸ���ĸ���Ұ����ͬ��Բ���ɷ�Ϊ������Բ�ͺͱ�����Բ�����ࡣ���ϥ״�����Ԫ�ĸ���Ұ��������ϸ�����ơ�Ƥ�����ĸ���Ұ���ٿɷ�Ϊ�������ͣ����͡������͡��������͡� |
 |
|
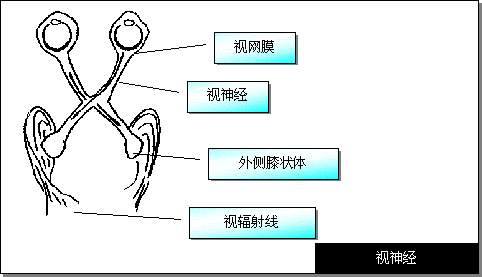
HubeL��WieseI��1962�������һ����ϵĸ���Ұģʽ��������ͬ����Ұ |
 |
|
����Ƥ����Ԫ�ڴ�ֱ��Ƥ������ķ����ϳ�ס״�ֲ�����������Ƥ��Ļ������ܵ�λ����Ϊ�����������ڵ���Ԫ��ͬһ����Ұ��ͼ��;���ĸ��ֳ������в��еĴ��������룬�Dz������۸�֪������Ҫ���������ڴ���ֹ�����ֳ�סģ�ͼ��������ۣ�������ȡ���ۺͿռ�Ƶ�ʷ��������ۡ��Ӿ�������ȡ������Ϊ���Ӿ��ϲ�ij����������ͬ��������ȡ����������ɡ�ÿ�ֹ���У�ڵ�ϸ����������Ұ��ͬ���书��Ҳ��ͬ�����ݹ��ܲ�ͬ���Է�Ϊ��λ��������������ɫ���ȡ�������������ȡ�ij���ģ�Ͳ�ͬ���Ӿ��ռ�Ƶ�ʷ���������������Ϊ����Ƥ�����Ԫ�����ڸ���Ҷ��������ÿ����Ԫ���еĿռ�Ƶ�ʲ�ͬ���������о�����������Ը���ͼ�ε���֪��������������ȡ���ְ����ռ䰴�ռ�Ƶ�ʷ�����������̡����⣮��Ƥ�������Ƥ��������ҲЭͬ���
MHter��Stryker�ܽ�����������������ѧ�о��ɹ�֮��������������ģ�͡�������Ϊ��Ƥ���Բ������γ���Ԫ�����ԵĻ�������Բ����ͳ��ѧ�������������γɵĻ�����ÿֻ����̼��������Ƥ����Ԫ��λ����ģʽ������ԣ�������ͬʱ�Դ���̼�����ķ��Ų��죬�ڷ�����У�γ��о��и�������ã���������̼������ͻ��ǰ�ģʽ����Ҫ�ģ�ͻ�����Ƥ����Ԫ��Ӧģʽ�ڷ�����У��Ҳ����Ҫ�ġ���Щ�����������Hebbͻ�����۹۵㡣
2-4. �Լ�����������
������ѧ��һֱ�ڴ������ںδ��Լ���μ�����о����о��������������ϸ�����ܶ��ij������Ĵ̼������������˷�״̬ʱ��ֻ�е����ִ̼��ﵽһ��ǿ��(��ֵ)֮����ϸ����Ż����ºۼ������ҵ��������̼���Ƶ�����ʱ����ֵ���ͣ���������ι̡�
���ԵĴ�����ϸ�����Է���Ͳ�����嶯����Ϊ�;����������ס���Щϸ��֮���Զ��ַ�ʽ�������á���̬������������ɣ����1982����ģ��������˼����������֯�ģ������������ӹ�ȥ�����л�����ܶ��Զ��ı�������ġ���֤ʵ��ȥ�ľ���ʧ�ܾʹ洢�µľ��飬���ɾ�����ѧϰ�������뼰�������й��ɵķ����ı�ṹ����ӦԤ���ʧ�ܡ���̬���������������е��嶯�����������ڿ������ظ�����ij嶯��ǿ������Ԫ��ijЩ��Ծ�Ĵ�л�仯�͵�λ�仯�ı��֡�ͨ����ϵ��Ԫ�ķ�ջ�(���嶯)���������ֶ�̬������ƣ�ÿ��������Ŀ�������ض�����Ԫ�������Ļ����ʵ�����ǵļ�����������Ԫ�࣬��ˣ���ͬ�ļ�����ܹ��ò���ͨ·������嶯ʵ����û�����³�ʱ�����ĺۼ�����ô�һ��ֹͣ���������ȫ�أ����ɸı����ʧ����
���⣬ʵ��֤�����䲻�Ǵ���̬�ġ������Ⲣ���ų��������Ԫ�������ԡ��嶯�����б�Ȼ�������������¼���ۼ�����������С��ظ���ɸ��õļ�����һ��ʵ�������ǣ��嶯Ϊ���Ժ����³־õ����ʱ仯��������ѡ���ĵ�·��ѭ����������ʵ�Ϲ��̼���ۼ���ȷ��Ҫʱ����Ϊ���ۡ�ѧϰ���Ʊ�����ͻ���ṹ�ı仯�����������ʵı仯�������ֳ־õľ�̬�ۼ�����ô��Ԫԭ���������ã����ڻ�����ܱ�������ò����������á���Ȼ�Ǽ���ʹ���һ������λ�õ����⡣
����Ԫ����ѧ�У������о���õķ����Ƕ����Խ��оֲ��ƻ����۲�����ϰ��������ʵ����������뺣�������еĹ�ϵ������������йص��������塣������Ѹо������źŻ�۳�ͬ��-Щ���֣��ְ�����ά������ͽ�����С�������²���������Ķ�����ϵ����Ϊ��Ϊ����Ϊ�������Ķ������õĻ�������Ƥ�ʸо�ϵͳ����һ����վ��������ά���������塣�о�ӡ����������������ϵͳ��һ����·�������������������֮�����ϵ�������������֮�����ϵ��������������²�֮���Ŧ���ƺ�������-�����������ͨ·�Ӻ���������ЩŦ��ͨ������������嵽�о�ͨ·֮��ķ�����ϵ��Ҳ���Ա����Ӱ��ѧϰ���������巵�ص��о�������ϵ�Ĵ��ڣ��п��ܽ���һ����һ�Ĵ̼����������ֶ����ļ��䡣�統�ᵽһ����Ϥ��ʳ�����ζʱ�ܻ����������ۡ��ʵغ�ζ�����䡣
�ܵ���˵��������Ҫ�ļ����·�ֱ���Դ�ں����������壬���Ǹ�����������֪ѧϰ������֮�⣬����������ѧϰ�ĵڶ�ϵͳ�����ƴ̼���Ӧ�Ǹ�ϵͳ�еĹؼ����֣����dz�����ѧϰ����Ϊϰ�ߡ�ϰ���Ǵ̼��ͷ�Ӧ������ʶ�Ӻϡ���Ϊ��������ѧ�����֤�����ֽӺ�������ѧϰ�Ļ�������Ϊ����۵����ų���ͨ�������е�"����"��"��֪"���Լ�"����"����һЩ���ѧϰ��������������ȫ��ͬ��ϵͳ������֮һԴ����֪��ϰ�ߣ���һ��������֪����Ļ����������Ϳɵ�����Ϊ�������֪����ѧ�ɣ���Ϊ�Ϳ����ǶԴ̼�������ʶ��Ӧ������֪��������ָ������Ϊ�ĽӺ��塣
���� ������ͷֲ�ϵͳ
3-1. �ֲ�ϵͳ
3-1-1. ����
�ֲ�ϵͳ����������Χ���ڵ���Ϊ�ձ��ϵͳ���ֲ�ϵͳ��Ƿֲ�ϵͳ�����Žϴ�IJ��졣�Ƿֲ�ϵͳ������һ��ͳһ�����ָ�ӣ���һ�����з�������Ļ�������֮�෴���ֲ�ϵ ͳ�ж����������Ļ������ʶ���֮Ϊ�ֲ��ġ���Ȼ�ֲ�ϵͳӦ�ð����첽��һ�㺬�壬��Ȼ û��ͳһ��ָ�ӻ�����Ȼ����Ϊ��ͬ�������⣬���ڷֲ�ϵͳ�����ڴ�����ϵͳΪ��ȫ���� ���Ӻ���Ͽ�������ģ������۶����ϴ���������ԣ���ʵ��������ϵͳ����Э������ �⣬�ֲ�ϵͳ�е�ÿ��Ҫ���������Э�����ڸ�����Լ����Ϊ���屣��һ��������Ӧ���� �䶯�����ѧ�еĺܶ�������һ�����༯���ڲ�������֮�䡢����֮�䣬���������ˣ��������� Ȼ֮��ȵ��ձ������������
3-1-2. ϵͳ���ص㣺
3-1-2-1. �ֲ���
�ֲ��������ڣ�ϵͳ�ɶ����������Ҫ�ع��ɡ�����������Ҫ�ؿ����Ǽ�Ҫ�أ�Ҳ��������ϵͳ��������ij�������ľ���Ȩ����
3-1-2-2. �䶯��
�ͷֲ�ϵͳ�������ԣ����䲻ȷ���ԣ���ϵͳ���ǹ̶����䡣�ڴˣ�ϵͳ����ij�̶ֳȵ������ԡ�ģ���ԡ��첽�ԣ���Ҫ��֮��ͨ������á��ͨ�ŴﵽЭ��������
3-1-2-3. ����֯
�ֲ�ϵͳ����Ӧ�����ı仯��������֯����һ�ֹ��ɻ��������ﵽijһĿ�ġ�����֯������Ӧ�������ơ�����Ӧ��ͨ������֯(���ع�)ʵ�ֵġ�ϵͳ������֯�����в��ϵش���绷������ȡ��Ϣ�����ϵ�������֯������
3-1-2-4. ������ֲ�����
"����"�ĺ�����ָ��һ��ͳһ��������ϵ������ϵͳ�������ڴ����Ƕ���һ�����Լ���չ�������һ��ϵͳ���ж�����塢����Ҫ�ػ���ϵͳ������ִ��һ����������������ڿ�Ч������ִ��ͳһ������ͬ������Ҳʹ��"����"������"�ֲ�"��"����"ǡ����ԣ�������е�Ҫ�ؽ��ܲ�ͬ�ġ���������Ϣ�����в�ͬ�Ķ��������dz�֮Ϊ"��ȫ"�ķֲ�ϵͳ������һ��ķֲ�ϵͳ���ԣ�������������"����"��"��ȫ"�ֲ�ϵͳ֮�䣬���ڷֲ�ϵͳ��ijЩҪ�ؽ��ܲ�ͬ�ġ���������Ϣ�����в�ͬ�Ķ�����������һЩҪ�ؿ�����һ��������ͬ��ͳһ��������ϵ�����½��ж�����ǡ��ѡ��ֲ�ϵͳ�������ʽ������ʹϵͳ�Ĺ��ܿ��Դﵽijһ�����յĻ�ʵ��ijһ����
3-1-2-5. �����
�о��ֲ�ϵͳʱ����ע��ÿ��Ҫ�ص��۶�������ͬ������ѧ�о��в�����ÿ��������ӵ�״̬һ��������������۲������ȫ�����ں�۲���Ͽ����Ǿ��ȵġ��ڷֲ�ϵͳ�о���������ϵͳ����ĺ�۶���������Ȼ���ۺͺ������Եĸ��
3-2. �˹�������
3-2-1. ����
�˹���������80������ڵõ��˷��ٵķ�չ��1982������������������ѧԺ����ѧ��Hopfield���������Hopfield�˹�������ģ�ͣ��������������ĸ��������˹������磬���������ȶ��Ե��оݣ��������˹��������������������Ż��������;����
�˹�������ģ�����ಿ������˼ά����������ģ���˹����ܵ�һ��;�����ر��ǿ��������˹����������˹������о�����������һЩ���⡣�˹����������۵�Ӧ���Ѿ�������������ڼ�����Ӿ���ģʽʶ�����ܿ��ơ��������Ż�������Ӧ�˲�����Ϣ�����������˵ȷ���ȡ���˿�ϲ�Ľ�չ��
�˹�������ģ�ͷ�չ���������а�����ģ�ͣ�����ķ���Ҳ�Ƕ��ֶ������г���������ѧ�ģ���ѧ�����ģ�ģ���Լ����緽���������й��������ṹ�Ƚ��ʺ�����ϰ�ߵļ����������������������˽ṹ�Ĺ����ԣ�������ϵͳ�������Ժ������˶���������Բ��÷�Ч��ѧ�����������������ǰ�����˽ṹ���˹������磬��ʹ�ø�֪���㷨���������㷨������ѧϰ�㷨�ȡ�������ˣ������˹�������ӱ����������˷ֲ�ϵͳ�Ļ������ʣ����Էֲ�ϵͳ�����ۺͷ������ʺ��˹���������о���
3-2-2. �˹����������Ϣ����ԭ��
�˹����������ɴ�����Ϊ������Ԫ������Ҫ���Լ���Щ����Ҫ��������γɵ����硣�����ڶ���������ѧ�о��Ļ���֮�ϣ�����һ���ij�����ģ����˹���Ϣ����ģ�͡�����ӳ�����Թ��ܵ�ijЩ�������ԣ����ֲ������Ե���ʵд�գ�����-�����и߶ȷ����ԵĴ��ģ�����Զ���ѧϵͳ������ָ�����˹���������Բ����κ���������Ե�����������������ԡ��˹�������ϵͳ�������ܣ�
3-2-2-1. ѧϰ������ͨ��ʵ������ѧϰ��
3-2-2-2. ����Ӧ������ϵͳ����Ӧ���ı仯�������õ����ܣ�
3-2-2-3. ����֯�����������ⲿ�����ı仯��������֯������Ӧ��ͨ������֯ʵ�ֵģ�
3-2-2-4. �ݴ��������������Բ���������Ϣ������ȷ�Ľ�𣬻���ϵͳ�ڲ�����ijЩ����ʱ���ܴﵽ���õ�״̬��
3-2-2-5. �������������
3-2-2-6. ֪ʶ��ʾ������
3-2-2-7. ģʽ�洢������������
����ѧ�ĽǶȿ��Թ���Ϊ���¼����������ԣ�
a) �����ԣ��˹���Ԫ���Ա���Ϊ������������ֻ���״̬�������һ�ַ����Թ�ϵ��
b) �Ǿ����ԣ��˹�������ϵͳ�����˹���Ԫ֮�������ñ�����Ϣ�Ĵ����ʹ洢���ˡ�ϵͳ��������Ϊ����ȡ���ڵ�����Ԫ��״̬������ȡ��������֮�������ã��ô���ģ����ԵķǾ����ԡ�
c) ���ԣ�������ָ�˹���������ݻ�����������һ��������ȡ����ij�ض����������Ҹú������ж���ȶ��㣬�⽫�����ڲ�ͬ�߽������µõ���ͬ�Ľ���������ϵͳ�ݱ�Ķ����ԡ�
d) �Ƕ����ԣ��������˹��������������֯������Ӧ����ѧϰ������
�ڷֲ�ϵͳ���мٶ��˷ֲ�ϵͳ�еĴ���������Ԫ��������Ҫ�أ�����ͨ������Ҫ�ؼ�����������������������Ϣ��������������Ҫ�صĴ������������Ƿdz����ӣ�Ҳ�����쳣����Զ��ԣ����˹�������ģ���У�һ�������Ԫ��һ���dz��Ĵ�����Ԫ��ÿ����Ԫ��������Ԫ�����˷��Ի��������źš���Ԫ��ʾ���ܴ��ڵļ��裬��Ԫ֮�����������ʾ��Ԫ֮����ڵ�Լ������Щ��Ԫ���ȶ�����ģʽ��������Ľ⡣
3-3. ��ҵ����������
��ҵ������ϵͳ���˹�������ϵͳ����ҵ�����ϵ�һ��Ӧ��ϵͳ��������ϵͳͨ������Ԫ�Լ���ϵͳ��ģ�£�ȷ��ϵͳģ�ͣ������ҵ����Ϣ���ݻ��ƺ��������⡣ϵͳ����ǿ����Ϣȷ�����ݼ�ʱ�����������ҵ���ݽ�����˫���ԡ������Ժ�������Ϣ�ĸ����ԣ�������ϵͳ������ģ����һ���ۺϵ�������ģ�͡����ݲ�ͬ��һЩ��������÷��������硢����֯������ģ�͡�
����������ģ�ͣ����þ����Hopfield����ģ�͡��ڷ����������У��������ݾ�������ϵͳ�ij�ʼ״̬��Ȼ��ϵͳ����һϵ��״̬ת�ƺ���������ƽ��״̬��������ƽ����̬���Ƿ��������羭�������������� Hopfield������������Դ����Ż����⡣
����֯����ģ��(Self-organizing Neural NetWork)��Kohonen������֯����ӳ��������(seIf-organizing Feature Map)������֯��������һ����ʦѧϰ�����磬����ģ��������ݹ�ȥ�����Զ���Ӧ��Ԥ��Ļ����仯�� |
|
ǰ�� |
|
�����硢ģ�����ͽ����������˹�����Ŀǰ���µ����ۻ������ڹ������ܵ����ǵĸ߶ȹ�עiҲ�����ڸ���ѧ���������о���ǰ�ؿ��⡣���Ƕ������������۵���Ȥ��������ʮ���ǵ�ʱ�֣����������������أ����������������˹����ܵ�ʵ�ֹ���������ʮ����Ҫ��Ӧ�ü�ֵ������ѧ�߲�Լ��ͬ����Ϊ��δ�����õ�ǰ�غ��ļ�������ģ�������������ϵ��¼���������ģ��������
�������ǻ���������������ʵĻ����ϵģ������������������紫�ݡ�������Ϣ���۹��̡����ң���ͼ�������۹�����ģ���˵����ܣ�̽���˵��ǻ��γɡ�������ʽ��
ģ�������������ģ��˼ά��һ��������ϣ���������������ģ��˼ά�ķ�ʽ��������صĺ�۹��̡�ͬʱ�������������۹����о����˵�������̬���Լ�ģ���˵��������á�
ģ������������������������ģ���ˣ�����Ϊֱ�ۣ�Ҳ����Ϊ�������⡣ģ����ѧΪģ�������о��Ϳ����ṩ����ѧ��������ģ����ȥ�о��˵�������һ����Ҫ��;����ģ��������ģ����Ӧ�������㷺��һ����������ģ����������һ�ַ����Եİ�����������ƻ��������������������Ŀ��ƹ������̻��ģ����ԣ�������������������˼ά����������ģ�����ƿ�����һ�����ܿ�����ʮ��ǡ���ġ�ģ������Ҳ����һ��ȱ�ݣ������û��һ�����õ�ѧϰ�ܹ��ͷ����������ҪѰ����Ӧ�IJ��Ȱ취�� |
|
��һ�� ����������ģ�� |
|
ģ������ʵ�����������ѧ������������������������ϰ���˰������˹�������ֱ�ӳ�Ϊ�����硣��������ϵͳ��ʶ��ģʽʶ�����ܿ��Ƶ��������Ź㷺�������˵�ǰ�����ر������ܿ����У����Ƕ����������ѧϰ�����������Ȥ�����Ұ���������һ��Ҫ�ص㿴���ǽ���Զ������а�������Ӧ�����������Ĺؼ�Կ��֮һ��
������Ļ���������Ԫ��
��Ԫ����������ϵͳ����ϸ��Ϊ����������ģ�͡������Ƕ�������ϵͳ�����о�����̽���˹����ܵĻ���ʱ������Ԫ��ѧ�����Ӷ���������Ԫ��ѧģ�͡�
��������ʽ��ͬ����Ԫ�����ڡ��������������硣��������һ���߶ȷ����Զ���ѧϵͳ����Ȼ��ÿ����Ԫ�Ľṹ���ܶ������ӣ�����������Ķ�̬��Ϊ����ʮ�ָ��ӵģ���ˣ�����������Ա���ʵ����������ĸ�������
������ģ��������Ԫ����ѧģ��Ϊ������ӵ���ġ�������ģ�����������ˣ��ڵ��ص��ѧϰ��������ʾ������������ǵľ���������Ҫ�����м��㣺
1�����зֲ�������
2���߶�³���Ժ��ݴ�������
3���ֲ��洢��ѧϰ������
4���ܳ�ֱƽ����ӵķ����Թ�ϵ��
�ڿ���������о������У���ȷ����ϵͳ�Ŀ������ⳤ���������ǿ��������о�����������֮һ�������������һֱû�еõ���Ч�Ľ���������������ѧϰ������ʹ���ڶԲ�ȷ����ϵͳ�Ŀ��ƹ������Զ�ѧϰϵͳ�����ԣ��Ӷ��Զ���Ӧϵͳ��ʱ������Ա��죬����ﵽ��ϵͳ�����ſ��ƣ���Ȼ����һ��ʮ��������ĵ�����ͷ�����
�˹��������ģ����������ʮ��֮�࣬����һ���У���Ҫ����Ӧ�ý϶�ĵ��͵�������ģ�͡���Щģ�Ͱ���BP���硢Hopfield���硢ART�����Kohonen���硣 |
|
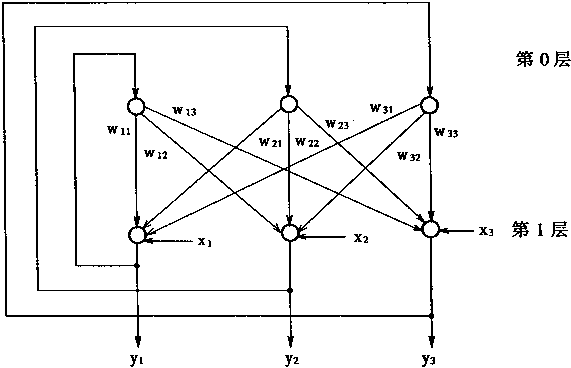
1.1 ������Ļ��������ͽṹ
������Ļ�����ɵ�Ԫ����Ԫ������ѧ�ϵ���Ԫģ���Ǻ�������ѧ�ϵ���ϸ����Ӧ�ġ�����˵���˹�����������������Ԫ���ֳ������ѧģ�������������������ϸ���ġ�
�����ԣ��������ϸ�������������۵������γɵ����ʻ�����ԴȪ����������Ԫ����ѧ�����ͱ�����������ϸ���Ŀ���Ϊ����Ϊ���ݡ���ˣ��˽�������ϸ������Ϊ���Ծ���һ��ʮ����Ҫ����������ˡ�
����������ӽṹҲ��������ѧ��������ϸ�������ķ�ʽΪ���ݵġ�����ϸ�����������Ľ�¶Ҳ��ʮ����Ҫ�ġ�
1��1��1 ��Ԫ������Ϊ����
��Ԫ�����������Ԫ�ء�ֻ���˽���Ԫ������ʶ������ı��ʡ�����һ�ڽ� ����Ԫ������ѧ�⸱����Ϣ�Ĵ����봫�ݷ�ʽ�����������Լ�����ѧģ�͡�
һ����Ԫ������ѧ����
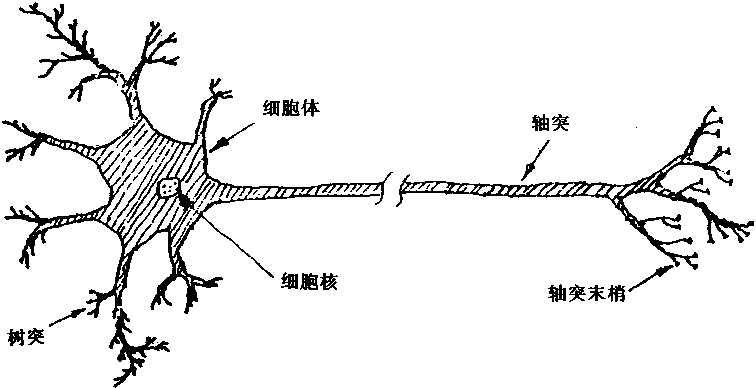
�������ڣ���Ԫ�Ľṹ��ʽ��������ȫ��ͬ�ģ����ǣ����۽ṹ��ʽ��Σ���Ԫ���� ��һЩ�����ijɷ���ɵġ���Ԫ������ѧ���ʿ�����ͼ1��1��ʾ�Ľṹ��ʾ����ͼ�� ���Կ�������Ԫ����ϸ���壬��ͻ����ͻ��������ɡ� |
 |
|
ͼ1-1 ��Ԫ�Ľ��� |
|
1��ϸ����
ϸ�������ɺܶ�����γɵ��ۺ��壬�ڲ�����һ��ϸ���ˡ������塢ԭ������״�ṹ�ȣ�������Ԫ���������Ӧ�أ�����������³´�л�ȸ����������̡���ԪҲ��������ϸ��������ϸ����������Ϊϸ��Ĥ��
2����ͻ
ϸ��������Ӳ��ֲ����ķ�֦��Ϊ��ͻ����ͻ�ǽ��ܴ�������Ԫ���˵���Ϣ����ڡ�
3����ͻ
ϸ����ͻ�����������״��ά��Ϊ��ͻ����ͻ��ɴ�1�����ϡ���ͻ�ǰ���Ԫ�˷ܵ���Ϣ������������Ԫ�ij��ڡ�
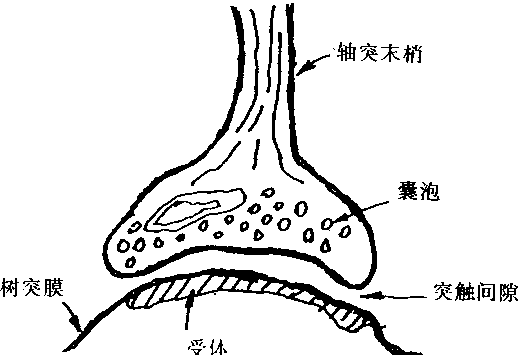
ͻ������һ����Ԫ����һ����Ԫ֮������ϵ��������Ϣ���͵Ľṹ��ͻ����ͼ1��2��ʾ������ͻ��ǰ�ɷ֣�ͻ����϶��ͻ����ɷ���ɡ�ͻ��ǰ�ɷ���һ������Ԫ����ͻĩ�ҡ�ͻ����϶��ͻ��ǰ�ɷ����ɷ�֮��ľ���ռ䣬��϶һ��Ϊ200��300Å��ͻ����ɷֿ�����ϸ���壬��ͻ����ͻ��ͻ���Ĵ���˵����������Ԫ��ϸ���ʲ���ֱ����ͨ�����߱˴���ϵ��ͨ��ͻ�����ֽṹ�ӿڵġ���ʱ��Ҳ��ͻ����������Ԫ֮������ӡ� |
|
|
|
ͼ1-2 ͻ���ṹ |
|
Ŀǰ������������ѧ���о����Ѿ�������Ԫ�����ʵ�ͻ�������в�ͬ��4����Ϊ����Ԫ��4��������Ϊ�У�
(1)�ܴ������ƻ��˷�״̬��
(2)�ܲ���������ƽ̨���������
(3)�ܲ������ƺ�ķ��壻
(4)������Ӧ�ԡ�
ͻ����4��������Ϊ�У�
(1)�ܽ�����Ϣ�ۺϣ�
(2)�ܲ������α仯�Ĵ��ͣ�
(3)�е�Ӵ��ͻ�ѧ�Ӵ��ȶ������ӷ�ʽ��
(4)�������ʱ������
Ŀǰ���˹���������о������Ƕ���Ԫ�ĵ�һ����Ϊ��ͻ���ĵ�һ����Ϊ����ģ�⣬������Ϊ��δ���ǡ����ԣ���������о�ֻ�Ǵ����ij����Σ�����д����Ĺ���������ȥ̽�ֺ��о���Ŀǰ����������о���������չʾ�������õ�ǰ����ֻҪ���β���ȡ�ý�չ����Ԫ��ͻ����������Ϊ����ȫ����ʵ���˹�ģ��ġ�
��.��Ԫ����Ϣ�����봫��
1����Ԫ���˷�������
�˹����������Ԫ���˷������ƽ���ģ�⣬�ʶ�����Ӧ�˽���Ԫ���˷�������״̬��
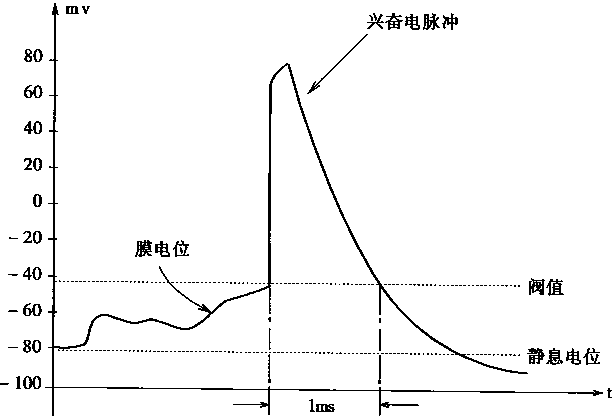
һ����Ԫ���˷ܺ���������״̬����ϸ��Ĥ����֮�䲻ͬ�ĵ�λ���������ġ�������״̬��ϸ��Ĥ����֮�����ڸ������ĵ�λ������λ���Լ��-50��-100mv֮�䡣���˷�״̬������������⸺���෴��λ���ʱ����ΪԼ60��100mv�ĵ����塣ϸ��Ĥ����ĵ�λ������Ĥ���������Ũ�Ȳ�ͬ���µġ�ϸ�����˷ܵ��������һ���ԼΪ1ms����Ԫ���˷ܹ��̵�λ�仯��ͼ1��3��ʾ�� |
|
|
|
ͼ1-3.��Ԫ���˷ܹ��̵�λ�仯 |
|
2����Ԫ����Ϣ���ݼ���ֵ����
����ϸ�Ե��о������������Ԫ�ĵ����弸�����Բ�˥����������ͻ���͵�������Ԫȥ��
����Ԫ�����ĵ������ź�ͨ����ͻ�����ȵ�����ͻĩ�ң���ʱ��ʹ���е����ݲ����仯�Ӷ��ͷ����ʣ���������ͨ��ͻ���ļ�϶�����뵽��һ����Ԫ����ͻ�С���ͻ�ϵ������ܹ��������ʴӶ�ȥ�ı�Ĥ�����ӵ�ͨ�ԣ�ʹĤ��������Ũ�Ȳ�����仯������ʹ��λ�����仯����Ȼ����Ϣ�ʹ�һ����Ԫ���͵���һ����Ԫ�С�
����Ԫ��������������Ԫ����Ϣʱ��Ĥ��λ�ڿ�ʼʱ�ǰ�ʱ�����������仯�ġ���Ĥ��λ�仯������һ����ֵʱ���Ų���ͻ�����������壬��������������ͻ���д��ݡ���Ԫ����Ĥ��λ�ߴ�һ����ֵ�Ų������崫�͵����ԳƷ�ֵ���ԡ�
���ַ�ֵ���Դ�ͼ1��3��Ҳ���Կ�����
��Ԫ����Ϣ���ݳ����з�ֵ����֮�⣬���������ص㡣һ���ǵ����Դ��ݣ���ֻ�ܴ�ǰһ����Ԫ����ͻĩ�Ҵ����һ����Ԫ����ͻ��ϸ���壬���ܷ�֮����һ������ʱ�Դ��ݣ���Ϣͨ��ͻ�����ݣ�ͨ�������0.5��1ms����ʱ��
3����Ԫ����Ϣ�ۺ�����
��Ԫ������������Ԫ����Ϣ��ʱ���ۺ����ԡ�
��������ṹ�ϣ�������ͬ����Ԫ����ͻĩ�ҿ��Ե���ͬһ����Ԫ����ͻ���γɴ���ͻ������Դ��ͬ��ͻ�����ͷŵ����ʶ����Զ�ͬһ����Ԫ��Ĥ��λ�仯�������á���ˣ�����ͻ�ϣ���Ԫ���ԶԲ�ͬ��Դ��������Ϣ�����ۺϡ��������Ԫ����Ϣ�Ŀռ��ۺ����ԡ�
��������ͬһ��ͻ������Ϣ����Ԫ���Զ��ڲ�ͬʱ�䴫�˵���Ϣ�����ۺϡ�����Ԫ����Ϣ��ʱ���ۺ����ԡ�
4����Ԫ��ͻ����D/A��A/D����
����Ԫ��ͻ�ϴ��ݵ���Ϣ�ǵȷ���������������ɢ�������źţ��ʶ���һ��������������ͻ�������ʵ��ͷź���ͻ��Ĥ��λ�ı仯�������ġ��ʶ�����ʱ˵��ͻ����D/A���ܡ�����Ԫ����ͻĤ��λ�߹�һ����ֵʱ�����ֱ�ɵ����巽ʽ����ͻ���ͳ�ȥ���ʶ����������˵����Ԫ��A/D���ܡ�
�����ԣ���Ϣͨ��һ����Ԫ����ʱ����Ԫ����Ϣִ����D/A��A/Dת�����̡�
�������֪����Ԫ����Ϣ�Ĵ����ʹ����з�ֵ��D/A��A/D���ۺϵ�һϵ�����Ժ��ܡ�
������Ԫ����ѧģ��
����Ԫ�����Ժ��ܿ���֪������Ԫ��һ�������뵥�������Ϣ������Ԫ�����ң�������Ϣ�Ĵ����Ƿ����Եġ�������Ԫ�����Ժ��ܣ�������Ԫ����Ϊһ������ѧģ�͡��������õ��˹���Ԫģ����ͼ1��4��ʾ�� |
|

|
|
ͼ1��4 ��Ԫ����ѧģ�� |
|
��ͼ1��4�У�X1��X2��������Xn����Ԫ�����룬��������ǰ��n����Ԫ����ͻ����ϢA��i��Ԫ����ֵ��Wi1��Wi2������Win�ֱ���i��Ԫ��X1��X2��������Xn��Ȩϵ����Ҳ��ͻ���Ĵ���Ч�ʣ�Yi��i��Ԫ�������f[��]�Ǽ���������������i��Ԫ�ܵ�����X1��X2��������Xn�Ĺ�ͬ�̼��ﵽ��ֵʱ�Ժ��ַ�ʽ�����
��ͼ1��4����Ԫģ�ͣ����Եõ���Ԫ����ѧģ�ͱ���ʽ��
 |
(1-1) | |
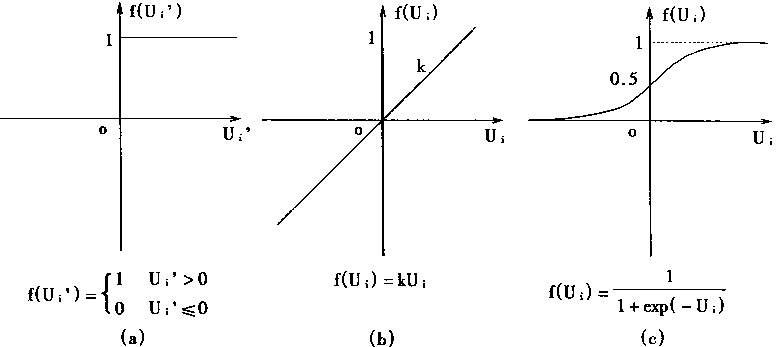 |
|
ͼ1-5.���ͼ������� |
|
���ڼ�������f[��]�ж�����ʽ������������н�Ծ�͡������ͺ�S��������ʽ����������ʽ��ͼ1��5��ʾ��
Ϊ�˱��﷽�㣻�
 |
(1-2) | |
|
��ʽ(1-1)��д����ʽ��
Yi=F[Ui] �� (1-3)
��Ȼ�����ڽ�Ծ�ͼ��������У�
|
(1-4) | |
|
���������ͼ����������У�
f(Ui)=Ku�� (1-5)
����S�ͼ����������У�
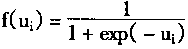 |
(1-6) | |
|
���ڽ�Ծ�ͼ�����������������ǵ�λ���壬�ʶ����ּ�����������Ԫ����ɢ���ģ�͡�
�������Լ������������������������ļ������������ȵģ���������Ԫ������������ģ�͡�
������s�ͼ�����������������Ƿ����Եģ���������Ԫ�Ʒ�����������ģ�͡�
����������������㷺Ӧ�ö�����������Ϥ����Ԫ��ѧģ�ͣ�Ҳ����ʷ�����Ԫģ�͡��������������������������۵ķ�չ�������˲�����ӱ����Ԫ��ѧģ�ͣ���Щģ�Ͱ�������Ԫģ�ͣ�ģ����Ԫģ�͵ȣ����ҽ���Ҳ�ܵ����ǵĹ�ע�����ӡ� |
|
1.1.2 ������ṹ������ |
|
��Ԫ��������Ĺ�ϵ��Ԫ��������Ĺ�ϵ����Ԫ�Ľṹ�ܼ���������Ҳ����£���������Ԫ��ɵ�������ͷdz����ӣ��书��Ҳʮ�ְ��
����ƽ��ʮ�����שͷ�Ǻܼģ������ü�שͷ�����ǾͿ�������������������ĵĽ�������������ŵı���������Ǹ�����ΰ�Ĵ��ã������Ǵֿ��Ľ������������ׯ�����µĽ��ã���һ�����ɼ�שͷ���Ѷ��ɡ�����ԪҲ����ˣ�ͨ����ͬ��ʽ�����Ӻ���Ϣ���ݣ�Ҳ���ܲ����ḻ��ʵ�������ṹ�������������̾�����칦�ܡ�
һ��������
�����������������Ԫ������һ������ɵ��ṹ������Ԫ֮������õĹ�ϵ������ѧģ�ͻ��Ϳ��Եõ�������ģ�͡�
1��������Ļ�������
��������Щ�������ԣ����Ƿ�ӳ������������ʡ�
(1)������
���Ե�˼ά�Ƿ����Եģ����˹�������ģ���˵�˼άҲӦ�Ƿ����Եġ�
(2)�Ǿ�����
�Ǿ��������˵���ϵͳ��һ�����ԣ��˵�������Ϊ�ǷǾ����Ե����������֡��������Դ�������Ԫ����ģ�����ԵķǾ����ԣ����ķֲ��洢�ǷǾ����Ե�һ�ֱ��֡�
(3)�Ƕ�����
��������ģ������˼ά�˶��Ķ���ѧϵͳ����Ӧ����ͬʱ�̵����̼����Լ��Ĺ��ܽ����ģ��ʶ�����һ��ʱ���ϵͳ��
(4)����
������ķ��Լ���ָ���ж����ֵ��Ҳ��ϵͳ���в�ֻһ���Ľ��ȶ���ƽ��״̬���������Ի�ʹϵͳ���ݻ����������������ȫ���Ż��㷨�ͷ�ӳ����һ�㣬����ģ���˻�
2��������ģ��
��������Ŀǰ���м�ʮ�ֲ�ͬ��ģ�͡����ǰ���ͬ�ĽǶȶ���������з��࣬ͨ���ɰ�5��ԭ�����������Ĺ��ࡣ
��������Ľṹ���֣�����ǰ������ͷ������硣
����ѧϰ��ʽ���֣������н�ʦѧϰ����ʦѧϰ���硣
���������������֣����������ͺ���ɢ�����磬����ͺ�ȷ�������硣
����ͻ���������֣�����һ�����Թ�������߽����Թ������硣
����������ϵͳ�IJ��ģ�����֣�������Ԫ���ģ�ͣ����ʽģ�ͣ�������ģ�ͣ���ϵͳ���ģ�ͺ�������ģ�͡�
ͨ�������ǽ϶�ؿ���������Ļ����ṹ��һ�ζ��ԣ��������зֲ����磬�������ӵķֲ����磮�������ӵķֲ����磬���������4�ֻ����ṹ����Щ�ṹ��ͼ1��6��ʾ��
����������ļ�ʮ��������ģ���У����ǽ϶��õ���Hopfield���硢BP���硢Kohonen�����ART(����Ӧ��������)���硣 |
 |
|
|
|
(c) �з������ӵķֲ����� |
(d)�������� | |
|
|
Hopfield����������͵ķ�������ģ�ͣ�����Ŀǰ�����о�������ģ��֮һ��Hopfield����������ͬ����Ԫ���ɵĵ��㣬���Ҳ���ѧϰ���ܵ����������硣����Ҫ�Գ����ӡ��������ϰ�������Լ�Ż����������ȹ��ܡ�
BP�����Ƿ���(Back Propagation)���硣����һ�ֶ��ǰ�����磬������С������ѧϰ��ʽ������һ����㷺Ӧ�õ����硣�������������ۺϣ�ʶ�������Ӧ���Ƶ���;��BP��·���н�ʦѵ����
Kohonen�����ǵ��͵�����֯�����磬��������Ҳ��Ϊ����֯����ӳ������SOM������������ǵ��㵥ά��Ԫ����������Ƕ�ά����Ԫ����Ԫ֮������ԡ�ī����ñ����ʽ���в��������á��������������У���Ԫ֮���н���Զ�ֵķ������ԣ��Ӷ�ʹKohonen���������Ϊģʽ�����ļ������
ART����Ҳ��һ������֯����ģ�͡�����һ����ʦѧϰ���硣���ܹ��Ϻõ�Э����Ӧ�ԣ��ȶ��Ժ����Ե�Ҫ����ART�����У�ͨ����Ҫ�������ܻ�������ϵͳ����ã���������ϵͳ��ע����ϵͳ��ȡ����ϵͳ��ART������Ҫ����ģʽʶ��������֮�������ڶ�ת����ʧ���ģ�仯�����С�
3���������ѧϰ����
�������ѧϰ������Դ��Էֳ�3�࣬��Щ���ֱ����£�
��һ��ѧϰ��������ѧϰ�������ֹ���ֻ�������Ӽ�ļ���ˮƽ�ı�Ȩϵ����
���������������磬��Hopfield���硣
�ڶ���ѧϰ����ƾ���ѧϰ�������ֹ����������ڵ���ⲿ�����ı�Ȩϵ�����ڷ����������ݶ��½�����Ч�����ֲ��������ķ���һ���������Ż����Ӷ������ҵ�ȫ���Ż�ֵ����֪��ѧϰ�Ͳ������־���ѧϰ��������BP�㷨������ͳ�����㷨��ģ���˻��㷨Ҳ��������ѧϰ����
������ѧϰ�������ʦѧϰ��������һ�ֶ��������������Ӧ��ѧϰ����
ART���������֯ѧϰ�㷨��������һ�ࡣ
������������Ϣ��������ѧ����
��������Ϣ������������ѧ������˵����������̿ɷ�Ϊ�����Σ�ִ�нκ�ѧϰ�Ρ�������ǰ���������˵���������Ρ�
1��ִ�н�
ִ�н���ָ�������������Ϣ���д�������������Ӧ��������̡���ִ�нΣ���������ӽṹ��Ȩϵ�����Ѿ�ȷ�����Ҳ���仯�ġ���ʱ�У�
 |
(1-7) |
| Xi(t+1)=fi[ui(t+1)] |
(1-8) | |
|
���У�Xi��ǰ����Ԫ�������
Wij�ǵ�i����Ԫ��ǰ��j����Ԫͻ����Ȩϵ��
��i���ǵ�i����Ԫ�ķ�ֵ��
fiΪ��i����Ԫ�ķ����Լ������
XiΪ��i����Ԫ�������
2��ѧϰ��
ѧϰ����ָ�����������ƵĽΣ���ʱ�����簴һ����ѧϰ������ͻ����Ȩϵ��Wij����ʹ���ᶨ�IJ�Ⱥ���E�ﵽ��С��һ��ȡ��
E=(Ti,Xi) (1-9)
���У�Ti�ǽ�ʦ�źţ�
Xi����Ԫ�������
ѧϰ��ʽ���Ա�ʾΪ������ѧ����ʽ��
 |
(1-10) | |
|
���У�����һ�������Ժ�����
��ij��Ȩ�ر仯�ʣ�
n��ѧϰʱ�ĵ���������
�����ݶ�ѧϰ�㷨������Բ���������幫ʽ��
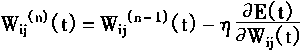 |
(1-11) | |
|
���������Ϣ�Ĵ���һ�㶼��Ҫѧϰ�κ�ִ�нν�ϣ�����ʵ�ֺ����Ĵ������̡����������Ϣ��ѧϰ��Ϊ��ȡ�ö���Ϣ����Ӧ���ԣ�����Ϣ�������������������Ϣ��ִ�й����Ƕ������ļ��������Ƕ���Ϣ�ķ�����̡�
ѧϰ��ִ���������粻��ȱ�ٵ������������ܡ�������ĸ�����Ч����Ϊ�����ã�����ͨ���������ؼ��Ĺ�����ʵ�ֵġ�
ͨ��ѧϰ�Σ�����������ѵ���ɶ�ij����Ϣģʽ�ر����У������ij�������Ķ���ѧϵͳ��ͨ��ִ�нΣ�������������ʶ���й���Ϣģʽ��������
�����ܿ����У�����������Ϊ������������ѧϰʱ������������ȥѧϰ���ض�����������Ӷ�ʹ����������Ӧ���ض�������������ϵ����������ִ��ʱ�������������ѧϰ����֪ʶ�Ա��ض���ʵ��ǡ����ֵĿ��ơ� |
|
1.2����BPģ�� |
|
ѧϰ��������һ������ҪҲ������עĿ���ص㡣��������ķ�չ�����У�ѧϰ�㷨���о�����ʮ����Ҫ�ĵ�λ��Ŀǰ�������������������ģ�Ͷ��Ǻ�ѧϰ�㷨��Ӧ�ġ����ԣ���ʱ���Dz���ȥ�����ģ�ͺ��㷨�����ϸ�Ķ�������֡��е�ģ�Ϳ����ж����㷨�����е��㷨���ܿ����ڶ���ģ�͡���������ʱ����Ҳ���㷨Ϊģ�͡�
�Դ�40���Hebb�����ѧϰ���������������������˸��ָ�����ѧϰ�㷨����������1986��Rumelhart�����������������BP(error BackPropagation)��Ӱ����Ϊ�㷺��ֱ�����죬BP�㷨��Ȼ���Զ�����������Ҫ��Ӧ��������Ч�㷨��
1��2��1 �������ѧϰ�����ͻ���
���������У����ⲿ�����ṩ��ģʽ��������ѧϰѵ�������ܴ洢����ģʽ�����Ϊ��֪�������ⲿ��������Ӧ���������Զ���ȡ�ⲿ�����仯���������Ϊ��֪����
��������ѧϰ�У�һ���Ϊ�н�ʦ����ʦѧϰ���֡���֪�������н�ʦ�źŽ���ѧϰ������֪���������ʦ�ź�ѧϰ�ġ�����Ҫ��������BP���磬Hopfield���磬ART�����Kohonen�����У�BP�����Hopfield��������Ҫ��ʦ�źŲ��ܽ���ѧϰ�ģ���ART�����Kohonen�����������ʦ�źžͿ���ѧϰ����ν��ʦ�źţ�������������ѧϰ�����ⲿ�ṩ��ģʽ�����źš�
һ����֪����ѧϰ�ṹ
��֪����ѧϰ������������͵�ѧϰ��
Ŀǰ���ڿ�����Ӧ�õ��Ƕ��ǰ�����磬����һ�ָ�֪��ģ�ͣ�ѧϰ�㷨��BP���������н�ʦѧϰ�㷨��
һ���н�ʦ��ѧϰϵͳ������ͼ1��7��ʾ������ѧϰϵͳ�ֳ��������֣����벿��ѵ�������������
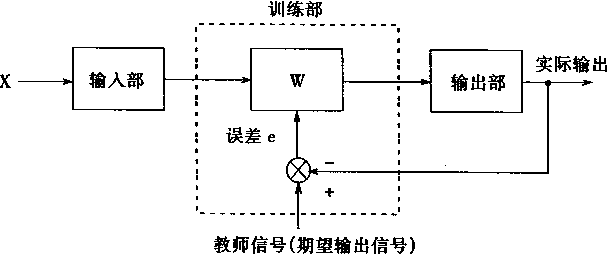
|
|
ͼ1-7 ������ѧϰϵͳ��ͼ |
|
���벿������������������X����ѵ�������������Ȩϵ��W������Ȼ���������������������������У�����������źſ�����Ϊ��ʦ�ź����룬�ɸý�ʦ�ź���ʵ��������бȽϣ����������ȥ������Ȩϵ��W��
ѧϰ��������ͼ1��8��ʾ�Ľṹ��ʾ��
��ͼ�У�Xl��X2������Xn�������������źţ�W1��W2������Wn��Ȩϵ�������������ź�Xi����ȡ��ɢֵ��0����1�������������ź�ͨ��Ȩϵ�����ã���u���������� ��WiXi�����У�
u=��WiXi=W1X1+W2X2+��+WnXn
�ٰ���������ź�Y(t)��u���бȽϣ��Ӷ���������ź�e����Ȩֵ���������������eȥ��ѧϰϵͳ��Ȩϵ�������ģ��ķ���Ӧʹ���e��С�����Ͻ�����ȥ��ʹ�����eΪ�㣬��ʱʵ�����ֵu���������ֵY(t)��ȫһ������ѧϰ���̽�����

|
|
�������ѧϰһ����Ҫ����ظ�ѵ����ʹ���ֵ����������������㡣����ʱ�Ż�ʹ���������һ�¡��ʶ��������ѧϰ������һ��ʱ�ڵģ��е�ѧϰ����Ҫ�ظ��ܶ�Σ���������μ���ԭ�������������Ȩϵ��W�кܶ����W1��W2��----Wn��Ҳ����һ���������ϵͳ��ϵͳ�IJ����ĵ����ͱض���ʱ������Ŀǰ������������ѧϰ�ٶȣ�����ѧϰ�ظ�������ʮ����Ҫ���о����⣬Ҳ��ʵʱ�����еĹؼ����⡣
������֪����ѧϰ�㷨
��֪�����е�����㵥Ԫ�������磬������Ԫ������ֵԪ����ɡ���֪����ͼ1-9��ʾ��
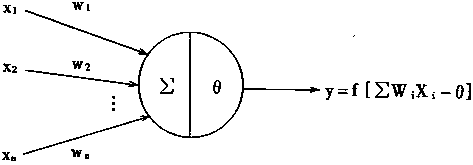
|
|
ͼ1-9 ��֪���ṹ
��֪������ѧģ�ͣ�
 |
(1-12) | |
|
���У�f[.]�ǽ�Ծ������������
 |
(1-13) | |
|
���Ƿ�ֵ��
��֪����������þ��ǿ��Զ�������������࣬������������������֪���������źŵķ������£�
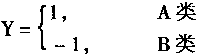 |
(1-14) | |
|
���ǣ�����֪�������Ϊ1ʱ������������ΪA�ࣻ���Ϊ-1ʱ������������ΪB�ࡣ���Ͽ�֪��֪���ķ���߽��ǣ�
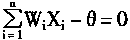 |
(1-15) | |
|
����������ֻ����������X1��X2ʱ�����з���߽�������
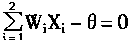 |
(1-16) | |
|
��
W1X1+W2X2-��=0 (1-17)
Ҳ��д��
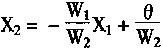 |
(1-18) | |
|
��ʱ�ķ���������1��10��ʾ��
��֪����ѧϰ�㷨Ŀ��������Ѱǡ����Ȩϵ��w��(w1��w2������Wn)��ʹϵͳ��һ���� ��������x��(xt��x2������xn)�ܲ�������ֵd����x����ΪA��ʱ������ֵd��1��XΪB�� ʱ��d=-1��Ϊ�˷���˵����֪��ѧϰ�㷨���ѷ�ֵ������Ȩϵ��w�У�ͬʱ������xҲ��Ӧ����һ ������xn+1�����
Wn+1=-�ȣ�Xn+1=1 (1-19)
���֪��������ɱ�ʾΪ��
 |
(1-20) | |
|
��֪��ѧϰ�㷨�������£�
1����Ȩϵ��w�ó�ֵ
��Ȩϵ��w��(W1��W2������Wn��Wn+1)�ĸ���������һ����С�������ֵ����Wn+1��
��g������ΪWl(0)��W2(0)������Wn(0)��ͬʱ��Wn+1(0)��-��������Wi(t)Ϊtʱ�̴ӵ�i��
�����ϵ�Ȩϵ����i��1��2������n��Wn+1(t)Ϊtʱ��ʱ�ķ�ֵ��
|
|
ͼ1-10 ��֪���ķ������� |
|
2������һ����X��(X1��X2������Xn+1)�Լ������������d��
�������ֵd��������������ͬʱȡֵ��ͬ�����x��A�࣬��ȡd��1,���x��B�࣬��ȡ-1���������dҲ���ǽ�ʦ�źš�
3������ʵ�����ֵY
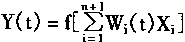
4������ʵ����������e
e��d��Y(t) (1-21)
5�������eȥ��Ȩϵ��
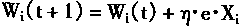
i=1,2,��,n,n+1 (1-22)
���У��dz�ΪȨ�ر仯�ʣ�0<�ǡ�1
��ʽ(1��22)�У��ǵ�ȡֵ����̫�����1ȡֵ̫�����Ӱ��wi(t)���ȶ�����ȡֵҲ����̫С��̫С���ʹWi(t)����ȡ���������ٶ�̫����
��ʵ�����������ֵd��ͬʱ�У�
Wi(t+1)=Wi(t)
6��ת����2�㣬һֱִ�е�һ���������ȶ�Ϊֹ��
������ʽ(1��14)��֪����֪��ʵ����һ�����������������ַ����ǺͶ�ֵ����Ӧ�ġ���ˣ���֪����������ʵ��������������Ը�֪��ʵ���������������һЩ���ܡ�
�����ø�֪��ʵ��������X1VX2����ֵ��
| |
| X1 |
0011 |
| X2 |
0101 |
| X1 V X2 |
0111 | | |
|
��X1VX2��1ΪA�࣬��X1VX2=0ΪB�࣬���з�����
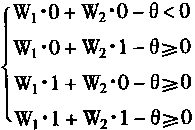 |
(1-23) | |
����
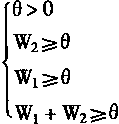 |
(1-24) | |
|
��ʽ(1��24)�У�
W1�ݦ�,W2�ݦ�
�� W1=1,W2=2
��������1
ȡ ��=0.5
���У�X1+X2-0.5=0,���������ͼ1��11��ʾ��
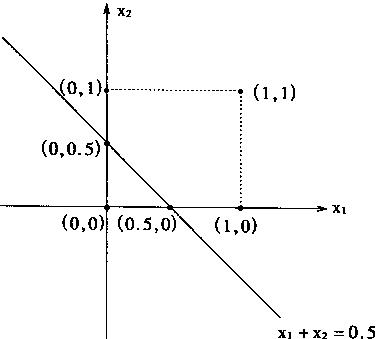
|
|
ͼ1-11 ������X1VX2�ķ���
1��2��2 ������ѧϰ���ݶ��㷨
�Ӹ�������ѧϰ�㷨��֪��ѧϰ��Ŀ���������������е�Ȩϵ����ʹ����������������ģʽ��������ȷ���ࡣ��ѧϰ����ʱ��Ҳ������������ȷ����ʱ����ȻȨϵ���ͷ�ӳ��ͬ������ģʽ�����Ĺ�ͬ���������仰����Ȩϵ�����Ǵ洢�˵�����ģʽ������Ȩϵ���Ƿ�ɢ���ڵģ�����������Ȼ��Ȼ���зֲ��洢���ص㡣
ǰ��ĸ�֪���Ĵ��ݺ����ǽ�Ծ���������ԣ�������������������ǰ��һ�������ĸ�֪��ѧϰ�㷨���䴫�ݺ����ļ����ھ����ԡ�
��֪��ѧϰ�㷨�൱�����ҵ��������Կɷ�ʱ��֤����������Ҳ�������⣺�������������Կɷ�ʱ��������������⣬�����ƹ㵽һ��ǰ�������С�
Ϊ�˿˷����ڵ����⣬�������������һ���㷨�����ݶ��㷨(Ҳ����LMS��)��
Ϊ����ʵ���ݶ��㷨���ʰ���Ԫ�ļ���������Ϊ���ֺ���������Sigmoid�������ǶԳ�Sigmoid����Ϊf(X)=1/(1+e-x),�Գ�Sigmoid����f(X)=(1-e-x)/(1+e-x)����������ʽ(1��13)�Ľ�Ծ������
���ڸ�����������Xi(i��1��2����n)���ݶȷ���Ŀ����Ѱ��Ȩϵ��W*��ʹ��f[W*.Xi]���������Yi�����ܽӽ���
�����e������ʽ��ʾ��
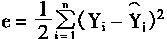 |
(1-25) | |
|
���У�Yi��f��W*��Xi]�Ƕ�Ӧ��i������Xi��ʵʱ���
Yi�Ƕ�Ӧ��i������Xi�����������
Ҫʹ���e��С��������ȡe���ݶȣ�
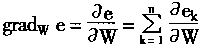 |
(1-26) | |
|
���� |
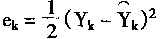 |
(1-27) | |
|
�� Uk=W.Xk,����
 |
(1-28) | |
|
����
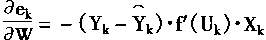 |
(1-29) | |
|
����а����ݶȷ�����Ȩϵ��W���Ĺ���
 |
(1-30) | |
|
Ҳ��д�ɣ�
 |
(1-31) | |
|
����ʽ(1��30)��ʽ(1��31)�У�����Ȩ�ر仯�ʣ����������ͬ��ȡֵ��ͬ��һ��ȡ0-1֮���С����
�����ԣ��ݶȷ���ԭ����֪����ѧϰ�㷨����һ����ؼ��������㣺
1����Ԫ�Ĵ��ݺ�������������s�ͺ����������ǽ�Ծ������
2����Ȩϵ�����IJ��������ݶ�ȥ���ƣ������Dz������ȥ���ơ��ʶ��и��õĶ�̬���ܣ�����ǿ���������̡�
�����ݶȷ�����ʵ��ѧϰ��˵����Ȼ�Ǹо�̫�������ԣ������㷨��Ȼ�Dz�����ġ�
1��2��3 ����ѧϰ��BP�㷨
�����㷨Ҳ��BP�㷨�����������㷨�ڱ�������һ��������ѧϰ����ѧģ�ͣ����ԣ���ʱҲ��ΪBPģ�͡�
BP�㷨��Ϊ�˽�����ǰ���������Ȩϵ���Ż���������ģ����ԣ�BP�㷨Ҳͨ����ʾ������������˽ṹ��һ�������Ķ��ǰ�����硣�ʶ�����ʱҲ���������ǰ������ΪBPģ�͡�
���������Ҫ������ϸ�ȥ���ۺ������㷨��ģ�����ߵ��й���ͬ����֪��ѧϰ�㷨��һ�ֵ��������ѧϰ�㷨���ڶ�������У���ֻ�ܸı����Ȩϵ������ˣ���֪��ѧϰ�㷨�������ڶ���������ѧϰ��1986�꣬Rumelhart����˷���ѧϰ�㷨����BP(backpropagation)�㷨�������㷨���Զ������и����Ȩϵ�������������������ڶ�������ѧϰ��BP�㷨��Ŀǰ��㷺�õ�������ѧϰ�㷨֮һ�����Զ��������������õ�ѧϰ�㷨��
һ��BP�㷨��ԭ��
BP�㷨������ǰ����������ѧϰ�㷨��ǰ���������Ľṹһ����ͼ1��12��ʾ

|
|
ͼ1-12 ����ѧϰ�ṹ
���������˲㡢������Լ��������������֮����м�㡣�м���е�����㣬�������Ǻ����û��ֱ�ӵ���ϵ����Ҳ��Ϊ���㡣�������е���ԪҲ������Ԫ��������Ȼ����粻���ӣ����ǣ����ǵ�״̬��Ӱ���������֮��Ĺ�ϵ����Ҳ��˵���ı������Ȩϵ�������Ըı������������������ܡ�
����һ��m��������磬����������������X�����k���i��Ԫ�������ܺͱ�ʾΪUik�����Xik���ӵ�k��1��ĵ�j����Ԫ����k��ĵ�i����Ԫ��Ȩϵ��ΪWij������Ԫ�ļ�������Ϊf������������Ĺ�ϵ���������й���ѧʽ��ʾ��
| Xik=f(Uik) |
(1-32) |
 |
(1-33) | |
|
�����㷨�ֶ������У��������ͷ��������������̵Ĺ����������¡�
1������
���������������㾭������Ԫһ��һ����д�����ͨ�����е�����֮����������㣻����㴦���Ĺ����У�ÿһ����Ԫ��״ֻ̬����һ����Ԫ��״̬����Ӱ�졣���������������������������бȽϣ������������������������������뷴�����̡�
2������
����ʱ��������źŰ�ԭ��������ͨ·���أ�����ÿ������ĸ�����Ԫ��Ȩϵ�������ģ���������ź�������С��
����BP�㷨����ѧ����
BP�㷨ʵ������ȡ��������Сֵ���⡣�����㷨���÷����Թ滮�е������½��������������ĸ��ݶȷ�����Ȩϵ����
Ϊ��˵��BP�㷨�����ȶ�������e��ȡ���������ʵ�����֮���ƽ����Ϊ���������У�
 |
(1-34) | |
|
���У�Yi�������Ԫ������ֵ����Ҳ������������ʦ�źţ�
Xim��ʵ���������Ϊ��m��������㡣
����BP�㷨������e�ĸ��ݶȷ�����Ȩϵ������Ȩϵ��Wij������Awij����e
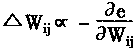 |
(1-35) |
| Ҳ��д�� |
|
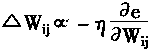 |
(1-36) | |
|
���У���Ϊѧϰ���ʣ���������
�����ԣ�����BP�㷨ԭ����ae/aWij��ؼ��ġ�������ae/aWij����
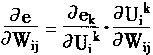 |
(1-37) |
| ���� |
|
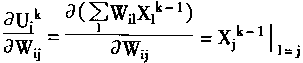 |
(1-38) |
| �ʶ� |
|
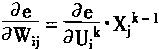 |
(1-39) |
| �Ӷ��� |
|
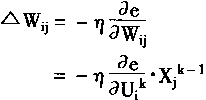 |
(1-40) |
| �� |
|
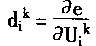 |
(1-41) |
| ����ѧϰ��ʽ�� |
|
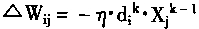 |
(1-42) | |
|
���У���Ϊѧϰ���ʣ���������һ��ȡ0-1�������
�������֪��dikʵ����ĩ�������Ե��㷨��ʽ��������dik�ļ��㹫ʽ��
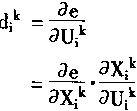 |
(1-43) |
|
��ʽ(1-32)��֪��ʽ(1-43)�У��� |
|
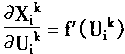 |
(1-44) | |
|
Ϊ�˷��������ȡfΪ����������һ��ȡ��������������������Sigmoid��������ȡfΪ�ǶԳ�Sigmoid����ʱ���У�

����f'(Uik)=f'(Uik)(1-f(Uik))
=Xik(1-Xik) (1-45)
�ٿ���ʽ(1��43)�е�ƫ����ae��aXik������������迼�ǵģ�
���k��m����������㣬��ʱ��Yi���������ֵ�����dz�������ʽ(1-34)��
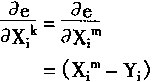 |
(1-46) |
| �Ӷ��� dim=Xim(1-Xim)(Xim-Yi) |
(1-47) |
| 2�����k |
|
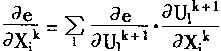 |
(1-48) |
| ��ʽ(1��41)�У���֪�У� |
|
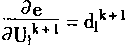 |
(1-49) |
| ��ʽ(1��33)�У���֪�У� |
|
 |
(1-50) |
| �ʶ��� |
|
 |
(1-51) |
| ����� |
|
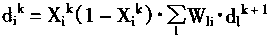 |
(1-52) | |
|
���������̿�֪����������ѵ�������ǰ�һ�������ӵ�����㣬��������ǰ�����Ĺ���
Xik=f(Uik)
����һ��һ��������㴫�ݣ��������������Եõ����Xim��
��Xim���������Yi���бȽϣ�������߲��ȣ����������ź�e�����������湫ʽ������Ȩϵ����
|
|
���湫ʽ�У���ȡ����dikʱ��Ҫ�õ���һ���dik+1���ɼ�����������ȡ�Ǵ�����㿪ʼ���������ķ������̡�����������в��Ͻ��еݹ�����
ͨ����������ķ���ѵ����ͬʱ��������С�ķ����Ȩϵ�������������Դ����������������湫ʽҲ����֪�����������IJ����϶�ʱ�����õļ��������൱�ɹۣ��ʶ������ٶȲ��졣
Ϊ�˼ӿ������ٶȣ�һ�㿼����һ�ε�Ȩϵ������������Ϊ��������������֮һ���ʶ���������ʽ��
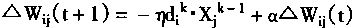 |
(1-54) | |
|
���У���Ϊѧϰ���ʣ�������������0��1��0��4����
��ΪȨϵ������������ȡ0��7��0��9���ҡ�
�����棬ʽ(1��53)Ҳ��Ϊһ�㻯��Delta������û������������磬��ȡ
 |
(1-55) | |
|
���У���YiΪ���������
XjΪ������ʵ�������
XiΪ���������롣
����Ȼ��һ��ʮ�ּ������ʽ(1��55)Ҳ��Ϊ��Delta����
��ʵ��Ӧ���У�ֻ��һ�㻯��Delta����ʽ(1��53)��ʽ(1��54)�������塣��Delta����ʽ(1��55)ֻ�������Ƶ������á�
����BP�㷨��ִ�в���
�ڷ����㷨Ӧ����ǰ���������ʱ������SigmoidΪ��������ʱ���������в���������Ȩϵ��Wij���еݹ���ȡ��ע�����ÿ����n����Ԫ��ʱ����i��1��2������n��j��1��2������n�����ڵ�k��ĵ�i����Ԫ������n��Ȩϵ��Wi1��Wi2������Win������ȡ�ࡪ��Win+1���ڱ�ʾ��ֵ��i����������������Xʱ��ȡx��(X1��X2������Xn��1)��
�㷨��ִ�еIJ������£�
1����Ȩϵ��Wij�ó�ֵ��
�Ը����Ȩϵ��Wij��һ����С�ķ����������������Wi,n+1=-����
2������һ������X��(xl��x2������xn��1)���Լ���Ӧ�������Y��(Y1��Y2������Yn)��
3�������������
���ڵ�k���i����Ԫ�����Xik���У�
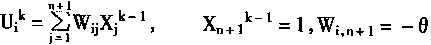 |
| Xik=f(Uik) | |
|
4��������ѧϰ���dik
�����������k��m����
dim=Xim(1-Xim)(Xim-Yi)
�����������㣬��

5������Ȩϵ��Wij�ͷ�ֵ��
��ʽ(1��53)ʱ�У�
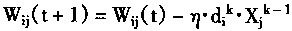
��ʽ(1��54)ʱ�У�

����
6��������˸������Ȩϵ��֮�ɰ�����Ʒ��ָ���б��Ƿ�����Ҫ���������Ҫ�����㷨���������δ����Ҫ����(3)ִ�С�
���ѧϰ���̣�������һ����������Xp��(Xp1��Xp2����Xpn��1)���������Yp=(Yp1��Yp2������Ypn)��Ҫִ�У�ֱ�����������������Ҫ��Ϊֹ�� |
1.3 Hopfieldģ�� | |
1982�꣬J��Hopfield����˿���������洢���Ļ������磬��������ΪHopfield����ģ�ͣ�Ҳ��Hopfieldģ�͡�Hopfield������ģ����һ��ѭ�������磬������������з������ӡ�Hopfield��������ɢ�ͺ����������֡�
����������������������з�����������ˣ����ԣ�Hopfield����������ļ����£���������ϵ�״̬�仯����������֮������ȡ��Hopfield�����������������������Ӷ������µ�����������������һֱ������ȥ�����Hopfield������һ�����������ȶ����磬���������������ļ�������������ı仯Խ��ԽС��һ���������ȶ�ƽ��״̬����ôHopfield����ͻ����һ���ȶ��ĺ�ֵ������һ��Hopfield������˵���ؼ�������ȷ�������ȶ������µ�Ȩϵ����
Ӧ��ָ���������������ȶ��ģ�Ҳ�в��ȶ��ġ�����Hopfield������˵������������б������ȶ����磬����Dz��ȶ������⣻���б�������ʲô��Ҳ����Ҫȷ���ġ�
1��3��1 ��ɢHopfield����
Hopfield��������������Ƕ�ֵ�����磬��Ԫ�����ֻȡ1��0������ֵ�����ԣ�Ҳ����ɢHopfield�����硣����ɢHopfieId�����У������õ���Ԫ�Ƕ�ֵ��Ԫ���ʶ������������ɢֵ1��0�ֱ��ʾ��Ԫ���ڼ��������״̬��
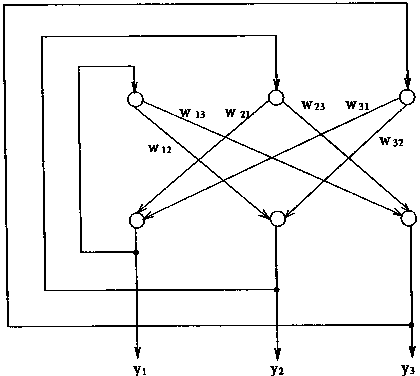
���ȿ�����������Ԫ��ɵ���ɢHopfield�����磬��ṹ��ͼ1��13����ʾ��
��ͼ�У���0���������Ϊ��������ˣ�������ʵ����Ԫ���������㹦�ܣ�����һ����ʵ����Ԫ���ʶ�ִ�ж�������Ϣ��Ȩϵ���˻����ۼӺͣ����ɷ����Ժ���f��������������Ϣ��f��һ���ķ�ֵ��Ч�������Ԫ�������Ϣ���ڷ�ֵ������ô����Ԫ�������ȡֵΪ1��С�ڷ�ֵ��������Ԫ�������ȡֵΪ����
| |
ͼ1-13 ����Ԫ��ɵ�Hopfield���� | |
���ڶ�ֵ��Ԫ�����ļ��㹫ʽ����
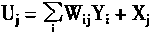
���У�xiΪ�ⲿ���롣�����У�
Yi=1,��Ui����iʱ
Yi=0,��Ui<��iʱ
����һ����ɢ��Hopfield���磬������״̬�������Ԫ��Ϣ�ļ��ϡ�����һ���������n����Ԫ�����磬����tʱ�̵�״̬Ϊһ��nά������
Y(t)=[Y1(t),Y2(t),...,Yn(t)]T
�ʶ�������״̬��2n��״̬����ΪYj(t)(j��1����n)����ȡֵΪ1��0����nά����Y(t)��2n��״̬����������״̬��
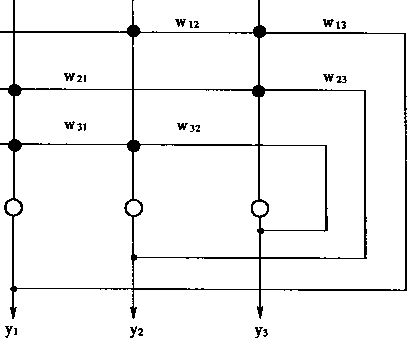
����������Ԫ����ɢHopfield���磬��������������λ����������ÿһ����λ������������һ������״̬���Ӷ�����8������״̬����Щ����״̬��ͼ1��14����ʾ����ͼ�У��������ÿһ�����DZ�ʾһ������״̬��ͬ��������n����Ԫ������㣬����2n������״̬��Ҳ��һ��nά��������Ķ������Ӧ��
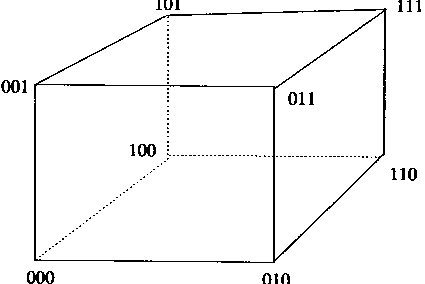
| |
ͼ1-14 ����Ԫ����������״̬ | |
���Hopfield������һ���ȶ����磬��ô�����������˼���һ�������������������״̬������仯��Ҳ���Ǵӳ��������һ������ת������һ�����ǣ����������ȶ���һ���ض��Ķ��ǡ�
����һ����n����Ԫ��ɵ���ɢHopfield���磬����n*nȨϵ������w��
W={Wij} i=1,2,...,n j=1,2,...,n
ͬʱ����nά��ֵ�����ȣ�
��=[��1,��2,...��n]T
һ�����ԣ�w��������ȷ��һ��Ψһ����ɢHopfield���硣����ͼ1��13��ʾ������Ԫ��ɵ�Hopfield���磬Ҳ���Ը���ͼ1��15��ʾ��ͼ�α�ʾ��������ͼ�ε�������һ���ġ�������ɢHopfield�����һ���ڵ�״̬����Yj(t)��ʾ��j����Ԫ�����ڵ�j��ʱ��t��״̬����ڵ����һ��ʱ��(t+1)��״̬����������£�

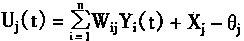
��Wij��i��jʱ����0����˵��һ����Ԫ����������ᷴ�������Լ������룻��ʱ����̵�HopfieId�����Ϊ���Է������硣
��Wij��i��jʱ������0����˵��������Ԫ������ᷴ�������Լ������룻��ʱ����ɢ��Hopfield�����Ϊ���Է��������硣
| |
ͼ1-15 ��ɢHopfield���������һ��ͼʾ | | ��ɢHopfield�����ж��ֲ�ͬ�Ĺ�����ʽ��
1������(�첽)��ʽ
��ʱ��tʱ��ֻ��ijһ����Ԫj��״̬�����仯��������n-1����Ԫ��״̬������ʱ�ƴ��й�����ʽ��������
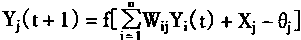
Yi(t+1)=Yj(t) i��j
�ڲ������ⲿ����ʱ������
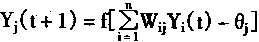
2������(ͬ��)��ʽ
����һʱ��t�����е���Ԫ��״̬�������˱仯����Ʋ��й�����ʽ��������
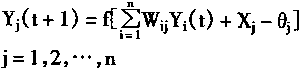
�ڲ������ⲿ����ʱ������
j=1,2,...,n
����һ��������˵���ȶ�����һ���ش������ָ�ꡣ
������ɢHopfield���磬��״̬ΪY(t)��
Y(t)=[Y1(t),Y2(t),...,Yn(t)]T
����������κ���t>0�����������t��0��ʼ���г�ʼ״̬Y(0)����������ʱ��t���У�
Y(t+��t)=Y(t)
����������ȶ��ġ�
�ڴ��з�ʽ�µ��ȶ��Գ�֮Ϊ�����ȶ��ԡ�ͬ�����ڲ��з�ʽ���ȶ��Գ�֮Ϊ�����ȶ��ԡ����������ȶ�ʱ����״̬���ȶ�״̬��
����ɢ��Hopfield������Կ���������һ�ֶ����룬���з�ֵ�Ķ�ֵ�����Զ���ϵͳ���ڶ���ϵͳ�У�ƽ���ȶ�״̬��������Ϊϵͳ��ij����ʽ������������ϵͳ�˶������У�������ֵ���ϼ�С���������Сֵ��
��Hopfield��������һ��Lyapunov����������ν����������
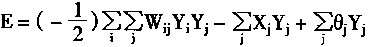
����
 |
(1-46) |
| ������Ԫj�������������ɱ�ʾΪ |
|
 |
(1-47) | | |
Ҳ������
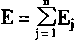
��Ԫj�������仯����ʾΪ��Ej��
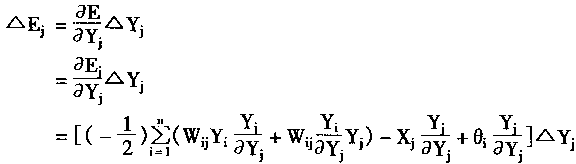 |
(1-48) | | |
����������� Wii=0,i=1,2,...,n
Wij=Wji i=1,2,...,n j=1,2,...,n
����
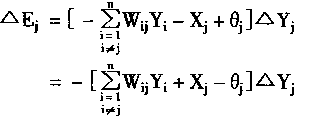 |
(1-49) | | |
���У�EjΪ��Ԫj��������
��EjΪ��Ԫj�������仯��
WijΪ��Ԫi����Ԫj��Ȩϵ����
YiΪ��Ԫj�������
XjΪ��Ԫj���ⲿ���룻
��jΪ��Ԫj�ķ�ֵ��
��YjΪ��Ԫj������仯��
�������
Uj=��WijYi+Xj
����Ej�ɱ�ʾΪ��
�����������������
1�����Uj����j������Ԫj����������ֵ���ڷ�ֵ����Uj-��j��0����Ӷ�ֵ��Ԫ�ļ��㹫ʽ֪����Yj��ֵ����Ϊ1�����ߴ�0�䵽1����˵��Yj�ı仯��Yjֻ����0����ֵ����ʱ����������Ej��
��Ej��0
��˵��Hopfield������Ԫ���������ٻ䡣
2�����Uj����j������Ԫj����������ֵС�ڷ�ֵ����Uj-��j��0����Ӷ�ֵ��Ԫ�ļ��㹫ʽ��֪��Yj��ֵ����Ϊ0�����ߴ�1�䵽0����˵��Yj�ı仯��Yjֻ�������λ����ʱ������Ej��
��Ej��0
��Ҳ˵��Hopfield������Ԫ���������١�
��������˵����Hopfield������Ȩϵ������W�ĶԽ���Ԫ��Ϊ0������W����Ԫ�ضԳ�ʱ��Hopfield�������ȶ��ġ�
Coben��Grossberg��1983������˹���Hopfield�����ȶ��ij������������ָ����
���Hopfield�����Ȩϵ������w��һ���Գƾ����ң��Խ���Ԫ��Ϊ0��������������ȶ��ġ�����˵��Ȩϵ������W�У����
i=jʱ��Wij=0
i��jʱ��Wij=Wji
��Hopfield�������ȶ��ġ�
Ӧ��ָ������ֻ��Hopfield�����ȶ��ij�������������DZ�Ҫ��������ʵ�����кܶ��ȶ���Hopfield���磬�������Dz�������Ȩϵ������w�ǶԳƾ�����һ������
����ķ�����֪��
���Է�����Ȩϵ���Գ�Hopfield�������ȶ������硣����ͼ1��16��ͼ1��17��ʾ��
| |
ͼ1-16 �Խ���Ȩϵ��Ϊ0�ĶԳ�Hopfield����
| |
ͼ1-17 �Խ���Ȩϵ��Ϊ0�ĶԳ�����һͼʾ | |
Hopfield�����һ�������ǿ�����������䣬Ҳ��������洢������������������ص�֮һ���������ν���������顱���Ǽ���һЩ��ͬ��ȥ�Ӵ��ľ�����ײ����Թ�ȥ�龰�Ļ�����˼�䡣����Hopfield���磬�������������ʱ������ͨ��һ��ѧϰѵ������ȷ�������е�Ȩϵ����ʹ���������Ϣ�������nά���������ijһ�����ǵ�������С���������Ȩϵ��ȷ��֮��ֻҪ�������������������������������Ǿֲ����ݣ�������ȫ�ֲ���ȷ�����ݣ�����������Ȼ�������������Ϣ�����������1984��Hopfield������һ����nάHopfield����������洢���Ľṹ������������У�Ȩϵ���ĸ�ֵ����Ϊ�洢����������洢����(out product storage prescription)����ԭ�����£�
����m�������洢����x1��x2������xm
X1={X11,X21,...,Xm1}
X2={X12,X22,...,Xm2}
......
Xm={Xm1,Xm2,...,Xmm}
����m�����������洢��Hopfield�����У����������е�i��j�����ڵ�֮��Ȩϵ����ֵΪ��

���У�kΪ��������Xk���±꣬k��1��2����m��
i��j�ֱ�����������Xk�ĵ�i��j����Xi��Xj���±ꣻi��j��1��2����n��
������洢������������������£�
����һ������X���������������ȡ�������еĴ洢���ݡ���ʱ��������
X={X1,X2,...Xn}
�ĸ�������x1��x2������xn�������Ӧ�Ľڵ�j��(j��1��2������n)����ڵ�����Ӧ�ij�ʼ״̬Yj(0)������
Yj(0)=Xj��j��1��2������n
���ţ���Hopfield�����а�����ѧϵͳԭ����м��㣬��
Yj(t+1)=f[��WijYj(0)-��j] , i,j��1��2������n
���У�f[��]�Ƿ����Ժ�������ȡ��Ծ������
ͨ��״̬���ϱ仯�����״̬���ȶ����������յ�״̬�Ǻ�������x��ӽ����������������ԣ�Hopfield������������Ҳ���Ǹ��������������������������˵������ʹ��������������ȫ�ֲ���ȷ��Ҳ���ҵ���ȷ�Ľ�����ڱ����ϣ���Ҳ���˲����ܡ�
1��3��2����Hopfield����
����Hopfield��������ӽṹ����ɢHopfield����Ľṹ��ͬ���������ӽṹ���������ϵͳ�д������ڵ�������·����һ�µġ�������Hopfield�����У�����ɢHopfield����һ�������ȶ�����ҲҪ��Wij=Wji��
����Hopfield�������ɢHopfield���粻ͬ�ĵط������亯��g���ǽ�Ծ����������S�ε�����������һ��ȡ
g(u)=1/(1+e-u) (1-50)
����Hopfield������ʱ�����������ģ����ԣ������и���Ԫ�Ǵ���ͬ����ʽ�����ġ����Ƕ���һ����ϸ��������Ԫj�����ڲ�Ĥ��λ״̬��uj��ʾ��ϸ��Ĥ�������ΪCj��ϸ��Ĥ�Ĵ��ݵ���ΪRj�������ѹΪVj���ⲿ���������Ij��ʾ��������Hopfield�������ͼ1��18��ʾ�ĵ�·��ʾ��
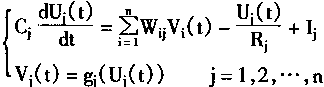 |
(1-51) | | | ���У�n����������Ԫ�ĸ���
vj(t)������
Uj(t)������

| |
ͼ1-18 ����Hopfield����ĵ�·��ʽ
��������Hopfield���磬Hopfield���������ȶ��Զ�����
������������E(t)
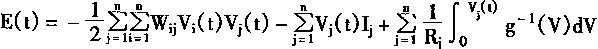 |
(1-52) | | |
���У�g-1(v)��Vj(t)��gj(uj(t))�ķ�������
�������Hopfield��������Ԫ���ݺ����ǵ����������������н纯��������Wij��Wji������

�����ҽ���
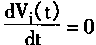
ʱ����
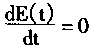
���������������Խ������£���������Ԫ�Ĵ��ݺ�����S��������������Ȩϵ������Գƣ�����ʱ��ı仯������������½��䣻���ҽ��������λ��ʱ��仯����ʱ������������Ż�䡣������֮�������������µ�����������������½��ġ�
���������֤���������£�
����������E(t)��ʱ��ĵ���dE(t)��dt������
 |
|
(1-53) | | |
�������Wij��Wji������ʽ��дΪ
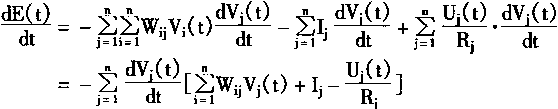 |
(1-54) |
| ������Hopfield����Ķ�̬���̣��� |
 |
(1-55) |
| ������(1��54)ʽ��д�� |
|
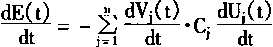 |
(1-56) |
| ���� Vj(t)=gj(Uj(t)) |
(1-57) |
| �ʶ��� Uj(t)=gj-1(Vj(t)) |
(1-58) |
| �Ӷ��� |
|
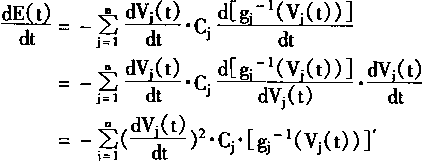 |
(1-59) |
| �� g(u)=1/(1+exp(-u)) |
(1-60) | | |
��֪�䷴����Ϊ�������������������dE(t)��dt�е�gj-1(vj(t))�����е��������ص㣮���䵼���ض�����0����
[gj-1(vj(t))]'>0
ͬʱ����֪��
Cj>0

�����ԣ���dE(t)��dtʱ���ض���
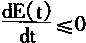
���ҵ�������
��

���ˣ�����֤����ϡ�
�������˵��Hopfield�������������E(t)�ǵ����½��ģ����E(t)���½磬����ȷ���ļ�Сֵ����ô����ض����ȶ��ġ����ң�����֪���ȶ����Ӧ�������������½磬����Сֵ��
��һ��������ֻ��֤�������������½磬��ô���Ϳ���֤���������ȶ��ġ�
����֤�������Hopfield����Ĵ��ݺ���g�����������н�ģ���ô����������E(t)���н�ġ�
��������½��ۣ�
��Hopfield�������Ԫ���ݺ���g���������н�ģ�����Sigmoid���������������Ȩϵ������Գƣ����������Hopfield�������ȶ��ġ���ʵ��Ӧ���У��κ�һ��ϵͳ��������Ż������������������E(t)��ΪĿ�꺯������ô���ܿ���������Hopfield������������⡣����������������E(t)��Hopfieldʹ������������Ż�ֱ�Ӷ�Ӧ�����ֹ����Ǿ߿����Եġ���������������Ż����㣬��������������һ����ϵͳ������ʼ�Ĺ��Ƶ㣬����ʼ������Ȼ����������˶����ݶ��ҵ���Ӧ��С�㡣�������������Ż����ⶼ������������Hopfield������⡣��Ҳ��Hopfield������������Ļ���ԭ�� |
1.3 Hopfieldģ�� |
1982�꣬J��Hopfield����˿���������洢���Ļ������磬��������ΪHopfield����ģ�ͣ�Ҳ��Hopfieldģ�͡�Hopfield������ģ����һ��ѭ�������磬������������з������ӡ�Hopfield��������ɢ�ͺ����������֡�
����������������������з�����������ˣ����ԣ�Hopfield����������ļ����£���������ϵ�״̬�仯����������֮������ȡ��Hopfield�����������������������Ӷ������µ�����������������һֱ������ȥ�����Hopfield������һ�����������ȶ����磬���������������ļ�������������ı仯Խ��ԽС��һ���������ȶ�ƽ��״̬����ôHopfield����ͻ����һ���ȶ��ĺ�ֵ������һ��Hopfield������˵���ؼ�������ȷ�������ȶ������µ�Ȩϵ����
Ӧ��ָ���������������ȶ��ģ�Ҳ�в��ȶ��ġ�����Hopfield������˵������������б������ȶ����磬����Dz��ȶ������⣻���б�������ʲô��Ҳ����Ҫȷ���ġ�
1��3��1 ��ɢHopfield����
Hopfield��������������Ƕ�ֵ�����磬��Ԫ�����ֻȡ1��0������ֵ�����ԣ�Ҳ����ɢHopfield�����硣����ɢHopfieId�����У������õ���Ԫ�Ƕ�ֵ��Ԫ���ʶ������������ɢֵ1��0�ֱ��ʾ��Ԫ���ڼ��������״̬��
���ȿ�����������Ԫ��ɵ���ɢHopfield�����磬��ṹ��ͼ1��13����ʾ��
��ͼ�У���0���������Ϊ��������ˣ�������ʵ����Ԫ���������㹦�ܣ�����һ����ʵ����Ԫ���ʶ�ִ�ж�������Ϣ��Ȩϵ���˻����ۼӺͣ����ɷ����Ժ���f��������������Ϣ��f��һ���ķ�ֵ��Ч�������Ԫ�������Ϣ���ڷ�ֵ������ô����Ԫ�������ȡֵΪ1��С�ڷ�ֵ��������Ԫ�������ȡֵΪ����
| |
ͼ1-13 ����Ԫ��ɵ�Hopfield���� | |
���ڶ�ֵ��Ԫ�����ļ��㹫ʽ����
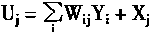
���У�xiΪ�ⲿ���롣�����У�
Yi=1,��Ui����iʱ
Yi=0,��Ui<��iʱ
����һ����ɢ��Hopfield���磬������״̬�������Ԫ��Ϣ�ļ��ϡ�����һ���������n����Ԫ�����磬����tʱ�̵�״̬Ϊһ��nά������
Y(t)=[Y1(t),Y2(t),...,Yn(t)]T
�ʶ�������״̬��2n��״̬����ΪYj(t)(j��1����n)����ȡֵΪ1��0����nά����Y(t)��2n��״̬����������״̬��
����������Ԫ����ɢHopfield���磬��������������λ����������ÿһ����λ������������һ������״̬���Ӷ�����8������״̬����Щ����״̬��ͼ1��14����ʾ����ͼ�У��������ÿһ�����DZ�ʾһ������״̬��ͬ��������n����Ԫ������㣬����2n������״̬��Ҳ��һ��nά��������Ķ������Ӧ��
| |
ͼ1-14 ����Ԫ����������״̬ | |
���Hopfield������һ���ȶ����磬��ô�����������˼���һ�������������������״̬������仯��Ҳ���Ǵӳ��������һ������ת������һ�����ǣ����������ȶ���һ���ض��Ķ��ǡ�
����һ����n����Ԫ��ɵ���ɢHopfield���磬����n*nȨϵ������w��
W={Wij} i=1,2,...,n j=1,2,...,n
ͬʱ����nά��ֵ�����ȣ�
��=[��1,��2,...��n]T
һ�����ԣ�w��������ȷ��һ��Ψһ����ɢHopfield���硣����ͼ1��13��ʾ������Ԫ��ɵ�Hopfield���磬Ҳ���Ը���ͼ1��15��ʾ��ͼ�α�ʾ��������ͼ�ε�������һ���ġ�������ɢHopfield�����һ���ڵ�״̬����Yj(t)��ʾ��j����Ԫ�����ڵ�j��ʱ��t��״̬����ڵ����һ��ʱ��(t+1)��״̬����������£�
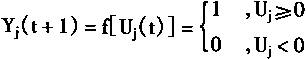
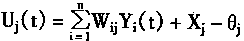
��Wij��i��jʱ����0����˵��һ����Ԫ����������ᷴ�������Լ������룻��ʱ����̵�HopfieId�����Ϊ���Է������硣
��Wij��i��jʱ������0����˵��������Ԫ������ᷴ�������Լ������룻��ʱ����ɢ��Hopfield�����Ϊ���Է��������硣

| |
ͼ1-15 ��ɢHopfield���������һ��ͼʾ | | ��ɢHopfield�����ж��ֲ�ͬ�Ĺ�����ʽ��
1������(�첽)��ʽ
��ʱ��tʱ��ֻ��ijһ����Ԫj��״̬�����仯��������n-1����Ԫ��״̬������ʱ�ƴ��й�����ʽ��������
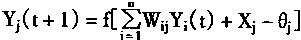
Yi(t+1)=Yj(t) i��j
�ڲ������ⲿ����ʱ������

2������(ͬ��)��ʽ
����һʱ��t�����е���Ԫ��״̬�������˱仯����Ʋ��й�����ʽ��������

�ڲ������ⲿ����ʱ������
j=1,2,...,n
����һ��������˵���ȶ�����һ���ش������ָ�ꡣ
������ɢHopfield���磬��״̬ΪY(t)��
Y(t)=[Y1(t),Y2(t),...,Yn(t)]T
����������κ���t>0�����������t��0��ʼ���г�ʼ״̬Y(0)����������ʱ��t���У�
Y(t+��t)=Y(t)
����������ȶ��ġ�
�ڴ��з�ʽ�µ��ȶ��Գ�֮Ϊ�����ȶ��ԡ�ͬ�����ڲ��з�ʽ���ȶ��Գ�֮Ϊ�����ȶ��ԡ����������ȶ�ʱ����״̬���ȶ�״̬��
����ɢ��Hopfield������Կ���������һ�ֶ����룬���з�ֵ�Ķ�ֵ�����Զ���ϵͳ���ڶ���ϵͳ�У�ƽ���ȶ�״̬��������Ϊϵͳ��ij����ʽ������������ϵͳ�˶������У�������ֵ���ϼ�С���������Сֵ��
��Hopfield��������һ��Lyapunov����������ν����������
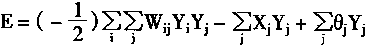
����
 |
(1-46) |
| ������Ԫj�������������ɱ�ʾΪ |
|
 |
(1-47) | | |
Ҳ������
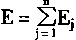
��Ԫj�������仯����ʾΪ��Ej��
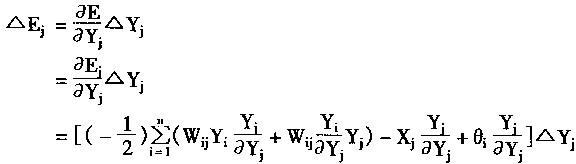 |
(1-48) | | |
����������� Wii=0,i=1,2,...,n
Wij=Wji i=1,2,...,n j=1,2,...,n
����
 |
(1-49) | | |
���У�EjΪ��Ԫj��������
��EjΪ��Ԫj�������仯��
WijΪ��Ԫi����Ԫj��Ȩϵ����
YiΪ��Ԫj�������
XjΪ��Ԫj���ⲿ���룻
��jΪ��Ԫj�ķ�ֵ��
��YjΪ��Ԫj������仯��
�������
Uj=��WijYi+Xj
����Ej�ɱ�ʾΪ��
�����������������
1�����Uj����j������Ԫj����������ֵ���ڷ�ֵ����Uj-��j��0����Ӷ�ֵ��Ԫ�ļ��㹫ʽ֪����Yj��ֵ����Ϊ1�����ߴ�0�䵽1����˵��Yj�ı仯��Yjֻ����0����ֵ����ʱ����������Ej��
��Ej��0
��˵��Hopfield������Ԫ���������ٻ䡣
2�����Uj����j������Ԫj����������ֵС�ڷ�ֵ����Uj-��j��0����Ӷ�ֵ��Ԫ�ļ��㹫ʽ��֪��Yj��ֵ����Ϊ0�����ߴ�1�䵽0����˵��Yj�ı仯��Yjֻ�������λ����ʱ������Ej��
��Ej��0
��Ҳ˵��Hopfield������Ԫ���������١�
��������˵����Hopfield������Ȩϵ������W�ĶԽ���Ԫ��Ϊ0������W����Ԫ�ضԳ�ʱ��Hopfield�������ȶ��ġ�
Coben��Grossberg��1983������˹���Hopfield�����ȶ��ij������������ָ����
���Hopfield�����Ȩϵ������w��һ���Գƾ����ң��Խ���Ԫ��Ϊ0��������������ȶ��ġ�����˵��Ȩϵ������W�У����
i=jʱ��Wij=0
i��jʱ��Wij=Wji
��Hopfield�������ȶ��ġ�
Ӧ��ָ������ֻ��Hopfield�����ȶ��ij�������������DZ�Ҫ��������ʵ�����кܶ��ȶ���Hopfield���磬�������Dz�������Ȩϵ������w�ǶԳƾ�����һ������
����ķ�����֪��
���Է�����Ȩϵ���Գ�Hopfield�������ȶ������硣����ͼ1��16��ͼ1��17��ʾ��

| |
ͼ1-16 �Խ���Ȩϵ��Ϊ0�ĶԳ�Hopfield����
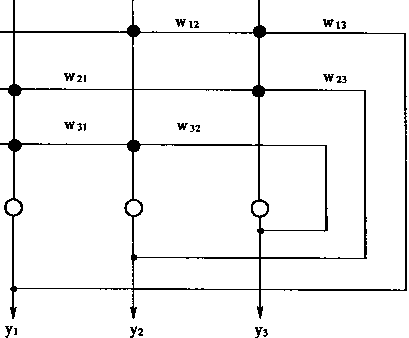
| |
ͼ1-17 �Խ���Ȩϵ��Ϊ0�ĶԳ�����һͼʾ | |
Hopfield�����һ�������ǿ�����������䣬Ҳ��������洢������������������ص�֮һ���������ν���������顱���Ǽ���һЩ��ͬ��ȥ�Ӵ��ľ�����ײ����Թ�ȥ�龰�Ļ�����˼�䡣����Hopfield���磬�������������ʱ������ͨ��һ��ѧϰѵ������ȷ�������е�Ȩϵ����ʹ���������Ϣ�������nά���������ijһ�����ǵ�������С���������Ȩϵ��ȷ��֮��ֻҪ�������������������������������Ǿֲ����ݣ�������ȫ�ֲ���ȷ�����ݣ�����������Ȼ�������������Ϣ�����������1984��Hopfield������һ����nάHopfield����������洢���Ľṹ������������У�Ȩϵ���ĸ�ֵ����Ϊ�洢����������洢����(out product storage prescription)����ԭ�����£�
����m�������洢����x1��x2������xm
X1={X11,X21,...,Xm1}
X2={X12,X22,...,Xm2}
......
Xm={Xm1,Xm2,...,Xmm}
����m�����������洢��Hopfield�����У����������е�i��j�����ڵ�֮��Ȩϵ����ֵΪ��
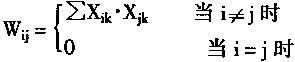
���У�kΪ��������Xk���±꣬k��1��2����m��
i��j�ֱ�����������Xk�ĵ�i��j����Xi��Xj���±ꣻi��j��1��2����n��
������洢������������������£�
����һ������X���������������ȡ�������еĴ洢���ݡ���ʱ��������
X={X1,X2,...Xn}
�ĸ�������x1��x2������xn�������Ӧ�Ľڵ�j��(j��1��2������n)����ڵ�����Ӧ�ij�ʼ״̬Yj(0)������
Yj(0)=Xj��j��1��2������n
���ţ���Hopfield�����а�����ѧϵͳԭ����м��㣬��
Yj(t+1)=f[��WijYj(0)-��j] , i,j��1��2������n
���У�f[��]�Ƿ����Ժ�������ȡ��Ծ������
ͨ��״̬���ϱ仯�����״̬���ȶ����������յ�״̬�Ǻ�������x��ӽ����������������ԣ�Hopfield������������Ҳ���Ǹ��������������������������˵������ʹ��������������ȫ�ֲ���ȷ��Ҳ���ҵ���ȷ�Ľ�����ڱ����ϣ���Ҳ���˲����ܡ�
1��3��2����Hopfield����
����Hopfield��������ӽṹ����ɢHopfield����Ľṹ��ͬ���������ӽṹ���������ϵͳ�д������ڵ�������·����һ�µġ�������Hopfield�����У�����ɢHopfield����һ�������ȶ�����ҲҪ��Wij=Wji��
����Hopfield�������ɢHopfield���粻ͬ�ĵط������亯��g���ǽ�Ծ����������S�ε�����������һ��ȡ
g(u)=1/(1+e-u) (1-50)
����Hopfield������ʱ�����������ģ����ԣ������и���Ԫ�Ǵ���ͬ����ʽ�����ġ����Ƕ���һ����ϸ��������Ԫj�����ڲ�Ĥ��λ״̬��uj��ʾ��ϸ��Ĥ�������ΪCj��ϸ��Ĥ�Ĵ��ݵ���ΪRj�������ѹΪVj���ⲿ���������Ij��ʾ��������Hopfield�������ͼ1��18��ʾ�ĵ�·��ʾ��
 |
(1-51) | | | ���У�n����������Ԫ�ĸ���
vj(t)������
Uj(t)������
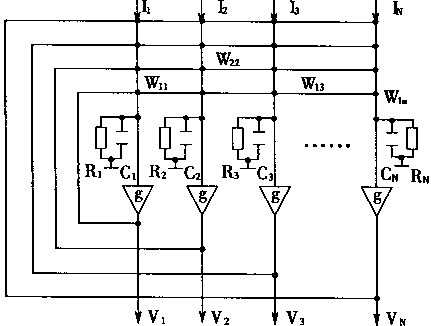
| |
ͼ1-18 ����Hopfield����ĵ�·��ʽ
��������Hopfield���磬Hopfield���������ȶ��Զ�����
������������E(t)
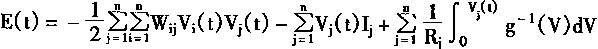 |
(1-52) | | |
���У�g-1(v)��Vj(t)��gj(uj(t))�ķ�������
�������Hopfield��������Ԫ���ݺ����ǵ����������������н纯��������Wij��Wji������
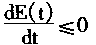
�����ҽ���
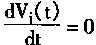
ʱ����
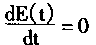
���������������Խ������£���������Ԫ�Ĵ��ݺ�����S��������������Ȩϵ������Գƣ�����ʱ��ı仯������������½��䣻���ҽ��������λ��ʱ��仯����ʱ������������Ż�䡣������֮�������������µ�����������������½��ġ�
���������֤���������£�
����������E(t)��ʱ��ĵ���dE(t)��dt������
 |
|
(1-53) | | |
�������Wij��Wji������ʽ��дΪ
 |
(1-54) |
| ������Hopfield����Ķ�̬���̣��� |
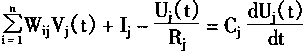 |
(1-55) |
| ������(1��54)ʽ��д�� |
|
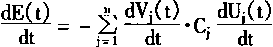 |
(1-56) |
| ���� Vj(t)=gj(Uj(t)) |
(1-57) |
| �ʶ��� Uj(t)=gj-1(Vj(t)) |
(1-58) |
| �Ӷ��� |
|
 |
(1-59) |
| �� g(u)=1/(1+exp(-u)) |
(1-60) | | |
��֪�䷴����Ϊ�������������������dE(t)��dt�е�gj-1(vj(t))�����е��������ص㣮���䵼���ض�����0����
[gj-1(vj(t))]'>0
ͬʱ����֪��
Cj>0
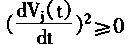
�����ԣ���dE(t)��dtʱ���ض���

���ҵ�������

��

���ˣ�����֤����ϡ�
�������˵��Hopfield�������������E(t)�ǵ����½��ģ����E(t)���½磬����ȷ���ļ�Сֵ����ô����ض����ȶ��ġ����ң�����֪���ȶ����Ӧ�������������½磬����Сֵ��
��һ��������ֻ��֤�������������½磬��ô���Ϳ���֤���������ȶ��ġ�
����֤�������Hopfield����Ĵ��ݺ���g�����������н�ģ���ô����������E(t)���н�ġ�
��������½��ۣ�
��Hopfield�������Ԫ���ݺ���g���������н�ģ�����Sigmoid���������������Ȩϵ������Գƣ����������Hopfield�������ȶ��ġ���ʵ��Ӧ���У��κ�һ��ϵͳ��������Ż������������������E(t)��ΪĿ�꺯������ô���ܿ���������Hopfield������������⡣����������������E(t)��Hopfieldʹ������������Ż�ֱ�Ӷ�Ӧ�����ֹ����Ǿ߿����Եġ���������������Ż����㣬��������������һ����ϵͳ������ʼ�Ĺ��Ƶ㣬����ʼ������Ȼ����������˶����ݶ��ҵ���Ӧ��С�㡣�������������Ż����ⶼ������������Hopfield������⡣��Ҳ��Hopfield������������Ļ���ԭ�� |
|
1��4��4 ARTģ�͵�ѧϰ�㷨 |
|
ARTģ����һ��������֯������������ģ�ͣ�����ͨ������������F2�н�����Ӧ������ģʽI�ı���ġ�
��F2���γɶ�Ӧ������ģʽI�ı��룻�ڱ����Ͼ��Ƕ��������ģʽI����ѧϰ��ʹ�����Ȩϵ��ȡ��ǡ���Ķ�Ӧֵ�����Ҫ����һ���Ĺ������ѧϰ�㷨����Ȩϵ�������ġ�
����ֱ��F1��F2��F2��F1��Ȩϵ��ѧϰ���̽��н��ܡ�
һ�����¶��ϵ�Ȩϵ��ѧϰ�㷨
��ν���¶��ϣ�Ҳ���Ǵ�F1��F2�ķ������¶��ϵ�Ȩϵ�����Ǵ�F1��F2��Ȩϵ����F1�е���Ԫ��Ni��ʾ��F2�е���Ԫ��Nj��ʾ�����F1����ԪNi��F2����ԪNj��Ȩϵ����wij��ʾ��
��ѧϰʱ��Ȩϵ��Wij������ķ�����������
 |
(1-63) | |
|
���У�f(xj)����ԪNj��F1������źţ�
h(Xi)����ԪNi��F2������źţ�
Eij�Dz�����
K1�Dz�����
���ڲ���Eij��һ�㰴��ʽѡȡ
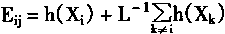 |
(1-64) | |
|
���У�LΪ����L-1��1/L��
���ȡK1Ϊ������������K1��KL����Ȩϵ��Wij���ַ��̿���д��

�������˵������F2������ԪNj�����Ϊ��ʱ������F1������ԪNi��������ź�������(1-Wij)Lh(Xi)Kf(Xj)��Ӱ��Ȩϵ��Wij�ĸı䡣
�����淽���У� ����������Ԫ��i��k������ź�h(Xk)���ܺͣ�����ź�Ҳ����F1�г�Ni���������������Ԫ��F2����ԪNj�������źš�ARTģ�;�������źŵĴ�С����ǿ��Nj���Ӧ������Ȩϵ���� ����������Ԫ��i��k������ź�h(Xk)���ܺͣ�����ź�Ҳ����F1�г�Ni���������������Ԫ��F2����ԪNj�������źš�ARTģ�;�������źŵĴ�С����ǿ��Nj���Ӧ������Ȩϵ����
�������϶��µ�Ȩϵ����ѧϰ�㷨
��F2��F1��Ȩϵ����Ϊ���϶��µ�Ȩϵ��������Wji��ʾ��Ȩϵ��Wji�������·��̣�
 |
(1-65) | |
|
���У�f(xj)����ԪNj��F1������źţ�
h(Xi)����ԪNi��F2������źţ�
K2��Eji�Dz�����һ���ȡK2��Eji-1
�����ԣ�Wji���ַ��̿���д����ʽ��
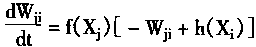
�����F2����ѧϰ�������ⲿ������F1�в���ƥ��ʱ��������ϵͳA�ͻ����һ�������ŵ���F2��ȥ���ı�F2��״̬��ȡ��ԭ����ѧϰ�����������Ȼ������ʱȡ����ϵͳ���ڹ���״̬������ģʽΪI������һ��nά����������n��Ԫ�ء���I���˵�ART�����F1��ʱ�����ͻ���m����С�̶�ΪP���źŵ�A�С�������������˵�A�����м����ź�Ϊn��P��ͬ����F1�е���ԪҲͬʱ����һ����С�̶�ΪQ�������ź��͵�A�У�F1�еļ���ģʽΪX������Ӧ�ڼ���ģʽX��F1��A�ļ������Ӹ���ΪI����ô����F1��A�����е������ź�ΪIQ�����������
n'p>IQ
��˵���������ô����������ã���ȡ����ϵͳA�ͻ��յ������źţ�������һ�������źŵ�F2�У���
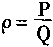 |
(1-67) | |
|
����Ϊȡ����ϵͳ�ľ����߲�����
������n'P>IQʱ��
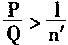 |
(1-68) |
| ��Ȼ�� |
 |
(1-69) | |
|
��ʱ����A����������źŵ�F2�����෴֮��
��A�������ź��͵�F2ʱ��F2�е���Ԫ���������ʽ����������
 |
(1-70) | |
|
���У�Tj�Ǵ�F1���ĵ�F2������ģʽ��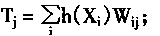
J��F2����Ԫ��һЩ���ϣ���Щ��Ԫ��ѧϰ������ĩ��������ֵ��
��ѧϰ�Ĺ����У�ÿ��ѧϰ���ڿ�ʼ��J��Ϊ(n+1��n+2������m)������ѧϰ���̵ļ����������������ÿ�εݹ鶼Ӧ��J����ȥһ��F2��Ԫ���±ֱ꣮����������ȷ��ƥ���ֹͣ��
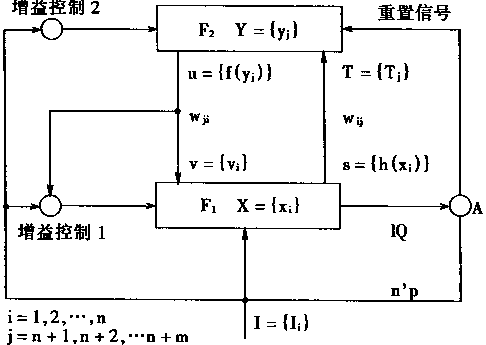
����Ӧ��������ģ��ART����ѧ�����Լ�ѧϰ�㷨�й����������ͼ1��26��ʾ�Ŀ�ͼ��ʾ��
|
|
ͼ1-26 ��ѧ�������㷨�й�ͼʾ |
|
1��4��5 ARTģ�͵�Lippmanѧϰ�㷨
ART�����ж���ѧϰ�㷨�����ⲿ�ֽ���Lippman��1987��������㷨������㷨�IJ��輰ִ�й������£�
һ����ʼ��
��ʼ��ʱ�Դ�F1��F2��Ȩϵ��Wij��F2��F1��Ȩϵ��Wji�Լ�����ֵP���г��趨��
1��F1��F2��Ȩϵ��wij��ʼ��
Wij�ij�ʼֵ����ʽ�趨��
 |
(1-71) | |
|
���У�nΪ��������I��Ԫ�ظ�����
LΪ����1�ij�����һ��ȡL��2��
Ϊ�˷��㣬��ֱ��ȡ��
 |
(1-72) | |
|
Wij(0)��ֵ����̫��̫����������ܰ�ʶ���F2��������Ԫ�������һ������ģʽ��
2��F2��F1��Ȩϵ��Wij��ʼ��
Wji�ij�ʼֵȡΪ1������
Wji(0)=1 (1-73)
Wji(0)��ֵ����̫С��̫С���±Ƚϲ�F1��ƥ�䡣
3������ֵP�ij�ʼ��
P��ֵ�����з�Χѡȡ��
0��P��1 (1-74)
P��ֵ��ѡ��Ҫǡ����P��ֵ̫����������ϸ������iP��ֵ̫С�������װ�����ij�����Ƶ�����ģʽ������ͬһ�ࡣ��ѧϰ�У�һ��ʼȡС��Pֵ�����дַ��ࣻȻ��������ֵP��������ϸ���ࡣ
��������һ���µ�ģʽ
��������ƥ��ȼ���
����ʶ�������������I�ķ�������Ϊ�˿�����������I��ʶ����ж�Ӧ����Ԫ��ص�Ȩϵ����̬�Ƿ�ƥ�䣬�ʶ�Ҫ����ƥ��̶ȡ���ʱ������ʶ���ÿ����Ԫj�ļ�����Yj��
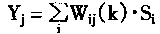 |
(1-75) | |
|
���У�YjΪʶ�����Ԫj�ļ���ֵ��
SiΪ�Ƚϲ���Ԫi�������
k��ѧϰ�Ĵ�����
�ġ�ѡ������ƥ����ԪC
ART������ʶ���ͨ���������ƣ��Ӷ�ʹ��ֻ�м���ֵ������Ԫc�������1��������Ԫ�����0����ԪC�ļ���ֵ��Yc��ʾ����
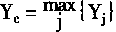 |
(1-76) |
| ����ʶ������Ԫ���ݺ���fΪ��Ծ�ͺ������������Uj |
|
 |
(1-77) | |
|
���У�Yj����Ԫj�ļ���ֵ��
��j����Ԫj�ķ�ֵ��
Uj����Ԫj�������
�塢�ȽϺ����龯��ֵ
ʶ������Ԫ��ѡ�������ƥ�����Ԫ֮������1������ʶ��Ƚϲ�����������0������2��3���Ƚϲ���U��I��Ԫ�ؾ�Ϊ1����Ԫ�����ȡ����ϵͳA��ԱȽϲ����������s����������I���бȽϣ���������ʵ��ھ���ֵP������ʶ��㷢�������źţ���ʶ���������㡣����S������I����������R��ʾ������
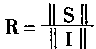 |
(1-78) | |
|
���У���S����s������Ԫ��ֵ֮�ͣ���s������Si��
��I����I������Ԫ��ֵ֮�ͣ���I��=��Ii
�����桬S���͡�I����ʵ�ʼ��㷽�����£�
S��101O1011 ��S����5
I=11111001 ��II��=6
���ڱȽϲ����s������������I��ʶ����������U��ͬ���ò����ģ�ͬʱ������Ԫc�����Ϊ1������U�ڱ������ǵ���ȡ������ƥ�����Ԫc��F2��F1��Ȩϵ������Wci��
��2/3������������ͬʱΪ1ʱ�������Ϊ1��������s��Ԫ��si���ɱ�ʾΪ��
Si=Wci.Ii (1-79)
�ʶ�
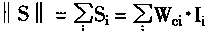 |
(1-80) | |
|
���������R���ھ�ֵP������
R>P
��ת����ߵ�ִ�У������������ִ�е����㡣
��������ƥ����Ч���䴦��
���������RС�ھ���ֵp����R
��ʱ�������źŵ�ʶ���ȥ����Ԫ��0����ԭ��ѡ�е�����ƥ����ԪΪ0��Ҳ˵��ȡ���˸���Ԫ����ʤ�ԣ��ѱȽϲ������������Ϊ���1��ת�������㣬�ظ�������̡�
��ʶ���һ����Ԫ��ȡ�õ������ʴ��ھ���ֵ����ת����ߵ㣬����������̡�
��ʶ����ȫ����Ԫ��������������û��һ����Ԫ��ƥ�䣬��ѧϰ��ȷ��ʶ��㡪����Ԫ��Ϊ����ģʽ������ƥ�䵥Ԫ��Ȼ��ֹͣ����ѧϰ���̣�������ģʽ���洢��������̽���ʱ�����F2��F1��Ȩϵ��ȫ��Ϊ1���Ƚϲ����S����I�������ʵ���1��
�ߡ���ѧϰ����
��ѧϰʱ������һ��ģʽ������������һ��˳����Ϊ�����������������ART�����Ȩϵ�����е�����ʹ����������������ʶ���ͬһ��Ԫ��
��ѧϰ�㷨���£�
1������F1��F2��Ȩϵ��Wij
���㹫ʽ���£�
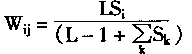 |
(1-81) | |
|
���У�Si�DZȽϲ��������S�ĵ�i��Ԫ�أ�
j��ʶ�������ƥ����Ԫ��ţ�
Wij�DZȽϲ���Ԫi��ʶ�����Ԫj֮���Ȩϵ��
L�Ǵ���1�ij�����
2������F2��F1��Ȩϵ��Wji
��Wji����Ϊ��������S����ӦԪ�صĶ�����ֵ��
Wji=Si (1-82)
��ʵ����Wij��Wjiʱ�����Բ����������Чʽ�ӡ�
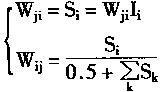 |
(1-83) |
| ���ǵ�ѧϰ����k��������ʽ��д�� |
|
 |
(1-84) | |
|
�����������������������ѧϰʱ��������Щ������Ԫ��ֵΪ0�Ķ�ӦȨϵ����0��������һ������ȫ��ѧϰ���ʱ��������������Ԫ�����ж��ٸ�0������Ӧλ���е�Ȩϵ��������0��ѧϰ֮�����洢��Ȩϵ����̬����ȫ�������ġ�������ʽ����ʱ��Ȩϵ����̬Ҳ��ȫ������������������Ȼ������ڳ�ȡ����ģʽ��������
3���Ƚϲ����S��1�ĸ���Խ�࣬���F1��F2��Ȩϵ��WijԽС��
��F1��F2��Ȩϵ��������ʽΪ��
 |
(1-85) | |
|
�ڷ�ĸ�У���Sk�DZȽϲ����S��1�ĸ���������ʾ������S�ġ���С������Ȼ����SkԽ����WijԽС��Ҳ���DZȽϲ����S�ġ���С����Ȩϵ��Wij���Զ��������á�
����һ����Ҫ�ص㣬�������б��������������У�����һ���Ƿ�����һ�����Ӽ���ART��������ѧϰ���̽���֮�����Զ����صڶ��㣻�Ӷ�����ʼ���������ģʽ���з��ࡣ
������Lippmanѧϰ�㷨�п��Կ���������һЩ�ص㣺
1��F2��F1t��Ȩϵ��Wij(0)�����ʼֵȡ1��
��Ϊ���Ƚϲ�����s������������I������ƥ����Ԫ��Ȩϵ��Wji����2/3���������ֻ��I��Wji��Ϊ1��s��Ԫ�زŻ�Ϊ1��
���Wji(0)��0����S��Ԫ�ػ�ȫ��Ϊ0����������ģʽʶ��
ʵ���ϣ�����������һ�������á�������������ƥ��Ĵ洢ģʽԪ�صĹ��̣�����һ��������Ĺ��̣�һ��Ȩϵ��ȡֵΪ0����ô��ѧϰ�㷨����ʹ����ȡ�����ֵ�ġ�
2����ȡ����ģʽ������
����һ�����Ƶ��������ᱻART������ʶ���F2�е�һ����Ԫʶ��Ϊͬһ�ࡣ
�����������Ƶ�����������ִ��ѧϰʱ����һ������ѧϰ�Ľ��ѡ��F2�е�һ����Ԫ�� | |
|
1��5 Kohonenģ�� |
|
�ڶ��������ϵͳ���Ե��о��У����Ƿ��֣����Ե�ijЩ�����ij����Ϣ��о����У������Ե�ijһ���ֽ��л�е�����ر���Ч����ijһ���ֽ��г���˼ά�ر���Ч���������ʹ���ǶԴ��Ե����õ���������ֲ�������������ʶ��
�Դ��Ե��о�˵�����������ɴ���Эͬ���õ���ԪȺ����ɵġ����Ե���������һ��ʮ�ָ��ӵķ���ϵͳ�������ϵͳ���и��ַ������ã������巴�����ֲ����������⣬���л�ѧ�������á��ڴ��Դ�����Ϣ�Ĺ����У��������伫����Ҫ�Ĺ��ܡ�����ͨ��������̴Ӷ�ʶ������źţ�����������֯���̡�
���ݴ��Զ��źŴ������ص㣬��1981�꣬T��Kohonen�����һ��������ģ�ͣ�Ҳ��������֯����ӳ��ģ��SOM(Seh��Organizing fenture Map)��
Kohonen��Ϊ�˵Ĵ����������ص㣺
1�����Ե���Ԫ��Ȼ�ڽṹ����ͬ���������ǵ�����ͬ��������ָ��Ԫλ�õ��ƶ�������ָ��Ԫ���йز��������������ⲿ����̼���ʶ������Ĺ����в����䶯��
2����������Ԫ�����ڱ䶯֮���γ��ض��IJ�����֯�����������ض�������֯��������������ض������ر����С�
3����������ѧ��������ѧ������Ƥ��ֳɶ��ֲ�ͬ�ľֲ�����������ֱ����ij��ר�ŵĹ��ܣ������������Ӿ���˼ά�ȡ�
4����������Ԫ���������Ŵ������������������Ϣ�Ĵ̼��£����Ͻ��ܴ����źţ�����ִ�о�����̣��γɾ�����Ϣ���Դ���Ƥ��Ĺ��ܲ�������֯���ã��γ��¹��ܡ�
Kohonen��˼���ڱ�������ϣ������й������Ϣ������������֯���γɸ�������⡣����һ��ϵͳ��˵������Ҫ���һ��ϵͳ���������Ϣ����ʱ���ڲ�����֯���γɶ�Ӧ��ʾ��ʽ��������������Ȩϵ��������
��������Ե������̺ʹ��Ե�����֯��������µġ��������������ɿ����Ե�������Ԫ��ɣ����ԣ���������֯�ɶ������Ϣ��ijһ���������е���ʽ��
1��5��1 ��Ԫ�IJ���ԭ��
Ŀǰ�����Ե��о�˵��������Ƥ���У���Ԫ�dz�2ά�ռ����еģ����������źź����������������֡��������������ͼ1��27��ʾ����ͼ�п��Կ��������ⲿ����������ͬһ����ķ������롣
ͼ1��27 ����������2ά�ṹʾͼ |
|
��Ԫ֮�����Ϣ������ʽ�кܶ��֣������о����������ڽ�����Ԫ֮��ľֲ������ķ�ʽ�Dz��������ֲ�����ʽ��������йع���
1���Է����źŵ���ԪΪԲ�ģ��Խ��ڵ���Ԫ�Ľ������ñ���Ϊ�˷��Բ෴����
2���Է����źŵ���ԪΪԲ�ģ���Զ�ڵ���Ԫ�Ľ������ñ���Ϊ�����Բ෴����
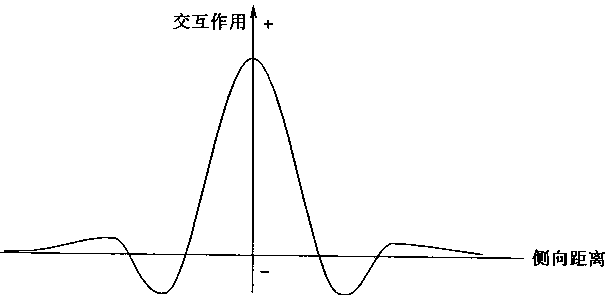
ͼ1-28 �ཻ��ģʽ |
|
���ֹ���˵���������������Զ��������ơ�һ����ԣ�������ָ�ӷ����źŵ���ԪΪԲ�ģ��뾶ԼΪ50��500µm���ҵ���Ԫ��Զ����ָ�뾶Ϊ200µm��2mm���ҵ���Ԫ����Զ�ڸ�Զ����Ԫ����ֵ������������á����������־ֲ�������ʽ��ͼ1��28��ʾ���������ֽ������õ�����������ī�����˴���ñ�ӣ�����Ҳ�����ֽ�����ʽΪ��ī����ñ����
�������У��ڽ��ĸ�����Ԫ֮��ͨ����IJ������ã��Ӷ������ྺ���Ĺ��̣�����Ӧ���γ������������Ϣ����֯�ṹ�������ԣ����ֽṹ���Գ�Ϊ���������Ϣ�����������������������������֯���̺���Ϊ�����Գ�Ϊһ�ּ����ֲ�ͬ��Ϣģʽ�ļ����ʶ��������Ҳ������֯����ӳ����������ڡ�
1��5��2��ά����SOMģ��
����֯����ӳ��SOMģ�Ϳ����ö�ά���б�ʾ�����ֽṹ��ͼ1-29��ʾ��
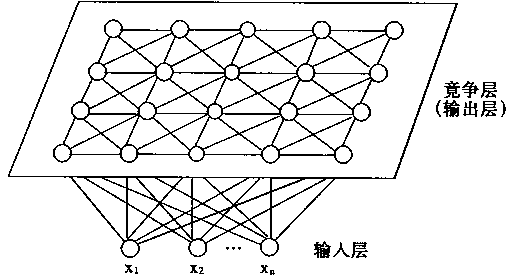
ͼ1-29 ��ά����SOMģ�� |
|
��ά�����������������;�������ɡ��������һά����Ԫ���������Ƕ�ά����Ԫ����������Ԫ�Ͷ�ά���о��������Ԫÿ��������ӡ���ά���о�����Ҳ������㡣
�ڶ�ά���о������У��������������ÿһ�������Ԫ����������ڵ�8����Ԫ��������Ȼ������ص���Ԫ��3��5����Ԫ����������ֻ������ص���Ԫ�Ż����������Ӷ�ά�����ڲ�һ���У�ÿ�������Ԫ��8�������ڵ���Ԫ��������SOMģ���У�������Ԫj�������ⲿ�����źſ�����Ij��ʾ��
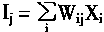 |
(1-86) | |
|
���У�xi���ⲿ�����źţ�
Wij��������Ԫi�������Ԫj֮���Ȩϵ����
����Ԫj��˵���������Yj�Ļ�����������ַ��̱�ʾ��
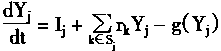 |
(1-87) | |
|
���У�Sj�Ǻ���Ԫj����ϵ����Ԫ�Ӽ���
rk��ϵ��������Ȩϵ���ͺ������ӽṹ�йأ�
g(Yj)�Ƿ�������ʧ������Ԫ���ͣ�������й©ЧӦ�ȡ�
��Ԫ�����������������1��30����ʾ��
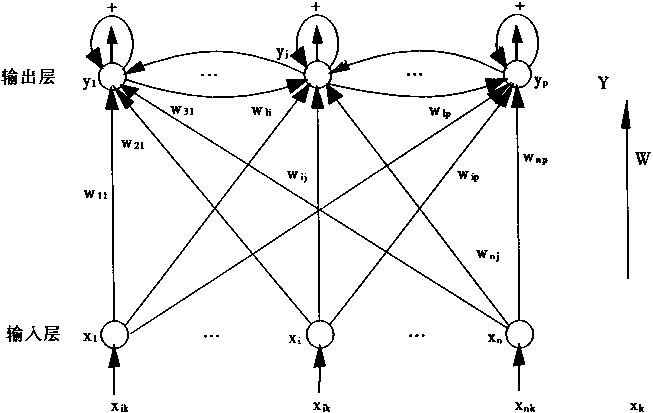
ͼ1-30 ��Ԫ��������� |
|
��Ԫ�����Yj�ij�ʼ�ֲ�����������ģ�������ʱ��ı仯�������������Ԫ�в��������ã�Yi�ķֲ��ͻ���Ի�������֯���γɡ����ݡ�״������״̬��ͼ1��28��ʾ��
���������У����ⲿ���������룬��Ԫ��Ȩϵ��������Ӧ�仯�ģ���һ���̾�����������ѧϰ�Ĺ��̡���Ԫ����Ӧ�����Ǻ������ֵ���ⲿ���룬Ȩϵ�����й�ϵ��һ�������·��̱�ʾ��
 |
(1-88) | |
|
���У�wj��Ȩϵ��������Wj��(W1j��W2j����Wnj)T��
X������������X��(X1��X2������Xn)T��
��,�������ı���������
��Ԫ������Ӧ���������γɵġ����ݡ����ڱ������Dz���������ģʽ���ڱ�ʾ��̬��
�����֡����ݡ������ض�����ԪcΪ���ĵģ���������һ���뾶����Χ����Ԫ�Ӽ�Nc�������
Yj��(0,1)
�¡�(0,��)
������
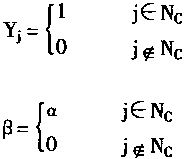
����ʵ����Ҫ����Ԫ���������İ뾶��Χ֮�ڵ�Nc�Ӽ���ʱ���������Ϊ1�������Ӽ�Nc֮��ʱ���������Ϊ0��ͬʱ��ϵ��������Ԫ����Nc֮��ʱ��ȡֵΪ��������ȡֵΪ0��
�����ԣ���ʱ����Ԫ����Ӧ���̱�ʾ���£�
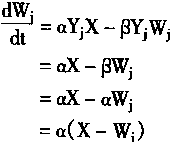 |
(1-89) |
|
����j��Nc��j/��Nc���������������֯���̿���������ͬ������ʽ�ӱ�ʾ�������� |
|
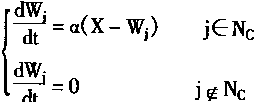 |
(1-90) | |
|
��ʽ˵����������֯�����У�SOMģ����Ԫ������λ�ö�ѧϰ�����Ӱ�졣����������ԪC�ľ���Ͻ����ڸ����뾶֮��ʱ��Ȩϵ��������ģʽ������Ȩϵ��Wj֮���һ��ˮƽ�����ģ�����ԪC�ľ����Զ����Ȩϵ�����䡣
1��5��3 SOMģ�͵�ѧϰ�㷨
���������SOMģ���У�ÿһ��Ȩϵ������������ Wj=(W1j��W2j��...Wnj)�����Կ������������һ���ڲ���ʾ�������������������X=(X1��X2��...��Xn)�����Ӧӳ��
SOMģ�Ϳ���ʵ������֯���ܡ�����֯��Ŀ�ľ���ͨ������Ȩϵ��Wij��ʹ������������һ�ֱ�ʾ��̬������һ��ʾ��̬�е�һ����Ԫֻ��ij������ģʽ�ر�ƥ����ر�
���С�������֮������֯ӳ���Ŀ�ľ���ʹ��Ԫ��Ȩϵ������̬��ʾ���Լ��ģ��������ź�ģʽ��
����֯����ӳ��SOM��ѧϰ�㷨������������ɵģ�������������
1������ƥ����Ԫ��ѡ��
2��������Ȩϵ��������֯���̡�
�������������ɵģ����ǹ�ͬ���ò����������֯����ӳ���ѧϰ���̡�ѡ������ƥ����Ԫʵ����ѡ������ģʽ��Ӧ��������ԪC��Ȩϵ��������֯���������ԡ�ī����ñ������̬��ʹ����ģʽ���Դ�š�
ÿִ��һ��ѧϰ����SOM�����оͻ���ⲿ����ģʽִ��һ������֯��Ӧ���̣�������ǿ������ģʽ��ӳ����̬����������ģʽ��ӳ����̬������ֱ������֯����ӳ��SOM��ѧϰ�㷨�������ֽ��н��ܡ�
һ������ƥ����Ԫ��ѡ��
��������ģʽx
x��(x1��x2������xn)T
��������֯����ӳ��SOM������������Ԫj������Ȩϵ������Wj
Wj=(W1j,W2j,...Wnj)T j=1,2,...,n
Ȩϵ�������Ƕ�����ģʽ��ӳ�䣬Ҳ����˵��Ȩϵ������ijһ��̬��Ӧ��ijһ����ģʽ������ģʽx��Ȩϵ��Wj��ƥ��̶��������ߵ��ڻ���ʾ�ģ�����XTWj��ʾ���ڻ�������ǡ����ݡ����ġ��ڻ�xTwj���ʱ����ض���x��Wj֮���������ķ�����x��Wj����С�������С�����ȷ��������ƥ�����ԪC���Ӷ��С����ݡ�����C�����㣺
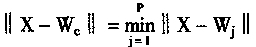 |
(1-91) | |
|
���У�Wc����Ԫc��Ȩϵ��������
���ʽ��Ҳ����ƥ�����
����ʽ��˵�����������ľ�����ԪC������Ȩϵ������Wcͬ����ģʽx������ƥ�䡣
ע����x��Wj����ŷ����¾��롣��������ʽ�������
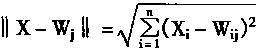 |
(1-92) | |
|
����ƥ����������Wc����ԪC��Ȩϵ��������������CΪ���ĵ����ݵ�һ�ֱ�ʾ��̬��Wc�ı�ʾ��̬���Ǻ�����ģʽx������ƥ�䡣һ���wc��x������ƥ�䡣�����Wc֮��Ҳ�����������������C�����ţ��Ϳ��Կ��Ƕ���ԪCΪ���ĵ�����Nc�й���Ԫ��Ȩϵ��������֯���̡���Ϊ��Wc��Ȼ������Ķ�����ģʽx������ƥ�䣻��wc��Ȼ���dz�ֱ�ʾX��Ϊ��ʹ���ܹ��ڸĽ�֮������̬�ܳ�ֱ�ʾx���ʻ�Ӧ��Ȩϵ������Wc��������֯ѧϰ�����������γɶ�Ӧx�����ݡ�
��������Ȩϵ��������֯
��SOM�����У�ÿһ�������Ԫ��������ͬ������ģʽX�����������Ԫj��˵���������������Եģ����ң���������ʽ��ʾ��
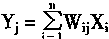 |
(1-93) |
|
��Ȩϵ����������֯ѧϰʱ��Ȩϵ���ĵ����������£� |
|
 |
(1-94) | |
|
���У�Y(t)����ʱ��t�仯�ĵݼ����溯����
Yj(t)�������Ԫi�������
Xi(t)��������Ԫi�����ˣ�
Wij(t)��������Ԫi�������Ԫj��ʱ��tʱ��Ȩϵ����
r�dz�ϵ����
��������������Ԫc������Ϊ���Ŀ���һ���ڽ�������Nc��Nc������ԪCΪ���ĵ�ijһ�뾶��Χ��ȫ����Ԫ�ļ��ϡ�
��Nc����֮�ڣ�������Ԫ�����Ϊ1����Nc����֮�⣬������Ԫ�����Ϊ0������
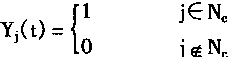
����ϵ��rΪ1����
r=1
��Ȩϵ���ĵ������̳�Ϊ
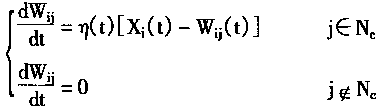 |
(1-95) | |
|
ͼ1-31 �ڽ�����Nc��ʱ��ı仯 |
|
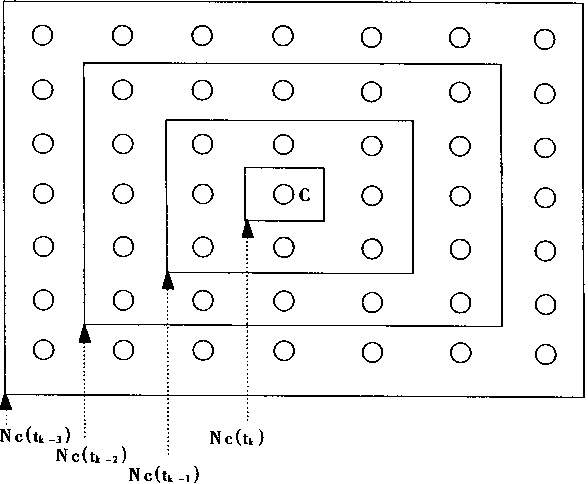
����Nc�ķ�Χ������ʱ��ģ��ڿ�ʼʱ����ѡ��Χ��һЩ��ͨ������Ϊ������ȵ�һ�����ϣ�����ʱ������ƣ�Nc����CΪ���ĵ�С��Χ������С��������������ս�����ԪC������Nc��{C}��
�ڽ�����Nc��ʱ����仯��ʾ��ͼ��ͼ1��31����ʾ����ͼ�п��Կ���Nc(tk-1)ʱ�ķ�Χ��Nc(tk-2)ʱҪС��Ҳ����˵����ʱ������������ǵ��ڽ������С��������ʱ��tkʱ���ڽ�����Nk������Ԫc����Ҳ��������������λ�á�
����ʽ(1��95)��Ȩϵ���������̿���дΪ������ʽ
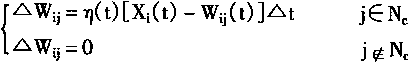
����ɢϵͳ�У�����ԡ�tΪ��������T�����С�t��1T�����ԣ�Ȩϵ������������д��

������ɢϵͳ�е�Ȩϵ������Ϊ��ַ��̣�
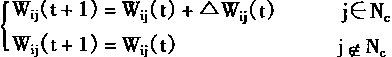
���ǣ�
 |
(1-96) | |
|
�����Ȩϵ������֯����ɢ���ֱ���ʽ��
�������溯����(t)���ԣ�����һ����ʱ��仯�ĵݼ�������һ��Ҫ��
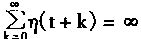

ʵ������
0<��(t+k)<1 k=1,2,...,��
��ʵ�ʵ�Ȩϵ������֯�����У���������ϵͳ��ȡ��

����
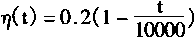
������ɢϵͳ����ȡ

����
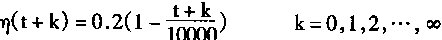
��������Կ���������������ϵͳ������ɢϵͳ����ʱ������ӻ�������ڵ����ƣ����溯��7��ֵ��Խ��ԽС��ͨ��ȡ500��t��10000��500��t+k��10000ʱ����������֯���̡�
1��5��4 SOMģ��ѧϰ�ľ��岽��
�ڼ�����п��Բ�ȡһ����ǡ�����������֯����ӳ��ģ��SOM����ѧϰ����Щ����������£�
һ��Ȩϵ����ʼ��
������n��������Ԫ��P�������Ԫ��SOM���磬������������Ԫ�������Ԫ֮���Ȩϵ���趨ΪС�������a��һ���У�
0
ͬʱ���趨�ڽ�����ij�ʼ�뾶��
��������һ���µ�����ģʽXk
Xk={X1k,X2k,...Xnk}
k=1,2,...
������ģʽXk�����еij���Ԫ�ľ���
���������Ԫj�������ض�������ģʽXk֮��ľ�����djk��ʾ��������
 |
(1-97) |
| j=1,2,...,p |
| |
|
�ġ�ѡ������ƥ��������ԪC
������ģʽXk�ľ�����С����Ԫ��������ƥ��������Ԫc��
��Wc��ʾ��ԪC��������Ԫ��Ȩϵ����������Ӧ��
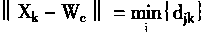 |
(1-98) | |
|
�塢����Ȩϵ��
�����趨���ڽ�����ݼ���С�����������Nc�е���Ԫ����Ȩϵ��������
��������ʽִ��
Wij(t+1)=Wij(t)+��(t)[Xi(t)-Wij(t)] (1-99)
��������Nc�����Ԫ����Ȩϵ�����䣬����
Wij(t+1)=Wij(t) (1-100)
���У���(t)�ǵݼ������溯����������0<��(t)<1��
ͨ��ȡ��
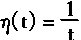 |
(1-101) |
| �� |
|
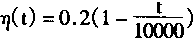 |
(1-102) | |
|
�������ڲ�ͬ��t��1��2������z(500��z��10000)�����·��ص�2��ȥִ�С�
������֯����ӳ��ģ�͵�ѧϰ�У���Nc��ֹ����һ����Ԫʱ�����־���ѧϰʵ������й©����ѧϰ��
��ѧϰ�У����溯����(t)Ҳ����ѧϰ�ʡ�����ѧϰ�ʦ�(t)��ʱ������Ӷ����������㣮��ˣ���֤��ѧϰ���̱�Ȼ�������ġ�
����֯����ӳ�������ѧϰ��һ����ʦ��ѧϰ�������ź�ģʽ�ǻ������и����ģ���������Ϊ�����ġ���Ȼ������ѧϰҲ�������н�ʦ�ģ���ʱ������Ϊ������ʦ�ź���Ϊ������Mģ���ڼ���ʱ�ǰ����淽ʽ������ģʽ���з���ģ�
���ȶ����������ģʽx�����ҳ���������к�����Ա��ƥ�����ԪC�����ʾ����ģʽx������Ԫc����Ӧ�����
SOM����ѧϰ�IJ��������¶��㣺
��һ��������ģʽ����ʱ��������������ģʽ������Ⱥ����
�ڶ�����ART���粻һ����SOM������û�о�������������ѧϰ֮ǰ�����ܼ����µ����
Kohonen�Ѿ�֤������ѧϰ����ʱ��ÿ��Ȩϵ������wj���������뵽����Ԫj����Ӧ����������ģʽ�ռ�����ģ�������ΪȨϵ������wj�γ����������ģʽ�ռ�ĸ��ʽṹ�����ԣ�Ȩϵ������Wj����Ϊ�������ģʽ�����Ųο�������
����֯����ӳ�������������������ã����Ժ������������ݵ���������Ҳ����ѧϰ������������ |
|
�ڶ��� ��������� |
|
��������Ƶ��о�ʼ��20����60�����1960�꣬widrow��Hoff���Ȱ����������ڿ���ϵͳ�� Kilmer��McCulloch�����KMB������ģ�ͣ����ڡ������ޡ����¼ƻ���Ӧ��ȡ�����õ�Ч����1964�꣬widrow�����������С��������ϵͳ����ȡ���˳ɹ���70����������о����ڵȣ��������������û���ٷ�չ����80������ڿ�ʼ������������������Ʒ�չ�����ܵ����ӣ������������������Ӧ���Ʒ����ϡ�Ŀǰ���������ܿ�����ȵķ���չ��
��������ƿ��Է�Ϊ���ӿ��ƣ�����ƣ�����Ӧ���ƣ�ʵ�÷������ƺ���Ӧ���ۿ��Ƶȡ�
�����ܿ���ϵͳ�У�����Ҫ�������㡣һ���Ǻ�֪ʶ���йص��������ͣ����������滷���仯����Ӧ������һ����ԣ��������Է���ΪԪ��ִ�еģ����������е��ź�����ֵ��Ϊ��������̵�״̬����Ҫʵʩ��ֵ���ݵ��������ݵ�ӳ�䣬���Ҫ����ֵ���ݽ��з��ࡣ
���⣬�Թ��̵Ŀ�����Ҫ����Ӧ��������������ķ���ܺ�ѧϰ����ʹ����������Ч���������ܿ���ϵͳ��
���������ڿ���ϵͳ�ǡ��ᄀ���á��ı�Ȼ�����Ŀǰ���������ڸ��ֿ���ϵͳ��Ӧ�ü������������2��1��ʾ��
��2-1 ��������Ƹſ� |
| ���Ʒ��� |
������ |
�������� |
| ����Ӧ���Կ��� |
Hopfield
��
ART�� |
Chi��(1990)
Zak(1990)
Kumar,Gucz(1990) |
| ����Ӧ�����Կ��� |
BP
��
��
��
Kohonen
��
CMAC |
Goldberg��(1998)
Bassi��Beckey(1989)
Sanner,Akin(1990)
Ungar��(1990)
Graf��(1988)
Martinez��(1988)
Atkenson��(1989) | |
|
2��1 ���������ϵͳ�Ľṹ
������ķ����ԣ�ѧϰ���ܣ����д������ۺ�������ʹ����ʮ�����������ܿ��ƣ����������ϵͳ����ʽ�ܶࡣӢ��Glasgow��ѧK.J.Hunt�����������ϵͳ��Ϊ���ӿ��ơ�ֱ������ơ�ģ�Ͳο����ơ��ڲ�ģ�Ϳ��ơ�Ԥ����ơ���Ӧ���Ƶȡ�IEEE������Э����濯����ϯToshio Fukuda���ں͡�����Ӧ���ֲᡱ����P.J.Werbos������������ϵͳ��Ҫ�ֳ���������ࣺ
1�����ӿ���(Supervised Control)
2�������(Inverse Control)
3������Ӧ����(Neural Adaptive Control)
4��ʵ�÷��ʴ�������(Back��propagation of Utility)
5����Ӧ���ۿ���(Adaptive Critics)
�����������Ļ�����������������ϵͳ�����ͬ�Ľṹ�����ң��������ڿ���ϵͳ�е�λ�ú�����������ѧϰ����Ҳ���졣 |
|
2.1.1���ӿ���ϵͳ
��������ģ���˵����ö���ɵĿ�����ȥ�Ա��ض���ִ�п��Ƴ�Ϊ���ӿ��ơ��ںܶ�����У����ǿ��Ը��ݶ�������״̬���ṩǡ���Ŀ����źţ��Ӷ�ʵ�����õĿ��ƣ�Ҳ����˵������ϵͳ����ִ�з����������á���������������У���ȡ�ö���ķ���ģ�ͣ�Ҳ����˵���ñ��Ŀ��Ƽ�������Ƴ����ʵĿ�������
���ӽ���ƽ���ר��ϵͳ���������ṩ֪ʶ����Ϳ�����ʽ�����ԣ��������������ģ���˵����õĿ������С����ӿ���ϵͳ�Ľṹ��ͼ2��1����ʾ����ͼ�п�֪��������Ĺ�������ȡ���˵Ŀ������á�

ͼ2-1 ���ӿ���ϵͳ�Ľṹ |
|
�ڼ��ӿ���ϵͳ�У���������Ҫ�ѻ�����ѵ����ѵ��ʱ�Dz���һϵ��ʾ�����ݵģ���Щ����������ִ���˹�����ʱ������������ݡ���������һ���Ǵ����������������ݣ����������������ȷ�������ݡ�Ҳ����˵���������ѧϰ��ִ�д������뵽�˹��������õ�Ӱ�䡣���ֿ����ڻ����˿��Ƶ����������൱������á�
2.1.2 �����ϵͳ
�����ϵͳ��ʱҲ��ֱ�������ϵͳ���������ϵͳ�У�������ض����ģ����F��ʾ����ô�������������ɵĿ�������ģ������F-1��Ҳ����˵��һ����ģ�͡������ϵͳ�Ľṹ��ͼ2��2��ʾ��

ͼ2-2 �����ϵͳ�Ľṹ |
|
������ض����ģ�Ϳ��Ա�ʾΪF
y=F(u) (2.1)
��ô�������ϵͳ���������������ģ����ΪF-1��
u=F-1(y) (2.2)
��ʵ���ϣ����ض��������һ��δ֪��ϵͳ���ڱ��ض�������˼���u*����������ͻ����y*����y*��Ϊ���ˣ�u*��Ϊ���ȥ�����������ѵ������õ�����������DZ��ض������ģ�͡���ѵ��ʱ���������ʵ�������u����ʾ������(u'-u*)���ƫ����Կ��������ѵ�����̡�
һ����˵��Ϊ�˻�ȡ���õ��涯��ѧ���ܣ�ͨ����ѵ��������ʱ��ȡֵ�ķ�Χ��ʵ�ʶ��������������ݵ�ȡֵ��ΧҪ��һЩ��
�������ϵͳ��������ֱ�����ڿ��ƻ�·��Ϊ�������á������Ч�����ص������ڿ������Զ�������ģ�͵���ʵ�̶ȡ���������ϵͳȱ�ٷ������ڣ����ԣ���³�����������㡣����Ҫ���С���³���Ե�Ӧ��Ŀ�ģ����ֿ���ϵͳ��������⡣
һ����ԣ�ͨ������ѧϰ������һ���̶ȿ˷���³���Բ��õ����⡣����������ѧϰ������У�����ѧϰ���Ե���������IJ�����ʹ���������ģ�͵���ʵ����ߡ�ֱ��������ڻ�������Ӧ�ý�Ϊ�㷺��
2��1��3 ����Ӧ����ϵͳ
����Ӧ�����ǰ����������ڴ�ͳ��Ӧ���Ʒ������������µĿ��Ʒ�����
����Ӧ���������ֻ�����ʽ��һ����ģ�Ͳο���Ӧ���ƣ�һ����У����������
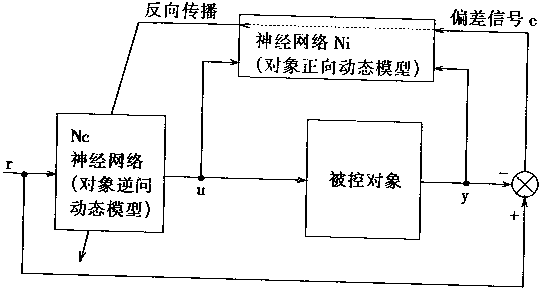
������ģ�Ͳο���Ӧ����ϵͳ�Ľṹ��ͼ2��3��ʾ�����ɲο�ģ��M�������Զ���P��������Nc��������Ni���ĸ���Ҫ������ɡ�
������ģ�Ͳο���Ӧ���Ƽ��NMRAC(Neural Model Reference Adaptive Control)����ϵͳ�ṹ�У��ο�ģ��M������ģ�ͣ������ym������������ο�ģ��M����ʽ������
M={r(t),ym(t)} (2.3)

ͼ2-3 ������ģ�Ͳο���Ӧ����ϵͳ�Ľṹ |
|
������Ni�Ƿ����Զ���P�ı�ʶ��������Ҫ�����ö���P��ǰ����ǰʱ�̵��������������Ԥ����һʱ�̶���������Ԥ�����Yp�Ͷ������yp�IJ���ei��ӳ��Ԥ����ȷ�ȣ�
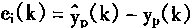 |
(2.4) | |
|
������Nc�ǿ����������������������������������ź�r��������ʱ�̵Ŀ����ź�u��Ncͨ����Ni�Զ����ʶ֮�����õ��Ķ�����ģ�͡�
NMRAC���Ƶ�Ŀ�����ڲ���һ��ǡ���Ŀ����ź�u(k)��ʹ�������yp�Ͳο�ģ�͵����ym��ƫ��С�ڸ������ֵc����
 |
(2.5) |
|
yp��ym��ƫ����ec����ʾ������д��ʽ�� |
|
| ec(k)=yp(k)-ym(k) |
(2.6) | |
|
���ec��0����˵���ƽ��������ֵһ������NMRAC����ϵͳ�У����ȶԱ�ʶ��Ni����ѵ����Ԥ��ƫ��ei����ѵ��Ni�����ѧϰ֮��Ni�ܾ�ȷ����������P����P����ģ�ʹ��ڣ���ô������Ni���yp(k+1)��
(2.7)
��ο�ģ��Ϊ
ym(k+1)=h[ym(k),ym(k-1),......ym(k-s)]+r(k) (2.8)
������ģ��
��ym(k+1)ȡ��yp(k+1)������ʽ(2��9)��
u(k)=g-1{h[ym(k),ym(k-1),......,ym(k-s)]+r(k)-f[yp(k),yp(k-1),......,yp(k-n)]}-g'[u(k-1),......,u(k-m)] (2.10)
Ϊ�˹��ɿ��������ö������ypȡ��ʽ(2��10)�еIJο�ģ�����ym����
u(k)=g-1{h[yp(k),yp(k-1),......,yp(k-s)]+r(k)-f[yp(k),yp(k-1),......,yp(k-n)]}-g'[u(k-1),......,u(k-m)] (2.11)
��ʽ(2��11)�Ϳ�����������������Ne����Ȼ��������Nc����������������ɣ����Ǹ���r(t)���������yp(t)�Ϳ����������u(t)��
�������P����ģ��������ʽ(2��9)��ʾ����ô�������ñ�ʶ��Ni������Ͳο�ģ��M�����ƫ����߶�������Ͳο�ģ�͵�ƫ��ec��yp(k)��ym(k)��������Nc����ѵ�����Ӷ�����ȷ��Nc��
��������У�����Ƽ��NSTC(Neural Self-Tuning Control)�������ֿ��Ʒ�ʽ�У���������һ����У����������
�����ģ�ͺ�ʽ(2��7)ʽͬ������
yp(k+1)=f[yp(k),yp(k-1),......,yp(k-n)]+g[u(k),u(k-1),......,u(k-m)] (2.12)
����������ģ�ʹ��ڣ����
u(k)��g-1{yp(k+1)-f[yp(k),yp(k-1),......yp(k-n)]}-g'[u(k-1),......,u(k-m)] (2.13)
��g-1[��]��g��[��]δ֪ʱ�����Բ�������������ͨ��ѧϰ���ƽ��������õ�����
�����������һ����У�������������ϵͳ����NSTCϵͳ����ϵͳ�У�Ҫ��yp(k+1)��I(k+1)�ƽ����ʶ���ʽ(2.13)��д�ɣ�
u(k)=g-1{r(k+1)-f[yp(k),yp(k-1),......,yp(k-n)]}-g'[u(k-1),......,u(k-m)] (2.14)
NSTCϵͳ�Ľṹ��ͼ2��4��ʾ��������
ͼ2-4 NSTCϵͳ�Ľṹ |
|
�����������Nc�dz�ʵ��g����g���ܵ�����������ɵġ�ѧϰѵ��ʱ����ƫ����
��ep��
ep=r(k+1)-yp(k+1)
���������������ģ�͵ıƽ��̶ȡ�
2��1��4 ʵ�÷������ƺ���Ӧ���ۿ���
ʵ�÷������ƺ���Ӧ���ۿ�������������ʵ�����ſ��Ƶ�ͨ�÷����������ַ������Ų�ͬ��˼�롣
һ��ʵ�÷���(Back-propagation of utility)����
ʵ�÷�������ʱ�䷴����һ����չ�㷨����Werbos�������ʱ�䷴��
(Back��Propagation through time)��һ��ͨ������ѵ��ѭ��������㷨����������Ϸ�չ��
ʵ�÷����ڿ���ϵͳ�Ͽ����γɼ�������ϵͳ������ϵͳ��ͼ2��5��ʾ��
������ϵͳ�У�һ��������ģ��������ִ������ʱ�������һ�����������
ģ������������������ġ������ԣ��ڿ���ϵͳ�У����������ģ��Ni�������ǽ�
�����ش�����ʵ��Ӧ���У����ַ������ڡ�Щ���⣻��Ȼ���������ź���ͨ������ģ
�͵ģ����ԣ�ʵ�÷����㷨��Ҫһ�����õ�ģ�͡����ǣ�Ҫ�������罨��һ���õ�ģ
�Ͳ��ǡ��������¡�
ͼ2-5 ʵ�÷������� |
|
ʵ�÷�����ĿǰҪ��������������һ�����ѣ����ǣ�����ҵ�ǡ��־��ж��Ӧ��DZ���ķ�����
������Ӧ���ۿ���
��Ӧ����(Adaptive Critics)��������ǿѧϰ(Reinforcement Learning)�����䷽������ǿѧϰ��Barto����������ģ���������������ִ�й�������Ӧ���ۿ��ƵĽṹ��ͼ2-6��ʾ��

ͼ2-6 ��Ӧ�������� |
|
��Ӧ���۵�ѧϰ������һ������������ԪASE(Associative Search Element)��һ����Ӧ���۵�Ԫ(Adaptive Critic Element)��ɡ���ѧϰʱ��ASE����ǿ������Ӱ����ͨ��������ȡ�����������������ϵ��ACE���ɱ���ǿ�������������ṩ�ĸ��ḻ����Ϣ���ۺ�����������ѧϰ�㷨�У�ASE���������磻ACE���������磻�������豻�ع��̵�ģ�͡�
����������������ɵ���Ӧ�����㷨 �Ѿ��ںܶ�С�Ŀ���������ȡ���˺ܺõ�Ч�������ǣ��������۵����J���ڱ�ʾ��Ч����Ҳ����ʾ���۽���������۽��������ȷ������������ѧϰ��Ѱ�ŵķ������ԣ��ڴ�Ŀ�������и������ѡ�
��ʵ�÷���һ������Ӧ������Ŀǰ�����ڲ������ѣ�����������һ����DZ���ķ����� |
|
2��2 �������������ѧϰ |
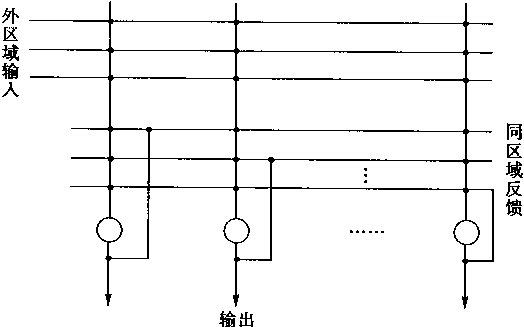
|
�����������ϵͳ�У���ʱ��Ҫ�Զ�����з��棻���ԣ���ϵͳ�����������������NPE(Neural Plant Emulator)��ͬʱ����ϵͳ�л���������NC(Neural Controller)�����۶��������PC������������NC������Ҫѧϰ�������ڿ���ϵͳ�У�����ѧϰ������Ҫ�ġ�����һ���У����ܶ������������������ѧϰѵ���Ľṹ������ѧϰ�������㷨��
2��2��1 �����������������
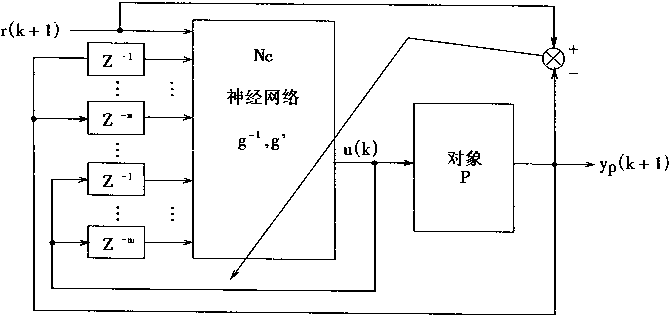
�ڿ����У��������ö��ǰ�������硣���������MNN(Multilayer Neural Network)������Ϊ��һ����ӳ��ѧϰ�����Ľṹ������ӳ���������õ�����ͨ�õ����ƽṹ�������������PE��������NC��
����һ�������˵�����Ĺ��̣������ֿ��Ƽ�����֪��������ɢ��ѧģ�ͣ�
y(k+1)=f[y(k),y(k-1),......,y(k-P+1),u(k),u(k-1),......,u(k-Q)] (2.15)
���У�y�������u�����룬k����ɢʱ��ϵ����P��Q����������f[��]�Ǻ�����
�ںܶ�����У�����������ź�u���ڷ����Ϸ�Χ���ģ��ȴ�������um������uM�����κ�k����
um��u(k)��uM (2.16)
�����������ʽ(2��15)�У���ӦP��Q�Ĺ���ֵ�ֱ���P��q��ʾ��
һ�����������PE
���������PE�����ú�������ͼ2��7��ʾ�����У�ͼ2��7(a)��ʾPE�ڰ���ϵͳ�Ͷ���֮��Ĺ�ϵ��ͼ2��7(b)��ʾPE�Ŀ�ͼ����ͼ��u(k)Z-1��u(k-1)��һ���ģ�z-1����ʱ���ӣ�����������ʱһ�ģ�����ʱһ���������ڡ�
��ͼ�п������ö��������MNN��ɵ�PE��p+q+1=m�����룬һ����������������ڶ�ʽ(2��15)�����Ķ�����з��档PE��ӳ�书����E(.)��ʾ�������yE��ʾ������Ϊmά����XE(k)����
XE(k)=[y(k),......,y(k-p+1),u(k),......,u(k-q)]T (2��17)
�������PE�����
yE=��E(XE) (2.18)
�Է���������ѵ����Ӧʹ�������eE
eE=y(k+1)-yE
�ﵽ��С��

(a) |

(b) | |
|
ͼ2-7 ���������PE |
|
����������NC
������NC�����ú�������ͼ2-8��ʾ��ͼ2-8(a)��NC��ϵͳ�е�λ�ã�ͼ2-8(b)��NC��ͼ��
�ٶ���ʽ(2��15)�������Ĺ��̶����ǿ���ģ������ں���g[��]��������
u(k)=g[y(k+1),y(k),......,y(k-p+1),u(k-1),u(k-2),......,u(k-Q)] (2.19)
���������ʵ��ʽ(2��19)�������Ķ�����ģ�͡����ң�����Ϊmά����Xc�����ΪUc������������ϵ��ʾΪ
Uc=��c(Xc) (2.20)
���У���cΪ�������ӳ�䡣
�����c(��)������ƽ�g(��)�����������ģ�͵���������Կ����ǿ���������kʱ�̣���������xc(k)Ϊ
Xc(k)=[r(k+1),y(k),......,y(k-p+1),u(k-1)...,u(k-q)]T (2.21)
����ʽ(2��21)�У��Ը�������r(k+1)ȡ��δ֪��y(k+1)��p��q�ֱ���P��Q�Ĺ���ֵ��
����ʽ(2��20)���������������NC�����
uc(k)=��c[r(k+1),y(k),...,y(k-p+1),u(k-1),...,u(k-q)] (2.22)
�������������NC��ѵ���������ʹ���ƫ��e(k)��r(k)-y(k)����Ϊһ����С��ֵʱ������
Xc(k)=[r(k+1),r(k),...,r(k-p+1),u(k-1),...,u(k-q)]T (2.23)
����ʽ�У�����r(t)ȡ��y(t)�����ʽ������ͻ�������������NC��ǰ�����ԡ�
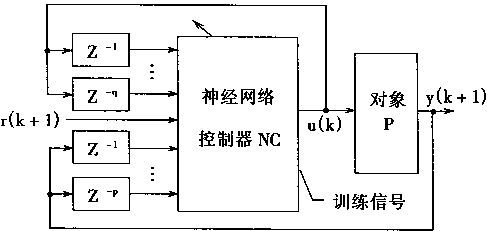
(a) |
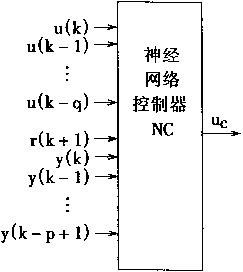
(b) | |
|
ͼ2-8 ������NC
2��2��2ѧϰѵ���Ľṹ
���������������ѵ���У�һ��Ҫ����������ƫ��e(k)��r(k)��y(k)�������ƫ���J��С����Ϊ���ܲ����ݶȷ�����ѧϰ��ͬʱ���迼��J��NC������֣�����=��3J��Juc����S֮��ͨ��BP�㷨�Ϳ��Ը���NC��Ȩϵ���������ֻ����ϣ�����ֱ������ƣ�ֱ����Ӧ���ƺͼ����Ӧ���Ƶ�ѵ�½ṹ��ֱ��������е������������NC�Ƕ������ģ�͡���ˣ�����ͨ��ͼ2-9��ʾ�Ľṹѵ����ģ�͡�

ͼ2-9 ֱ�������ѵ���ṹ |
|
��K+1ʱ�̣��������������NC��ѧϰ����ΪXc*(k)
Xc*(k)=[y(k+1),y(k),...,y(k-p+1),u(k-1),...,u(k-q)]T (2.24)
�������������NC�����Uc(k)
uc(k)=��c[Xc*(k)] (2.25)
����
uc(k)=��c[y(k+1),y(k),...,y(k-p+1),u(k-1),...,u(k-q)] (2.26)
����NC���ԣ���ѵ�����ƫ��ec
ec(k)��u(k)һuc(k) (2.27)
����ƫ���JΪ
J(k)=0��5[ec(k)]2=0��5[u(k)��uc(k)]2 (2.28)
��J��uc�ĵ���Ϊ��k
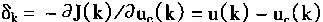 (2.29) (2.29)
�����ԣ�����ѵ�½ṹ��BP�㷨��ʮ�ַ���ġ�
����ֱ����Ӧ����ѵ���ṹ
ֱ����Ӧ�����У������������NC��ͨ����������ƫ��e(k)��r(k)-y(k)��ʵ��ѵ��Ч���б��ѵ����ִ�еġ���Ȼ�������ģ�͵�ѵ����ͬ������ѵ���ṹ��ͼ2��10��ʾ��
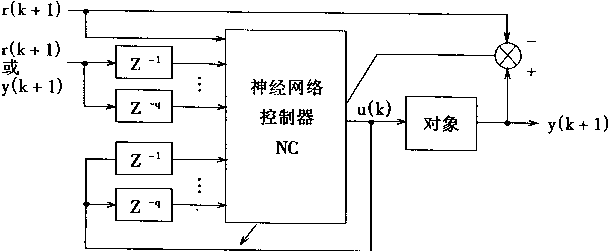
ͼ2-10 ֱ����Ӧ����ѵ���ṹ |
|
�ٶ��������ģ�ʹ��ڣ���ô��Ӧ��ʽ(2��19)��ʾ����ʽ�������ģ����ȷ�ģ���ô������ģ���ɵ�������NC�Զ���Ŀ����ܿ���ʹ���ƫ��e(k)��r(k)��v(k)��������С��
ֱ����Ӧ���Ʋ����ȸ�����ģ�ͣ����Ǹ��������ƫ��e��ȥ��Nc����ѵ��������ƽ�����ģ�͡���ֱ����Ӧ���ƽṹ�У�������֪��������������
1�������������NC��ʽ(2��19)�Ľṹ��ʽ��
2�����ƫ��e(k)��r(k)��y(k)
Ϊ�˽���ѵ����ƫ���J�ĸ�ʽȡ
J(k)=0.5[e(k)]2=0.5[r(k)-y(k)]2 (2.30)
���ڣ�NC�����Ϊu(k)������ѵ������Ҫ��ȡƫ���J��M�ĵ���������3
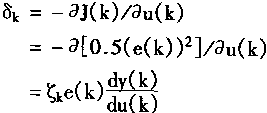 |
(2.31) | |
|
���У���k�Ƕ��������ӣ�ȡ1��0��������˵��������u(k)��Լ����ͬʱ�������ѵ��NC�������ٸ�������I��
��
 |
(2.32) |
| ������ʽ(2��15)��(2��16)������ϵͳ����kʱ����kȡֵ���� |
|
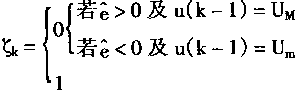 |
(2.33) | |
|
��ʽ(2��31)�м���������Nc����Ͷ�������֮�����һ����������ʽ(2��16)����ʾ��u(k)�����������������ʱ����ʱ�����ͻᱥ�ͣ�ͬʱ��ʽ(2��31)��������k=0���õ�����k��0����ʱ�ͻ��ֹѧϰ��������������r���Ա�����ʱ����ѧϰ����ִ�С�
���������Ӧ����ѵ���ṹ
�����Ӧ������ֱ����Ӧ���Ʋ�ͬ���������������ѵ���������Ǹ����ź�r�Ͷ����������ƫ��eE��r(k)��yE(k)���������������ѵ���������Ƕ������y(k)�������������yE(k)��ƫ��ec��y(k)��yE(k)�������Ӧ����ѵ���ṹ��ͼ2��11��ʾ��

ͼ2-11 �����Ӧ����ѵ���ṹ |
|
��ѵ��ʱ��ƫ���J��NC���u�ĵ�����=-aJ��au������������������ָʾ��J���ݶȷ���
�ڲ���ʵ������У�ʽ(2��31)�еĵ���
���������õ����ķ��ţ���+1��-1ȡ�����������ⲻ�����ձ��ԡ����ԣ�ͨ����Ҫ����dy(k)��du(k)�Ľ�������ǣ�dy(k)��du(k)�Ľ�����൱����ȡ�ġ�
�ڼ����Ӧ�����У����������PE���ڼ���ƫ���J��NC���u�ĵ���6������PE��һ�����ǰ�����硣����BP�㷨�����������������Ϳ˷���dy(k)��du(k)��ǰ������ȡ���ѵ����⡣
ͼ2��11��ʾ�Ľṹ����һ���ر���ŵ㣬����ǵ��������ģ�Ͳ�����ȡʱ�����ֽṹ�ر����á�Ϊ�˸Ľ������������ܣ�NC��PE������Ϊ��mά���뵥����Ķ��������Ŀɱ䲿���̶�����������PE�����Բ��ö����㹻�ḻ���й����ݽ���ǰ�ڵ��ѻ�ѵ����Ȼ���ٰ�NC��PE��������ѵ������ij�������Ͻ�������ִ��ϵͳ�����ʶ�ģ����ԣ�����״̬�仯Ѹ�ٵ�ϵͳ�����ǵ�³���ԣ���PE��Ƶ���ȱ���Nc��Ƶ���ȸ��Ǻ����ġ�
2��2��3����ѧϰ�������㷨
�����������Ҫ���õĿ����������������������ѵ�������ٶȺ�ʱ���൱������ʹ����ʵ�ʿ�����ִ������ѧϰ���������ܡ�Ϊ��ʹ��������������Խ���ʵʱѧϰ�����Ƕ����ѵ�������ٶȽ����˲����о�����Щ�о�����Ҫ˼�������¼��֣�
1��������Ч��BP�㷨��
2���ڶ��������ṹ�У�����ṹ֪ʶ���廯��
3���Ϳ��ƽṹ��ص���������ϵͳ��
4��Ԥѧϰ����Ч�ij�ʼ�����̡�
�ڿ���ϵͳ�У������߲���Ƶ�ʣ���Ȼ��ÿ����������Tsִ��һ��ѧϰ���ͻ����ѧϰʱ�䡣���ǣ�ʵ�ʿ���ϵͳ�У������Բ�������Ts��һ����Ҫ�����¶ȣ���ѧ��Ӧ���ƹ��̵Ⱦ�Ҫ���������Ts�ϳ���ͬʱ�����ٲ���Ҳ��Ҫ��ϵͳ����Ӧ�ĸ��ӿ��ƽṹ���Ӷ�ʹ������ߡ�
����ڲ��ı����Ƶ�ʵ����������ѧϰƵ�ʣ������Ի����ѧϰʱ�䡣������������ѧϰ�ͳ�Ϊ���ܣ����������ʵʱѧϰ�Ϳ���ʵ�֡�
Ϊ��ʵ��ʵʱѧϰ������ѧϰ����TL������ѧϰ����TLֻ���ɼ��������ʱ����������ԣ�һ��ѧϰ����TL�Ȳ�������TsҪС�öࡣ��Ȼ��ֻҪ��һ����������Ts��ִ�ж��ѧϰ����TL����ӿ�ѧϰ���̡�
һ�����������PEѵ��ѧϰ
�ٶ���k+1ʱ�̶�������Ϊy(k+1)����������ǰ��p-1+t�����ֵ�����ڴ������У�����y(k),y(k-1),...,y(k-p+1-t)
ͬʱ�����������Ϊu(k+1)������ǰ��q+t������ֵ���ڴ������У�����
u(k),u(k-1),...,u(k-q-t)
�����Կ�����XE(k-i)��y(k+1-i)���ݶԶ�ϵͳ��PE����ѵ������ȡi=0,1,2,...,t-1ʱ����Ȼ��t��XE(k-i)��y(k+1-i)������ע�⣬�����ڲ������k+1ʱ��Ҳ��k+1Ϊ��ֵʱ��PEִ��ѵ����k+1ʱ�̵�i��mά����ѧϰ����Ϊ
XE.i(k-i)=[y(k-i),y(k-1-i),...,y(k-p+1-i),u(k-i),u(k-1-i),...,u(k-q-i)]T (2.34)
����PE���������������yE(k+1-i)
yE.i(k+1-i)=��E[XE.i(k-1)] (2.35)
����ƫ���JE

���У�1�ݦ�0�ݦ�1��...�ݦ�t-1��һ��Ȩϵ�����У����ǵ���������ǿ�����µ����ݣ����������ݵ�Ӱ�졣
���������PEѵ���Ľ��Ӧʹƫ���JE��С��
���������PEִ��ѵ����Ϊ�˷���˵��ѵ���㷨����������ڲ������Ϊk��ʱ�̵�mά����ѧϰ����XEi(k-1-i)������ʽ(2��34)��
XE.i(k-1-i)=[y(k-1-i),...,y(k-p-i),u(k-1-i),...,u(k-q-1-i)]T (2.36)
��ѧϰ�У�BP�㷨����ʽ��ʾ
BP(����X��y��yE��i)
���У�BPΪ���㷨���ƣ�Ϊӳ�䣬xΪ����������yΪ���������yE��iΪʵ�������
PFѵ�����㷨�������£�
Step1��READ y(k)
step2��{������PEѵ�� }
i����t-1
REPEAT
yE,i����E(XE,i)
BP(��E,XE,i,��iy(k-i),yE,i)
i����i-1
UNTIL(i<0)
Step 3��{���������ź�u}
Xc����[r(k+1),y(k),...,y(k-p+1),u(k-1),...,u(k-q)]T or [r(k+1),r(k),...,r(k-p+1),u(k-1),...,u(k-q)]T
u(k)������c(Xc)
Step 4����u(k)ȥ���ƶ�������Tsʱ�䡣
Step 5��{�����ƶ�}
i����t-1
REPEAT
XE,i=XE,i-1
i����i-1
UNTIL(i=0)��
Step 6��{����������������}
XE,0����[y(k),y(k-1),...,y(k-p+1),u(k),...,u(k-q)]T
Step 7��k����k+1
Step 8��ת��Step 1
���������PEѵ�����ӣ���k=10������������y(10)������ȡp=3,q=2,t=3.���ڴ������д����(p��1+t)��5����ǰ���ֵy1��
y(9)��y(8)��������y(5)
ͬʱ����(q+t)��5����ǰ�Ŀ���ֵu����
u(9)��u(8)������u(5)
��PE������ѧϰ����Ϊ��
XE,0(9)��[y(9)��y(8)��y(7)��u(9)��u(8)��u(7)]T
XE,1(8)��[y(8)��y(7)��y(6)��u(8)��u(7)��u(6)]T
XE,2(7)��[y(7)��y(6)��y(5)��u(7)��u(6)��u(5)]T
��PEk��i��ʾȡ�ڲ���ʱ��kʱ����i��ѧϰ���״̬������Ek.i��ʾPEk��i��ִ�е�ӳ�䣮������10.0,��10.1,��10.2��

ͼ2-12 ���������PE��ѵ�� |
|
����ʽ(2��35)�����ڵ�kʱ��Ӧ��
yE,i(k-i)=��Ek,i[XE,i(k-1-i)] (2.37)
�Ӷ���
yE,0(10)=��E10,0[XE,0(9)]
yE,1(9)=��E10,1[XE,1(8)]
yE,2(8)=��E10,2[XE,2(7)]
�����ԣ���
��E9,0(.)=��E10,1(.)
����
��Ek,0(.)=��Ek+1,1(.)
����������У�PEѵ���������ͼ2��12��ʾ��
����������NCѵ��ѧϰ
�����������NC��ѵ��ѧϰ�����ֲ�ͬ�ıƽ������� һ����ֱ����������ƽ�(The Direct Inverse Control Error Approach)����һ����Ԥ��������ƽ�(The Predicted Output Error Approach)���������������ֲ�ͬ�ıƽ�������ѵ��ѧϰ�Ĺ��̲�ͬ��
1��ֱ����������ƽ�ѵ��ѧϰ
�ٶ���k+1����ʱ�̵��������Ϊy(k+1)��y��ǰ��P-1+t��ֵ��u��ǰ��q+t��ֵ�����ڴ������У���y(k)����y(k-p+1-t)��u(k)����u(k-q-t)��
��ͼ2��9��ʾ��ֱ������ƽṹ��֪��������Xc*(k-i)��u(k-i)���ݶԶ������������NC����ѵ��������
Xc*(k)=[y(k+1),...,y(k-p+1),u(k-1),...,u(k-q)]T (2.38)
��ȡi��0��1������t-1��ʱ����Ȼ��t��Xc*(k��i)��u(k��i)����������k+1ʱ�̶�NC��ѵ����
k+1ʱ�̵ĵ�i��mά����ѧϰ����Ϊ
X*c,i(k-i)=[y(k+1-i),......,y(k-p+1-i),u(k-1-i),......,u(k-q-i)]T (2.39)
����������NC�������uc(k��i)
uc,i(k-i)=��c[X*c,i(k-i)] (2.40)
����ƫ���Jc��
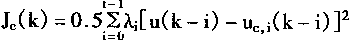 |
(2.41) | |
|
���У�1�ݦ�0�ݦ�1��...�ݦ�t-1
������k,i=-aJc/auc,i
��k,i=��i[u(k-i)-uc,i(k-i)] (2.42)
��ʽ(2��41)��������JcΪѵ��ʱ��ƫ�������ֱ���漰ϵͳ�����y��ƫ���ˣ������������NCѵ�����Ϊ��ƫ����������ܺܲ��Ч�������ԣ�Ϊ�˿˷��������⣬һ���ֱ������������С����ѵ�����������������������������������С���ķ����ϣ��Ӷ�ʹNCѵ���Ϳ�������Ч������ȡ�����õĽ����Ϊ�˱���˵��������NC��ѵ���������ڲ������Ϊkʱ��mάѧϰ����X*c,i(k-1-i)
X*c,i(k-1-i)=[y(k-i),y(k-1-i)...,y(y(k-p-i),u(k-2-i),...,u(k-q-1-i)]T (2.43)
��ѧϰ�У�BP�㷨����ʽ��ʾ
BP(��,X,u,uc,i)
���У���ΪNCӳ�䣬xΪ����ѧϰ������uΪNC���������uc,iΪNCʵ�������
NC��ѵ���㷨�������£�
Step 1:READ y(k)
Step 2:{ȡ������������}
X*c,0����[y(k),...,y(k-p),u(k-2),...,u(k-q-1)]T
Step 3:{������ѵ��}
i����t-1
REPEAT
uc,i������c(X*c,i)
BP(��c,X*c,i,��iu(k-1-i),��iuc,i)
i����i-1
UNTIL(i<0)
Step 4:{���������ź�u}
Xc=[r(k+1),y(k),...,y(k+1-p),u(k-1),...,u(k-q)]T or [r(k+1),r(k)...,r(k+1-p),u(k-1),...,u(k-q)]T
u(k)������c(Xc)
Step 5:��u(k)ȥ���ƶ�������T��
Step 6:{�����ƶ�}
i����t-1
REPEAT
X*c,i����X*ci-1
i����i-1
UNTIL(I=0)
Step 7:K����k+1
Step 8:ת��Step 1
��ֱ�������ƫ��ƽ�����NCѵ�������ӣ������в���ʱ��Ϊk��9���ʶ��������y(9)��ȡP=2,q��3��t=3�����ڴ������д����(p+t-1)��4����ǰ���ֵy����
y(8),y(7),y(6),y(5)
ͬʱ����(q+1)��5����ǰ����ֵu����
u(7),u(6),u(5),u(4),u(3)
����ʽ(2��43)����NC������ѧϰ������k��9ʱ��
X*c,0(8)=[y(9)��y(8)��y(7)��u(7)��u(6)��u(5)]T
X*c,1(7)��[y(8)��y(7)��y(6)��u(6)��u(5)��u(4)]T
X*c,2(6)��[y(7)��y(6)��y(5)��u(5)��u(4)��u(3)]T
��NCk��1��ʾNC�ڲ���ʱ��kʱ����i��ѧϰ���״̬������ck.i��ʾNCk.i��ʵ�ֵ�ӳ�䣮������c9.0,��c9.1,��c9.2
����ʽ(2��40)���ڵ�k���������У���
uc,i(k-i)=��ck+1,i[X*c,i(k-i)] (2.44)
�Ӷ���ӳ������
uc,0(8)=��c9,0[X*c,0(8)]
uc,1(7)=��c9,1[X*c,1(7)]
uc,2(6)=��c9,2[X*c,2(6)]
��ѵ��NCʱ������������u(8)��u(7)��u(6)���Ǻ�uc,0(8)��uc,1(7)��uc,2(6)��ƫ��������ʽ(2��41)��ʾ��ƫ���Jc��
��ʵ��ѵ������Ҫ��ͼ2��10��ʾ��ֱ����Ӧ���ƻ�ͼ2��11��ʾ�ļ����Ӧ���Ʒ�����ֱ����������ƽ��������ϣ�����ʵ��ȡ�ö�����������С�Ľ����
�Ѽ����Ӧ���Ƶļ�ѧϰ��ֱ����������ƽ��Ķ��ѧϰ���ϣ��Ӷ���һ���������ں���4��ѵ�����ڡ����������ͼ2��13��ʾ��
��ͼ2��13�У����3��ѧϰѵ�������������������NC����ѧϰ�Ĺ��̣���ѧϰ�����������Ѿ����������ұߵ�1��ѧϰѵ�������Ǽ����Ӧ���ƺ�ֱ����������ƽ����ϵ�ѧϰ��������ʱ����ʱ����k��9���ʶ����������ʾΪPE9����������ʾNC9��PE9��NC9���ϵ�ѧϰ�У������ѵ��ѧϰ���ݶ�Ϊr(9)��Xc(8)������
Xc(8)=[r(9),y(8),y(7),u(7),u(6),u(5)]T
��r(9)�Dz���ʱ��k��9ʱ�ĸ��������ź�
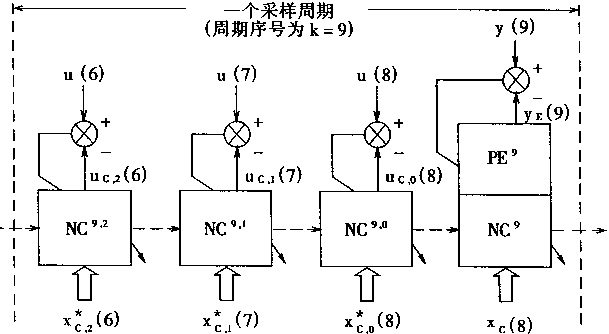
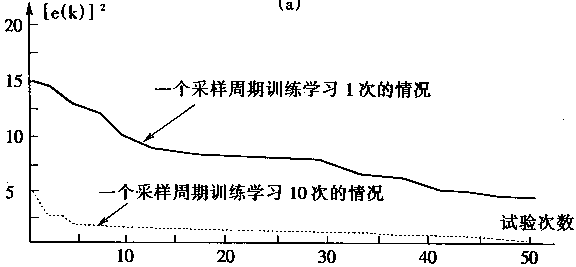
(b)
ͼ2-13 ֱ����������ͼ����Ӧ���Ʊƽ�NC�Ĺ��� |
|
�����������NC����ʱ��״̬��NC9��ʾ������ӳ������c9������ʽ(2��21)(2��22)�Ӷ��п������uc(8)��
uc(8)=��c9[Xc(8)]
���������PE��ʱ��״̬��PE9��ʾ������ӳ���æ�E9��ʾ����ʱ��XE(8)
XE(8)=[y(8),y(7),y(6),uc(8),u(7),u(6)]T
�Ӷ���PE���yE(9)
yE(9)=��E9[XE(8)]
����ƫ��eE����eE��r(9)��yE(9)��ȡƫ���JE
JE��0.5[r(9)-yE(9)]2
����Զ�NC����ѵ��ѧϰ��
2��Ԥ��������ƽ�ѵ��ѧϰ
ֱ����������ƽ����������������NC����Ŀ����ź�uc�����������ź�u�������бƽ�ѵ���ġ�Ԥ��������ƽ���ѵ��������֮��ͬ�������Զ��������PE�����yE����������r��������ѵ���ģ�ѵ���Ķ����������������NC��Ԥ��������ƽ�ѵ��ѧϰ��ϵͳ�ṹ��ͼ��ͼ2��14��ʾ��
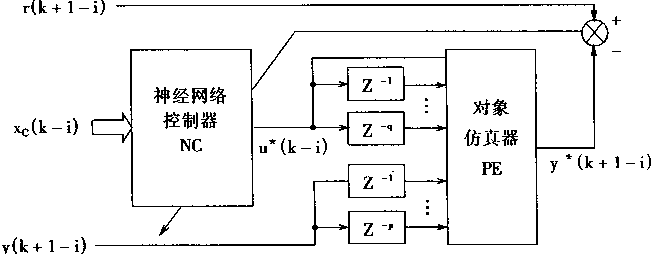
ͼ2-14 Ԥ��������ƽ�ѵ���Ľṹ |
|
��ͼ2��14��ʾ�ṹ��֪��NC������������Xc���Ӷ�����u*�������PE������������xE��xE��u*��y�γɣ��Ӷ��������y*�������
eE=r-y*
������ڹ���ƫ���J������ѵ����
�ٶ���k+1���������ڣ�����ֵr��t��ֵ�����ڴ������У�����
r(k+1-i) i=0,1,......,t-1
���� r(k+1),r(k),......,r(k+2-t)
�������y�а���y(k+1)���ڵ�p+t��ֵ���ڴ������У�����
y(k+1),y(k),y(k-1),......,y(k+2-p-t)
���������u����ǰq+t��ֵҲ���ڴ������У�����
u(k-1),u(k-2),...,u(k-q-t)
��ʽ(2��21)��ʽ(2��23)��֪�ڴ������е��ڴ����xc��i(k-i)
Xc,i(k-i)=[r(k+1-i),y(k-i),...,y(k-p+1-i),u(k-1-i),u(k-2-i),...,u(k-q-i)]T
����
Xc,i(k-i)=[r(k+1-i),r(k-i),...,r(k-p+1-i),u(k-1-i),u(k-2-i),...,u(k-q-i)]T
�ڽ���k+1��������ʱ�������������NC��״̬ΪNCk+1��1������ӳ���ʾΪ��ck+1�����������PE��ִ��ѧϰ����״̬��ʾΪPEk+1��ӳ���ʾΪ��Ek+1��
���ȣ�������������xc.i(k-i)ʱ��NC�������u*
u*(k-i)=��ck+1,i[Xc,i(k-i)] (2.45)
�����ԣ����ڶ���������γ�����X*E,i(k-i)
X*E,i(k-i)=[y(k-i),...,y(k-p+1-i),u*(k-i),...,u*(k-q-i)]T (2.46)
������ɶ��������PE���Ԥ��ֵy*
y*(k+1-i)=��Ek+1[X*E,i(k-i)] (2.47)
�������Եõ�Ԥ��ƫ��eE
eE=r(k+1-i)-y*(k+1-i) (2.48)
ȡƫ���JEΪ
 |
(2.49) | |
|
�����������NCѵ�����̿����������£���NC��PE����һ����һ�Ķ��������MNN����k+1���������У�ÿһ����������Xc��i(k��i)��i��0��1������t-1�����������Ӧ��Ԥ��ƫ����ʽ(2.48)��ʾ��ѵ����Ŀ�ľ���ʹʽ(2��49)��ʾ��ƫ���JE��С����
�����������KC��Ԥ��������ƽ���������ѵ��ѧϰ�Ĺ����У�����k����ʱ�̵���������Xc,i(k-1-i)
Xc,i(k-1-i)=[r(k-i),y(k-1-i),...,y(k-p-i),u(k-2-i),...,u(k-q-1-i)]T (2.50)
����
Xc,i(k-1-i)=[r(k-i),r(k-1-i),...,r(k-p-i),u(k-2-i),...,u(k-q-1-i)]T (2.51)
�ڽṹ�У���NC��PE����һ����һ�����磬������(��c+��E)��ʾ����BP�㷨����ʽ��ʾ
BP(��c+��E,X,r,y*)
���У���c+��EΪNC��PE��ɵĵ�һ���磬xΪ����ѧϰ������rΪ����ֵ������ֵ��y*ΪԤ�������
NC��ѵ���㷨�������£�
Step 1:READ y(k)
Step 2:{NCͨ��Ԥ�����ƽ�ѵ��}
i����t-1
REPEAT
j����0
REPEAT
uj*������c(Xc,i+j)
j����j+1
UNTIL(j>q)
{����PE����������}
X*E,i����[y(k-1-i),...,y(k-p-i),u0*,u1*,...,uq*]T
{����Ԥ�����}
y*����E(X*E,i)
BP(��c+��E,Xc,i,��ir(k-i),��iy*)
i����i-1
UNTIL(i=0)
Step 3:{����������ѵ��}
BP(��c+��E,Xc,0,��ir(k),��iy(k))
Step 4:{�����ƶ�}
i����t+q+1
REPEAT
Xc,i����Xc,i-1
i����i-1
UNTIL(i=0)
Step 5:{���������ź�}
Xc,0=[r(k+1),y(k),...,y(k+1-p),u(k-1),...,u(k-q)]T or [r(k+1),r(k),...,r(k+1-p),u(k-1),...,u(k-q)]T
u(k)������c(Xc,0)
Step 6����u(k)ȥ���ƶ�������T��
Step 7��k��k+1
Step 8��ת��Step 1
�������һ����Ԥ��������ƽ�����ѵ��NC�����ӣ��ٶ����в�������Ϊk=9�����ж������y(k)��ȡP��2��q��3��t=3�����ڴ������д�����ǰ���ֵy��(p+t-1)=4������y(8),y(7),y(6),y(5)
ͬʱ����(q+t)=5����ǰ����ֵu����
u(7),u(6),u(5),u(4),u(3)
����ʽ(2��50)������
xc.0(8)��[r(9)��y(8)��y(7)��u(7)��u(6)��u(5)]T
xc.1(7)��[r(8)��y(7)��y(6)��u(6)��u(5)��u(4)]T
xc.2(6)��[r(7)��y(6)��y(5)��u(5)��u(4)��u(3)]T
�ο�ͼ2��14��ʾ��ѧϰ�ṹ����ѧϰ������ͼ2��15����ʾ��
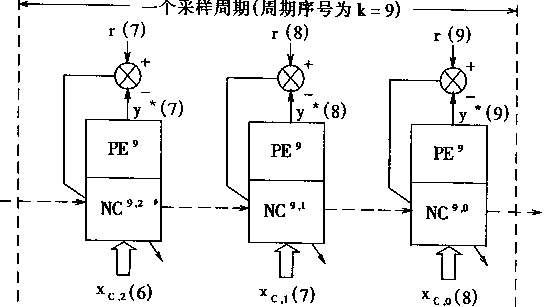
(a)

(b) |
|
ͼ2��15 Ԥ��������ƽ�ѵ��NC |
|
2��3 ���������ϵͳ |
|
���������ϵͳ�ڱ����Ͻ����������繹�ɿ������Ŀ���ϵͳ�����ֿ���ϵͳ��������֮�������ڿ���������ѧϰ���ܣ��Ӷ����ԶԲ���ȷ�Ķ������ѧϰʽ���ƣ�ʹ�������������ֵ��ƫ����������С��
����һ���У����ܼ���ʵ�ʾ�������������ϵͳ����������Щϵͳ�Ŀ��ƽ����
2��3��1 ��ɢϵͳ������Ӧ����
����һ��������ɢϵͳ����������Ӧ����ʱ����ϵͳ�Ľṹ��ͼ��ͼ2��16��ʾ����ͼ�п��Կ����������������������NC�����������PE��ѧϰ�������Լ����ض���PE�������п�����u�Ͷ��������y���֣�NC���������и���ֵr�����������U�Ͷ��������y��ϵͳ�е�NC��PE�����ڹ�����ִ������ѧϰ�ģ�����һ��ʵʱѧϰ�Ŀ���ϵͳ��

ͼ2-16 ��ɢϵͳ���ƽṹ |
|
һ�����ض���
���ض���������������Է��̱�ʾ
A(q-1)y(k)=B(q-1)u(k) (2.52)
����
A(q-1)=1+a1q-1+...+anq-n��
B(q-1)=b1q-1+...+bmq-m��
q-1����ʱ���ӣ�q-1y(k)=y(k-1)��
y(k)�������
u(k)�����롣
���ڱ��ض���ı���ʽ������������3��������
1��m��n�����Ͻ�ģ�������֪��
2��B(q-1)��һ���ȶ��Ķ���ʽ��
3��ϵ��b1��0��
m��n�н磬�������ȷ�����Ͻ�ֵ����NC��PE�����룬�Ӷ��ó������NC��PE������ʵ����Чѵ����B(q-1)�ȶ�����ɱ�֤�������ıջ������ȶ���b1��0���ǿ���������ġ�
���������������������
���������PE��������NC�������������繹�ɡ������ڽṹ�ϣ�����һ��������һ������㣬��û���в������2�������������ɡ�
1�����������PE
���������PE�Ľṹ��ͼ2��17��ʾ����ͼ�пɿ�����PE����������Ϊx(k-1)�����Ϊy(k)��Ȩϵ������Ϊw(k-1)��
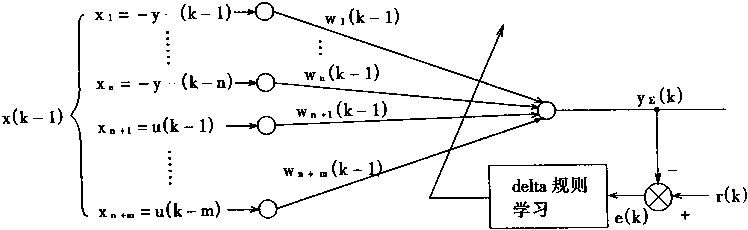
ͼ2-17 ���������PE�Ľṹ |
|
������kʱ�̣�����ʱ����������x(k)
x(k)��[x1(k)��x2(k)������xn(k)��xn+1(k)������xn+m(k)]T
��[-y(k)������-y(k-n+1)��u(k)������u(k-m+1)]T (2.53)
��PE��Ȩϵ������Ϊw(k)
w(k)��[w1(k)��w2(k)������wn(k)��wn+1(k)������wn+ m(k)]T (2.54)
���ڶ��������PE�������������繹�ɣ������y����ʽ���
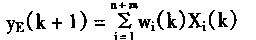 |
(2.55) |
| ��ʵʱѵ���У�Ȩϵ������Widrow-Hoff������и��£��� |
|
 |
(2.56) | |
|
���У�����(0��2)����˥�����ӣ�
E�ǽӽ���0��С�������ڷ�ֹ��xT(k)x(k)����0ʱ��ĸΪ0��
e(k+1)�����ƫ�e(k+1)��y(k+1)-yE(k+1)��
����ʽ(2��56)����ѧϰѵ��������Ŀ�ľ���ʹ���ƫ��e(k+1)��С�������ң���e(k+1)����Uʱ����ʽ(2��56)������w(k+1)��w(k)��
2��������NC
������NCҲ�Ƕ��������繹�ɣ��������n+m�����������һ�������Ľṹ��ͼ2��18��ʾ������Ϊz(k)�����Ϊ������u(k)��
��kʱ�̣�NC������Ϊz(k)����
z(k)��[z1(k)��z2(k)������zn+1(k)��zn+2(k)������zn+m(k)]T
=[r(k+1)��-x1(k)������-xn(k)��-xn+2(k)������xn+m(k)]T
=[r(k+1)��y(k)����y(k-n+2)��-u(k-1)������-u(k-m+1)]T (2.57)
ע����ʽ(2��57)��û��-Xn+1(k)����y(k-n-1)���
������NC��Ȩϵ������ΪW'(k)��
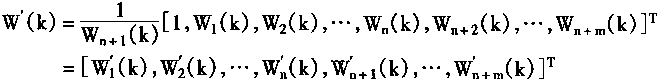 |
(2.58) |
��Ȼ��NC��Ȩϵ������w��(k)��PE��Ȩϵ������W(k)�ĺ�����
��NC�����Ŀ�������ź�u(k)������ʽ����� |
|
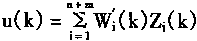 |
(2.59) | |
|

ͼ2-18 ������NC�Ľṹ |
|
3������ϵͳ����Ϣ��������
��ͼ2��16��ʾ�����������ϵͳ�У���Ϣ�Ĵ������̺Ͳ������£�
(1)ȡ����ֵr(k+1)��ȡ�������ֵy(k)��
(2)��ԭ��Ȩϵ������W(k-1)��ͨ��ʽ(2��55)������������PE��Ԥ�����yE(k)
(3)����ƫ��e(k)��y(k)��yE(k)����������ʽ(2��56)������µ�Ȩϵ������W(k)��
(4)��ʽ(2��58)����������NC��Ȩϵ������w'(k)��
(5)������Ncͨ��ʽ(2��59)����������u(k)��
��������ϵͳ�ıջ����ܷ���
��ȷ���ջ�ϵͳ������֮ǰ�ȿ��Ƕ����������һЩ���ʡ�
��W0�Ƕ��������PEѵ��֮��õ�������Ȩϵ������
W0=[W01,W02,...,W0n+m]T (2.60)
��W0������ʽ
 |
(2.61) | |
|
Ҳ����˵��Ȩϵ��ΪW0����ʱ��PE�ܾ�ȷԤ�����������
��������ʽ(2��53)��(2��55)�������Ķ��������PE�������������ʣ�

֤����
����Ȩϵ����W(k)
��W(k)=W(K)-W0 (2.62)
����ʽ(2��55)��(2��6I)��(2��62)����ϵͳ������e(k)���Ա���ΪȨϵ����W�ĺ�������
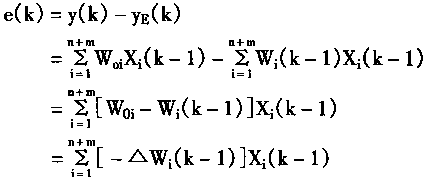
=-XT(k-1)��W(k-1) (2.63) |
|
��ʽ(2��56)����ȥW0�������Ȩϵ������ã�
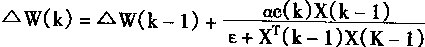 |
(2.64) |
| ����ʽ(2��64)����ƽ���� |
|
|
|
|
(2.65) | |
|
��ʽ(2.63)��֪
e(k)=-XT(k-1)��W(k-1)
����

����ʽ(2.65)����
 |
(2.66) | |
|
��ʽ(2.66)�У���
����(O��2)���ʼ�����0��
X(k-1)/XT(k-1)��XT(k-1)X(k-1)������
e(k)2Ҳ�ض�����0����������0��������
���ԣ���ʽ(2.66)��
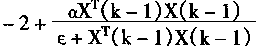 |
(2.67) | |
|
�Ľ��ȷ����[��W(k)]2-[��W(k-1)]2��������
�� H=xT(k-1)x(k-1)
��ʽ(2.67)��дΪ��

����


�Ӷ���֪

�����
[��W(k)]2-[��W(k-1)]2<0 (2.68)
ʽ(2��68)˵������������(1)������
��������(1)����k������������w(k)��W0���ʶ���ʽ(2��66)�����߶�Ϊ0����Ҳ���DZض���
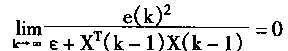 |
(2.69) | |
|
�ɼ�������������(2)������
֤�ϡ�
����������������Ϳ��Ը�����ʽ(2��53)��(2��59)��ɵĿ��ƽṹ�Զ���ʽ(2��52)ִ����Ӧ���Ƶıջ����ʶ�����
�������ڶ�����ʽ(2��52)�����Ŀ����У�ʽ(2��53)��(2��59)���ɵ���Ӧ���������µıջ����ʣ�
(1)�����ź�u(t)������ź�y(t)�����н�ġ�
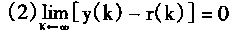
֤����
��ϵͳ�ĸ��������e'(k)��ʾ
e'(k)=y(k)-r(k) (2.70)
y(k)��ʽ(2��61)������
r(k)����ʽ(2��57)��(2��58)��(2��59)���������Wn+1(k)�ˡ�2��59)���ߣ�����
Wn+1(k-1)u(k-1)=r(k)+W1(k-1)(-X1(k-1))+.....,+Wn(k-1)(-Xn(k-1))+Wn+2(k-1)(-Xn+2(k-1))+......,Wn+m(k-1)(-Xn+m(k-1))
��������
r(k)=W1(k-1)X1(k-1)+......,+Wn(k-1)Xn(k-1)+Wn+1(k-1)u(k-1)+Wn+2(k-1)Xn+2(k-1)+......,+Wn+m(k-1)Xn+m(k-1)
(2.71)
���� u(k-1)=Xn+1(k-1)
�ʶ���
|
(2.72) |
| ��ʽ(2.61)��ʽ(2.72)������ |
|
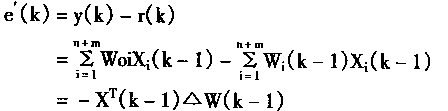 |
(2.73) |
| ������������(2)�� |
|
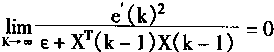 |
(2.74) | |
|
ֻҪ֤��xT(k-1)x(k-1)���н�ģ��Ϳ���֤��e(��)��0��Ҳ�Ϳ���֤�������е�����(2)��
����֤����x(k-1)�����ޡ�
�Ӷ���ʽ(2��52)�й��������������������ź�����
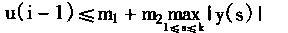 |
(2.75) | |
|
���У�1��i��k��m1<����m2<�ޡ�
����ʽ(2��52)�����������������ʽ(2��53)����
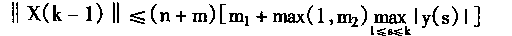 |
(2.76) |
| ��Ȼ�������ź�r���н�ģ����Ը�������� |
|
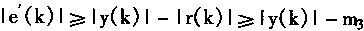 |
(2.77) | |
|
�Ӷ���|e'(k)|+m3��|y(k)|
�ɴˣ�ʽ(2��76)����дΪ��
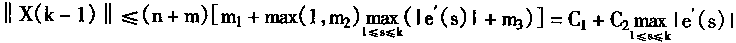 |
(2.78) | |
|
����0��C1������0��C2������
����������e'(k)�н磬���ʽ(2��78)��֪����x(k)��ͬ���н磻������ʽ(2��74)��֪
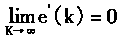 |
(2.79) |
��Ȼ������������(2)������
����������e'(k)�磬�����ʱ������|kn|���� |
|
 |
(2.80) | |
|
ȡm4��max(1����)
����
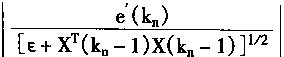
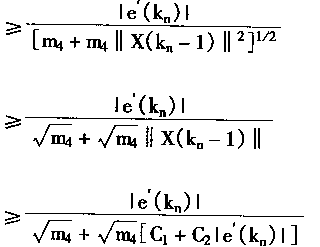 |
(2.81) |
| ��ʽ(2.81)ȡ������ |
|
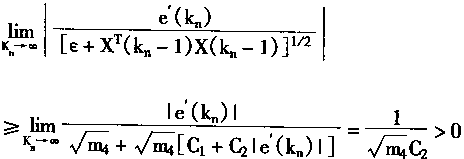 |
(2.82) | |
|
���������˵��e'(K)�н磬�������粻������
����e'(k)�н磬��ʽ(2��79)�DZض������ġ�����e'(k)��y(k)-r(k),��r(k)�н�,���ԣ�y(k)�н硣��ʽ(2��75)��֪u(k)Ҳ�н硣�������������ʳ�����
֤�ϡ�
�ġ�ϵͳʵ���������
������Ľṹ��ͬʱ���������ڼ���ͼ2-16��ʾ������Ӧ����ϵͳ�����н�������������PE��������NC�ֱ���ʽ(2.52)-(2.55)��ʽ(2.57)-(2.59)��������ѧϰʱ����ʽ(2��56)��ʽ(2��58)��
1�������������ȶ�����Ŀ���
��������ʽ��ʾ

����������PE��������NC���������Ϊ6��Ԫ�أ���n��m��3����ѵ��ѧϰʱPE��Ȩϵ����������ȡ��������ֵ���£�
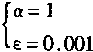
Ȩϵ�������ij�ʼֵȡ
W(0)=[0,0,0,1,0,0]T
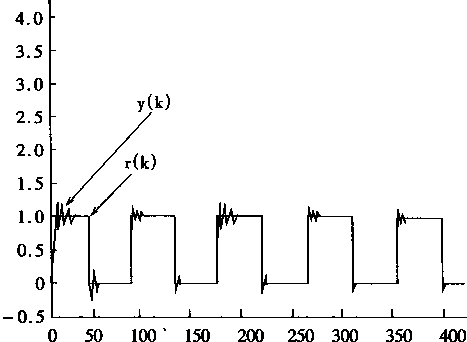
ͼ2-19 ����ֵr�Ͷ������y

ͼ2-20 NC�����Ŀ����ź�u

ͼ2-21 PE��ѧϰ����W(k)�ı仯 |
|
������ƽ��ֵΪ��ĸ�˹��������
��������r�Ƿ�ֵΪ1�ķ�����ÿ�������ڲ���80�Ρ�
���ƽ���������ͼ2��19��ͼ2��20��ʾ������ͼ2��19�Ƕ����������ֵ�������ͼ2��20��NC�����Ŀ����ź�u(k)��
�����ԣ��������������ȷ��Ԥ�����Ķ�̬���̡�
ͼ2��21�����˶��������PE��ѧϰ���̡�
2���Բ��ȶ�����Ŀ���
���ȶ���������ʽ��ʾ

��ϵͳ�У�PE��NC�����붼����6��Ԫ�ص���������n��m��3����ѵ��ѧϰʱ��PEȨϵ����������ȡ��������ֵΪ
Ȩϵ��������ʼ��ȡֵΪ
W(0)=[0,0,0,1,0,0]T
��������rΪ����Ϊ1�ķ���������ÿ���ڲ���80�Ρ�
��������ͽ���Լ���ѧϰʱ��w(k)�仯����ֱ���ͼ2��22��ͼ2��23��ͼ2��24��ʾ�����ڲ��ȶ�������Ȼ�ڹ��ɹ������нϴ�ij���������PEѧϰ֮��������ܸ��ٸ���r��

ͼ2-22 ����r�Ͷ������y�IJ���

ͼ2-23 NC�����Ŀ����ź�U�IJ���

ͼ2-24 PEѧϰʱW(k)�ı仯��� |
|
2��3��2 ˮ�����������ϵͳ |
|
�¶ȿ����������ڹ�ҵ����ͥ����ȸ������������Ŀ���ϵͳ��ˮ�¿������¶ȿ��Ƶ�һ�����͡������������ˮ�¿�����һ���µĿ��Ʒ�ʽ�Ϳ����ֶΡ������ˮ�¿���ϵͳ�У��������ѵ����ȡ��2��2���������������ѧϰ�������ܵ�����ѧϰ�������㷨��
һ���¶ȿ���ϵͳ��ģ��
��һ�������¶ȿ���ϵͳ��������������ѧ����ʽ������
 |
(2.83) | |
|
���У�t��ʱ�䣻
y(t)������¶ȣ�
f(t)�ǼӸ�ϵͳ��������
Yo�����£�һ��Ϊ������
c��ϵͳ����������
R��ϵͳ�߽�����Χ�����衣
�ٶ���ʽ(2��83)�У�RC�dz������ӽ�Ծ��Ӧ����Եõ����Ӧ����ɢϵͳ���崫�ݺ����ı���ʽ��
 |
(2.84) |
���У�u(k)Ϊϵͳ���ˣ�
y(k)Ϊϵͳ�����
TsΪ�������ڣ�
a(Ts)��b(T8)����ʽ������ |
|
 |
(2.85) | |
|
��ʽ(2��85)�С�����������R��Cȷ���ij�����
��һ���¶ȿ����У�����¶Ȳ���������һ���ļ���ֵ��Ҳ����(2��83)��������ϵͳ���б��͵ķ��������ԡ��ʿ��ƶ�����Ա���Ϊ��
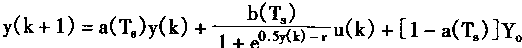 |
(2.86) | |
|
����һ�������ϵͳ����
��=1.00151*10-4 ��=8.67973*10-3
r=40.0 Yo=25.0��
0��u(k)��5 Ts>10S
����һ��ʵ��ˮ����õ����йز�����
��ʽ(2��15)��ʽ(2��86)���Ƚϣ���Ȼ��p��1��Q��0��������ѡ��IJ�����ϵͳ��һ��ˮ�ĵ����뵥����¶ȿ���ϵͳ�����ϵͳ�����µ�70��֮����ֳ��������ԣ���������80���������ɷ�����ͬʱ�ﵽ���͡�
����ˮ���¶ȿ���ϵͳ��������ṹ
ˮ���¶ȿ���ϵͳ�Ľṹ��ͼ2��25��ʾ������ˮ�ף���������ӿڲ���������������ʿ��Ʋ����ͼ�������ɡ�

ͼ2-25 ˮ���¶ȿ���ϵͳ�ṹ |
|
�����ź�����������Ϊ���Ƶ������źš������ͨ��A/Dת���Ƚӿڲ��������¶ȼ���������Ľ�����ڼ�����ڲ��������㷨ִ��ѧϰ�Լ�������Ĵ��������������ź�ȥ���ƹ���������������ʹ��������ǡ���Ĺ��ʼ��ȣ���������PWM��ʽִ�й��ʵ��ڡ�
�¶ȼ����Ϊ�뵼���¶ȴ���������A/Dת����Ϊ8λ������������Ŀ����ź���0��5V֮�䣬�����ڲ���PWM������������������Ϊ1.3KW��ˮ����һ����7��ˮ��Сˮ�ס�
������������ɵĶ��������PE��������NC����4��Ķ����������ɡ�ͨ��ʽ(2��86)��֪�����������������룬һ��Ϊy(k)��һ��Ϊu(k)�����������붼��һ����-1��+1֮�䡣ÿ�����㺬��6�����ݺ���Ϊs��������Ԫ�������������һ��������Ԫ�����ԣ�PE��NC�Ľṹ��ͼ2��26����ʾ

ͼ2-26 PE��NC�Ľṹ |
|
�ڼ�����У��������������ͨ�������㷨ʵ�ֵġ�������ϵͳ�У�������������Ͷ����������λ�ú�������ͼ2��27����ʾ����ͼ�п��Կ������������PE��������u(k)��y(k)�������ֻ��һ��yE��������NCҲ���������룬�ֱ�Ϊr(k+1)��u(k-1)�����������u(k)�������ԣ�����һ�ּ����Ӧ���ƽṹ���������ֽṹ�����ڶ�ˮ�����Խ���ѧϰ��

ͼ2-27 ϵͳ����������ƽṹ |
|
����ͼ2��26��ʾ�Ķ���������Ϻ������������NC����ʵʱѧϰʱ������������Ȩϵ�������ģ���
 |
(2.87) |
| Ҳ�����µ�Ȩϵ��Wn+1Ϊ |
|
 |
(2.88) | |
|
���У�n��ѵ��ѧϰ������ţ�
w��Ȩϵ����
����ѧϰ���ʣ��ǣ�O��
u>0��������ϵ����
J��������
�ڶ�PE��NCִ��ʵʱѧϰ֮ǰ�����ȶ�PE�����ѻ��Ĵ�ѵ������PE���ѻ�ѵ�����ԶԶ���Ľ�Ծ��Ӧ�����������Ӧ��������¼������Ϊ���ݵġ�Ϊ�˵õ����������������ݣ�������ӵ����������ˣ�ͬʱ�Ѷ��������������ݼ�¼������Ϊ�˸��ǿ��ƿռ����صķ�Χ��������¼�����ݶ���ѡ��10���ܴ������Ʒ�Χ�����ݡ�Ϊ��ʹ����Ч����һ����ԣ�ϣ���С����������Ӧ��ʵ�ʿ��Ʒ�ΧҪ��һЩ��
��PEͨ���ѻ�ѵ��֮���Եó����������Ȩϵ��������NC���������С��Ȩϵ�����Ա���ݺ���Ϊs��������Ԫ���͡���������ʼ�����£�����Զ�ϵͳִ��ʵʱ���к�ѧϰ��
����ʵ�ʿ��ƹ��̼����
����ʵ��ˮ��ˮ�¿���ϵͳ�����Ŀ��Ƹ���������һ�������¶����ߣ������������¶�����Ϊ��

����ͼ����ͼ2-28��ʾ��
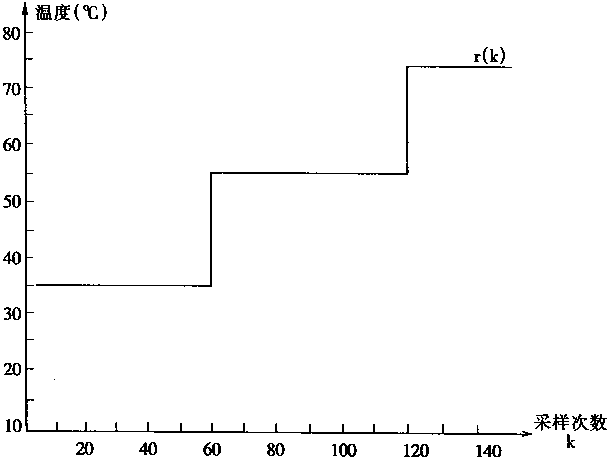
ͼ2-28 �����¶����� |
|
��ϵͳʵ������ʱ������ˮ�������ǽ�Ϊ�����ģ����Զ�ˮ�µIJ�������ѡ��Ϊ30�롣���ֲ������ںϷ�ˮ��ˮ�¿��Ƶ�ʵ�������
��ÿ���������ڣ����������PE����15�Σ�������NCִ��11��ѧϰ���ڡ�����������11��ѧϰ�����У���10�����ڲ����йصĶ��ѧϰ�ƽ�����1�����ڲ��ü����Ӧ���Ƶ�ѧϰ��������Щѧϰ������2��2���е�����ѧϰ�������㷨�ѽ����˽��ܡ�
�������10�������У�������NC��ÿ�����������еĶ��ѧϰ�ƽ����õ���Ԥ��������ƽ���Ҳ����˵����ÿ��������������10��Ԥ��������ƽ�ѧϰ���ڣ�1�������Ӧ����ѧϰ���ڡ�
�����ĸ��������У�����ÿ�����������У���5��ֱ����������ƽ�ѧϰ���ں�5��Ԥ��������ƽ�ѧϰ���ڡ�
��������ʵʱѧϰ�У�ѧϰ����ѡ�����£�
ѧϰ���ʦǣ�0.1��
����ϵ����=0.2��
ѧϰʱ��ƫ����������ƽ����������ʽ��ʽ(2��41)��ʾ��
ͨ��34��ʵʱ���飬��������ʵʱѧϰ��ȷ����Ȩϵ����������ЩȨϵ��������������������PE��NC��ϵͳִ�п��ƣ��ɵó���ͼ2��29��ʾ�Ŀ���Ч����

ͼ2-29 34����������õĿ���Ч�� |
|
��ͼ2��29�У���ͼ�Ǹ����¶�����r(k)�Ϳ��ƽ������y(k)�ı仯������ڸ����¶��Խ�Ծ��ʽ����������35��ʱ����Լ����10���������ڣ�ϵͳ�����ܺõظ��ٸ���35����¶ȡ���ʱ��Ϊ���µ��¶ȴ�ԼΪ25�档�������¶ȴ�35���Ծ������55��ʱ����Լ����18���������ڣ�����ܺܺõظ��ٸ�����55�棬���������¶ȴ�55�����Խ�Ծ��ʽ������75��ʱ����Լ�����ĸ��������ں�����ܸ��ٸ����������¶�75�档�������Ժ�ˮ�������йأ���ΪԽ�ӽ�80�棬ˮ�ķ���������Խ���ԡ��ܵĿ������˵����ͨ��ʵʱѧϰ����������������PE�������������NC�������ʵ�ֶ�ˮ��ˮ�µĿ��ơ�
��ͼ2��29�У������������������Nc����������źţ������ԣ��ڲ������ڴ������Ϊk��0��10ʱ��NC�����u(k)��һ��ֵΪ5�ķ��������ڲ������k��60��78ʱ��PE���u(k)��һ��ֵΪ5������Ϊ9���ӵķ���������k=120��140ʱ��NC���U(k)�Ƿ�ֵΪ5ͬʱ����Ϊ10���ӵķ�����
������Ϊ20�棬�����Ƹ����¶���������ʽ������
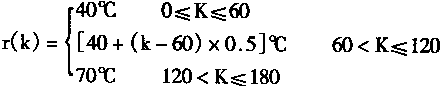
����Ƶ������ͼ2��30��ʾ��

ͼ2��30 ��Ծ�����ٸ�������Ӧ��� |
|
��ͼ2��30�У���ͼ��ϵͳ�ĸ����¶�����r(k)�Լ�ϵͳ������¶����ߵ���Ӧ�������ͼ�п���ϵͳ�����õ���Ӧ���ԣ��ر������ٸ����������¶����ߣ�����(60С��K��120ʱ�кܺõĸ�����������ͼ�У���k��50ʱ����Ϊ����+5��ĸ��ţ�����k��150��ʱ��������Ϊ��-5����ţ��������������ϵͳ�кܿ����Ӧ������ͼ2��30����ͼ����������Nc����������ź�U(k)�IJ��Ρ� |
|
������ ģ�������� |
|
ģ������������ķ�չʹ����ʮ���������ܿ��Ƶõ�ʮ����Ҫ�Ľ�չ������ģ����������������������Ȼ��ͬ���������ǵĻ�����������Զ�����ǣ����Ƕ������ܵķ��淽�����Ƿ�������ǽ������������Ӧ����?�ӿ�ʵ�������۵��ܺ��Ͻ�����ȫ���������ǽ�ϵġ���ģ���������������ϾͲ����ˡ����µļ������������ģ�������硣ģ�������������ڲ���̽�ֺ��о���һ����������Ŀǰ��ģ��������������������ʽ��
1����ģ��������
2������ģ��������
3�����ģ��������
ģ����������Ǿ���ģ��Ȩϵ�����������ź���ģ�����������硣����������ʽ��ģ������������ִ�е����㷽����ͬ��
ģ��������������Ϊ�ƽ���������ģʽ�洢����������Ҫѧϰ���Ż�Ȩϵ���ġ�ѧϰ�㷨��ģ���������Ż�Ȩϵ���Ĺؼ���������ģ�������磬�ɲ��û�������ѧϰ�㷨��Ҳ���Ǽ���ѧϰ�㷨����������ģ�������磬����ģ��BP�㷨���Ŵ��㷨�ȡ����ڻ��ģ�������磬Ŀǰ��δ�к������㷨�����������ģ��������һ�������ڼ������������ѧϰ�ģ�������һ��ѧϰ��
ģ�������������ģ���ع顢ģ����������ģ��ר��ϵͳ��ģ����ϵ������ģ�����̡�ͨ�ñƽ�����
�ڿ��������У������ĵ�����ģ�������繹�ɵ�ģ��������������һ���У�����ģ��������Ļ����ṹ���Ŵ��㷨��ģ���������ѧϰ�㷨���Լ�ģ���������Ӧ�á�
3��1 ģ�����������ͽṹ
ģ����������һ�����͵������磬����������������ģ���㷨��ģ��Ȩϵ���������硣ģ����������ص����ڰ�ģ���������������緽�������һ��
����ģ����������ԣ�����Ҫ�����������㣺
��һ��ģ����Ԫģ�͵Ŀ�����
�ڶ���ģ��Ȩϵ��ģ�͵Ŀ�����
������ģ��������ѧϰ�㷨�Ŀ�����
1974�꣬S.C.Lee�Ժ�E.T.Lee��Cybernetics��־�Ϸ����ˡ���Fuzzy sets and neural networks��һ�ģ��״ΰ�ģ��������������ϵ��һ�𣻽��ţ���1975�꣬��������Math.Biosci��־�Ϸ�������Fuzzy neural networks��һ�ģ���ȷ�ض�ģ��������������о����������У�������0��1֮����м�ֵ�ƹ���McCulloch-Pitts������ģ�͡����Ժ�һ��ʱ���У�������������о��Դ��ڵͳ����������ⷽ����о�û��ȡ��ʲô��չ��1985�꣬J.M Keller��D.Huut���f��ģ������������֪���㷨���ϡ�1989��T��Yamakawa����˳�ʼ��ģ����Ԫ������ģ����Ԫ����ģ��Ȩϵ�����������ź���ʵ����1992�꣬T��Yamakawa��������µ�ģ����Ԫ���µ�ģ����Ԫ��ÿ������˲��Ǿ��е�һ��Ȩϵ��������ģ��Ȩϵ����ʵȨϵ�������ļ��ϡ�ͬ�꣬K.Nakamura��M.Tokunaga�ֱ�Ҳ����˺�T��Yamakawa����ģ����Ԫ��ͬ��ģ����Ԫ��1992�꣬D.Nauck��R.Kruse����õ�һģ��Ȩϵ����ģ����Ԫ����ģ�����Ƽ�����ѧϰ��������һ�꣬I.Requena��M.Delgado����˾���ʵ��Ȩϵ����ģ����ֵ��ģ�������ģ����Ԫ��1990�굽1992���ڼ䣬M��M��Gupta����˶���ģ����Ԫģ�ͣ���Щģ��������ͬ�����ģ����Ԫģ�ͣ����к�ģ��Ȩϵ������������ģ������ģ����Ԫ��1992�꿪ʼ��J��J��Backley�����˶�ƪ���ڻ��ģ������������£�����Ҳ��ӳ�����ǽ���������Ȥ�㡣
������ֱ��ģ��������IJ�ͬ�ṹ��ʽ���н��ܡ���Щ�ṹ������ģ�������硢����ģ�������硢���ģ�������硢����ģ�������硣
3.1.1 ��ģ��������
��ģ��������������ģ����Ԫ��ɵġ���ģ����Ԫ�Ǿ���ģ��Ȩϵ�������ҿɶ������ģ���ź�ִ������������Ԫ��ģ����Ԫ��ִ�е�ģ�������������㡢��ˮ������������㡣������Σ�ģ����Ԫ�Ļ����Ǵ�ͳ��Ԫ�����ǿɴӴ�ͳ��Ԫ�Ƶ�����
��ִ��ģ�������ģ���������Ǵ�һ�������緢չ���õ��ġ�����һ�������磮���Ļ�����Ԫ�Ǵ�ͳ��Ԫ����ͳ��Ԫ��ģ��������ʽ�����ģ�
 |
(3-1) |
| ����ֵ��i=0 ʱ���� |
|
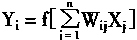 |
(3-2) | |
|
���У�Xj����Ԫ�����룻
Wij��Ȩϵ����
f[��]�Ƿ����Լ���������
Yi����Ԫ�������
�����ʽ(3��2)�е��й������Ϊģ�����㣬�Ӷ����Եõ�����ģ�������ģ����Ԫ��������Ԫ��ģ�Ϳ���������ʽ(3��3)��ʾ��
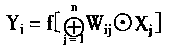 |
(3-3) |
���У�����ʾģ�������㣻
����ʾģ�������㡣
ͬ����ʽ(3��3)�е�����Ҳ������ģ��������ȡ�����Ӷ��С�����Ԫ�� |
|
 |
(3-4) |
| ���߱�ʾΪ�� |
|
 |
(3-5) |
| ͬ��Ҳ���С��롱��Ԫ��ģ�����£� |
|
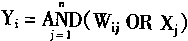 |
(3-6) |
| ���߱�ʾΪ�� |
|
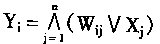 |
(3-7) | |
|
����ר�ſ��ǻ���ģ���������ģ����������й����ԡ�
һ�������ģ��
����һ����Ԫ�������������ź���������������ʾ���������Ծ���ֵ��ʾ���������������ʾΪ��
 |
(3-8) | |
|
�����ԣ���Щ�����ź�����(n+1)ά��������[0,1]n+1֮�ڣ�����������������Ϊ[0��1]���ֵ���������ź�������������Ҳ����������Ԫ�ؼ��������ȱ�ʾ������ʽ(3-8)�У�Xn(t)��ģ������
ͬ���������е�Ȩϵ������Ҳ������������[0��1]n+1�е��źű�ʾ��
 |
(3-9) | |
|
��ʽ(3-9)�У�Ȩϵ��Wn(t)ģ��������ʱ����Ԫ�ṹ��ͼ3-1��ʾ��
��������X1,X2[0,1]������AND����ΪTӳ�䣺
T:[0,1]*[0,1]����[0,1]
��
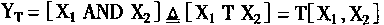 |
(3-10) |
ͬ��������OR����ΪSӳ��
S:[0,1]*[0,1]����[0,1]
�� |
|
 |
(3-11) | |
|
���ң�����N����ΪNӳ�䣺
N:[0,1]����[0,1]
��
YN=N[X1]=1-X1 (3-12)
�ʶ��� N(0)=1��N(1)��0��NN(x)��X
����T��S���ӣ�����������Ҫ���ʣ�
T(0��0)��0 S(0��0)��0
T(1��1)��1 S(1��1)=1
T(1��X)��X S(0��X)��X
T(X��Y)��T(Y��X) S(X��Y)��S(Y��X)
ͬʱ������Morgan�������������¹�ϵ��
T(X1��X2)��1-S(1-X1��1-X2)
S(X1��X2)��1-T(1-X1��1-X2)
�ڻ���ģ����������ģ���������У�������������Ȩϵ�������У�
X(t)��[0,1]n+1
W(t)��[0,1]n+1
����������ģ��(3��2)�У�Ȩϵ���������źŵij˲�����T����ȡ������Ͳ�����s����ȡ�������У�
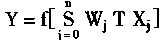 |
(3-13) | |
|
���У�f|��|�Ƿ����Ժ�����
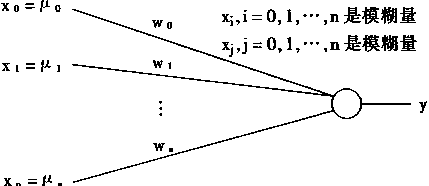
ͼ3-1 ģ����Ԫģ�� |
|
����������˫���ı任
�����ģ���������Ƕ�����[0��1]�������ڵģ����ԣ��������״̬Ҳ�;�����[0��1]�������ڡ�Ϊ�˿���������ļ������������ԣ���Ҫ������������������������������ԣ�����������˺�Ȩϵ��ȡ[-1��1]�����ֵ��
Ϊ��˵����[-1��1]��������������ʰ�����ǰ[0��1]����ĵ������������ת�����µ�[-1��1]�����˫��������У������Ϳ��Զ�����[-1��1]������й���������
���ǵ����ź�X(t)��[0��1]�����Ӧ˫���ź�Z(t)��[-1��1]����Ϊ��
Z(t)=2X(t)-1 (3-14)
ͬ����N[Z]����Ϊ��
N[Z]=-Z(t) (3-15)
��ʽ(3��14)������[0��1]���䶨���S��T����ת������[-1��1]����IJ�����
��[-1��1]�����T(AND)��S(OR)�����������£�
T(-1,-1)=-1 S(-1,-1)=-1
T(1��1)=1 S(1��1)��1
T(1��Z)��Z S(-1��Z)��Z
T(Z1��Z2)��T(Z2��Z1) S(Z1��Z2)��S(Z2��Z1)
��[-1��1]���䣬T��S��Morgan����Ϊ
T(Z1��Z2)=-S(-Z1��-Z2)
S(Z1��Z2)��-T(-Z1��-Z2)
���ñ任ʽ(3��14)����n+1ά����x(t)��[0��1]n+1ת����n+1ά����Z(t)��[-1��1]n+1����ʱ����Ԫ�IJ�����������Ա�ʾ���£�
Y=f[u]��[-1,1] (3-16)
����

��ʽ(3-16)Ҳ����д�ɣ�

��
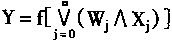
��
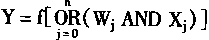
��ʽ(3��16)��f[��]�Ķ�������
f[u(t)]=|u(t)|g��sgn[u(t)], g>0 (3-17)
���У�g����������������ڿ���S�����ļ���ˮƽ��
3��1��2 ����ģ��������
����ģ���������ǿ��Զ�����ģ���ź�ִ��ģ���������㣬������ģ��Ȩϵ���������硣ͨ��������ģ��������Ҳ��Ϊ����ģ�������磬��Ʊ���ģ�������硣
����ģ��������һ����ΪRFNN(Regular Fuzzy Neural Net)���ΪFNN(Fuzzy Neural Net)����һ������£����ѳ���ģ����������ΪFNN��
����ģ�������������ֻ������ͣ����ֱ���FNN1��FNN2��FNN3��ʾ�����������͵��������£�
1��FNN1�Ǻ���ģ��Ȩϵ�����������ź�Ϊʵ�������硣
2��FNN2�Ǻ���ʵ��Ȩϵ�����������ź�Ϊģ���������硣
3��FNN3�Ǻ���ģ��Ȩϵ�����������ź�Ϊģ���������硣
�����ȶ�ģ����������Ķ�����н��ܣ����˵������ģ��������Ľṹ�����ʡ�
һ��ģ����������
ģ���������������ģ���˺�ģ�������ֻ������㣬���ǵĶ���ֱ�˵�����£�
1��ģ����
��N��M������ģ���������ǵ����������ֱ�Ϊ��
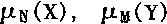
��N��M��ģ��������ʽ��ʾ��
 |
(3-18) |
���У���������ʾģ�������㡣
ģ����P��������������ʽ������ |
|
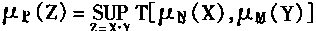 |
(3-19) |
| �� |
|
 |
(3-20) | |
|
ʽ(3��19)��(3��20)�����˻�������ԭ����ģ�������㡣ģ���˵�������ͼ3��2��ʾ��
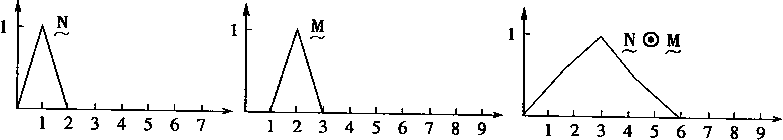
ͼ3-2 ģ���� |
|
2��ģ����
��N��M������ģ���������ǵ����������ֱ�Ϊ��
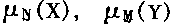
��N��Mģ��������ʽ��ʾ
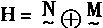 |
(3-21) |
���У���������ʾģ�������㡣
ģ����H��������������ʽ������ |
|
 |
(3-22) |
| �� |
|
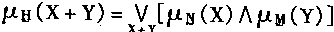 |
(3-23) | |
|
ʽ(3��22)��(3��23)�����˻�������ԭ����ģ�������㡣ģ���ӵ�������ͼ3��3��ʾ��

ͼ3-3 ģ���� |
|
3��������ӳ��
��N��һ��ģ������f[��]�Ƿ�����ӳ�䣬��N�ķ�����ӳ�䶨������

������ӳ����G��������������ʽ����
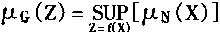 |
(3-24) |
| �� |
|
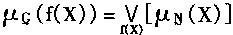 |
(3-25) | |
|
һ�㣬���������еļ�������Ҳ�ƴ��ݺ��������ݺ���ͨ������S����������f(x)��1/[1+exp(-X)]�ʶ���ģ����������ģ�����ķ�����ӳ�����S����������f[��]��ʾ��ʽ(3��24)��(3��25)�����������ԭ���ķ�����ӳ�䡣����������ͼ3��4��ʾ��

ͼ3-4 ������ӳ�� |
|
����ģ������������͵Ľṹ��FNN3�ͽṹ����FNN1��FNN2�ͽṹ��FNN3��ͬ����������̶����Դ�FNN3�ͽṹ������������Ƴ�����FNN3�У�Ȩϵ���������źŶ���ģ����������Ԫ����Ϣ�Ĵ�������ģ���ӡ�ģ���˺ͷ����Ե�S������
���͵�FNN3�Ľṹ��ͼ3��5��ʾ������һ�����������磬�к�2����Ԫ������㣬��2����Ԫ������ͺ�1����Ԫ������㡣�����е���Ԫ�ֱ��ñ��1��5�����
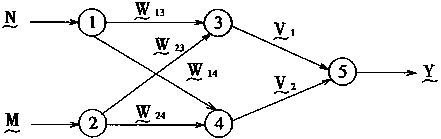
ͼ3-5 ����ģ�������� |
|
�����ԣ�����Ԫ3����������ΪU3��
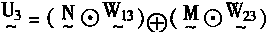 |
(3-25) |
| ������Ԫ4��������ΪU4�� |
|
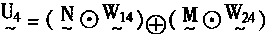 |
(3-26) |
| ��O3��O4�ֱ��ʾ��Ԫ3��4����������� |
|
 |
(3-27) |
| ������Ԫ5��������ΪU5�����ΪY������ |
|
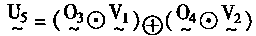 |
(3-28) |
 |
(3-29) | |
|
�������Y�����ɴ��ݺ���S��������ģ���ģ����YE[0��1]��
����ģ�������磬������ΪN��Mʱ�����ΪY������Կ���N��Mͨ���������ӳ��ΪY������ʾΪ��
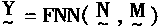 |
(3-30) | |
|
��������ģ�������������
��L��ʾ����ʵģ�����ļ��ϣ���Lx L������ʾ����Ϊ2άģ�����ռ䡣
��N��M��L��Y��L���������L��ӳ��F��������L���ɱ�ʾΪ
 |
(3-31) | |
|
�����ҽ���

����

���ӳ��f��������L�ǵ����ġ�
����ͼ3��5��ʾ��ģ�������磬����FNN��ʾ������ӳ��
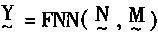
�����ͼ3��5��������ź���N'��M'��������
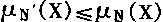 |
(3-32) |
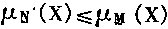 |
(3-33) |
| �� |
|
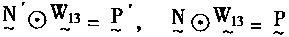 |
(3-34) |
| ���� |
|
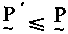 |
(3-35) |
| �� |
|
 |
(3-36) |
| ���� |
|
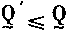 |
(3-37) |
| �Ӷ��� |
|
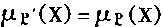 |
(3-38) |
 |
(3-39) |
| �� |
|
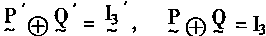 |
(3-40) |
| ���� |
|
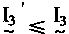 |
(3-41) |
| �����������ԭ����S����f(x)��(1+e-x)-1������� |
|
 |
(3-42) |
 |
(3-43) |
| ���������ֱ�Ϊ�� |
|
 |
(3-44) |
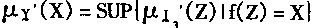 |
(3-45) |
| ���� |
|
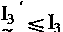 ���� ���� |
|
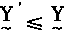 |
(3-46) | |
|
�����ԣ�����ͼ3��5��ʾ��ģ�������磬����һ�����������硣
ʵ���ϣ��������������չ��һ���ij���ģ�������硣��������½��ۣ�
����һ��ģ�������磬����������������ǻ�������ԭ��ģ������ģ���������ǡ������������硣��
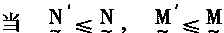
����
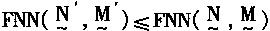
������Ľ��ۿ�֪�������κδ�o��L����������ӳ�䣬�������û�������ԭ���ij���ģ����������бƽ�����֮�����ӳ���Ƿǵ����ģ������ó���ģ����������бƽ���
3��1��3���ģ��������
���ģ����������HFNN(Hybrid Fuzzy Neural Net)������������˽ṹ�ϣ����ģ��������ͳ���ģ����������һ���ġ�����֮��IJ�ͬ�������������㹦�ܣ�
1�����뵽��Ԫ�����ݾۺϷ�����ͬ��
2����Ԫ�ļ��������������ݺ�����ͬ��
�ڻ��ģ���������У��κβ������������ھۺ����ݣ��κκ����������������ݺ���ȥ������������������ר�ŵ�Ӧ����;����ѡ����֮��ض���Ч�ľۺ�����ʹ��ݺ��������ڳ���ģ�������磬Ҳ����ģ���������У����ݵľۺϷ�������ģ���ӻ�����㣬���ݺ�������S������
������Ծ���Ļ��ģ����������˵������������������Ȼ���ٽ���������������ʡ�
һ����̨ģ��������IJ���
Ϊ�˾���˵���ڻ��ģ��������IJ������̣����ȿ���ͼ3��6��ʾ���������˽ṹ������������и�����Ԫ�ľۺ�����ʹ��ݺ��������Dz�ͬ�ġ�������Ϊ������ģ���������������ñ��ļӡ��������Լ�s���������ǿ��������κβ��κ���Ԫ���ò�ͬ�IJ��������ԣ�������Ϊ���(Hybrid)ģ�������硣
ͼ3-6 ���ģ�������� |
|
1�������͵�1Ժ��Ĺ������
�ڵ�1������һ����K����Ԫ�������������2���ڵ�͵�1�����һ����Ԫ���ӣ�Ҳ����˵����1�����ÿ����Ԫ��2������ˡ�
��L������ʵģ�����ļ��ϣ���ͼ3��6�У�N��M��Ak��Bk��Ck��Q��J��ʵģ��������E��ʾ����ģ��Ч֮����ȵij̶Ȳ�����������N��Mʱ����
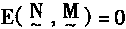
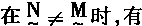

���ڵ�1����ĵ�k����Ԫ��������I1k��ʾ����
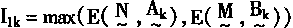 |
(3-47) | |
|
���У�Ak��Bk��Ȩϵ��1c��
�����ԣ��ڻ��ģ����Ԫ�У������ź�N��M��Ȩϵ��Ak��Bk֮��Ľ����������ò��E(N��Ak)��E(M��Bk)�����ȵģ��������������ֵΪ������롣
�ڻ��ģ���������1�����У����ݺ���fΪ��Ծ�����������������k
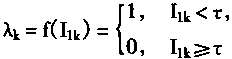 |
(3-48) | |
|
���У�tΪ������ķ�ֵ��t>0��1��k��K��
�������1�����������Ԫ�Ĵ��ݺ�����ͬ����ֵ��ͬ��
2����2����������
�ڵ�2�����У���1����Ԫ��Ȩϵ��Ϊ1����ͼ3��6�п����������2�����1����Ԫ����������ΪI21������
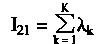 |
(3-49) |
������k��ʵ��0��1����I21�Ǿ�ȷֵ��
����Ԫ�Ĵ��ݺ���������ͬ���������� |
|
| f(X)=X |
(3-50) |
| �ʶ��������Ԫ�����������������I21���� |
|
| ��=I21 |
(3-51) | |
|
���ڵ�2�����2����Ԫ������Ȩϵ���ֱ�ΪC1��C2������Ck�����ԣ��������ʾΪI22������
 |
(3-52) |
| ������k��Ck��ȡֵ���� |
|
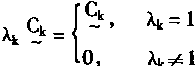 |
(3-53) |
ͬʱ��ʽ(3��52)�еķ�������ģ���ӵı���������������ʽ(3��22)��(3��23)������
�����Ԫ�Ĵ��ݺ���Ҳ������ͬ�������ʶ������J�� |
|
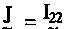 |
(3-54) | |
|
3�������������
��������У�Ȩϵ��Ϊ10�����������Ԫ�ľۺϲ����dz��������ԣ������Ԫ����������ΪI
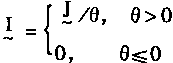 |
(3-55) | |
|
���ݺ���Ҳ������ͬ��������������������ˣ�����
�������������֪����ͼ3��6��ʾ�Ļ��ģ���������������P�ɱ�ʾΪ
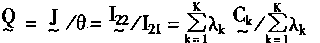 |
(3-56) |
| ������k��1ʱ������ |
|
 |
(3-57) | |
|
�������ģ�������������
���ģ�������������������õ�����ͳ���ģ�������粻ͬ�����ԣ����ж��ص����ʡ������F��ʾͼ3��6��ʾ������Ȳ���E����ֵt��Ȩϵ��Ak��Bk��Ck������Ļ��ģ�������磻��ô��F��һ��ͨ�ñƽ�����
������֮��ͼ3��6��ʾ�Ļ��ģ����������Աƽ������˫���뵥���ģ��������
1.�����������
L��ʾ����ʵģ�����ļ��ϣ�������ʾ2άʵģ�������ϣ��� ����LxL��
����1��ģ����N��M�ġ��ؼ���N(��)��M(��)��ʾ������
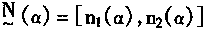

���У�n1(��)�ǡ��ؼ�N(��)���½�Ԫ�أ�n2(��)��N(��)���Ͻ�Ԫ�أ�m1(��)��M(��)���½�Ԫ�أ�m2(��)��M(��)���Ͻ�Ԫ�ء�
ģ����N��M��Hausdorff��13�������ʽ������
 |
(3-58) |
| ����2���ڼ���L�У�ģ����N��M֮��ľ�����d��ʾ��������ʽ���� |
|
 |
(3-59) | |
|
����3����2άʵģ������������L xL�У�����2άģ����(N1��M1)��(N2��M2)֮��ľ�����D��ʾ����������ʽ������
 |
(3-60) | |
|
����4��F������ӳ��
F��������L
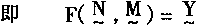
���У�N��M��L��ģ������YҲ��L�е�ģ������
2��ͨ�ñƽ�������
������ͼ3��6����E��t��Ak��Bk��Ck�������ģ��������F��һ��ͨ�ñƽ�����
֤����
��u�����еĽ��Ӽ���F��U��L������ӳ�䣬HFNN����Ak��Bk��Ck��E��t������Ŀռ�F�еĻ��ģ�������硣
����ģ����N��M����ӳ��
|
|
(2)����ͼ3-6��ʾ�Ļ��ģ�������磬������������(N��M)��ͬʱ��(N��M) ���ڽ�����U�����ұ���������

�����е�Ԫ��֮һ���༴N��Ak��M��Bk��1��k��K����
G={k|��k=1,1��k��K} (3-73)
������k������ȫ��Ϊ0����G�Ƿǿռ������ԣ�����>0��
��m��ʾG�����Ļ���Ԫ�أ�Ϊ���������G��{1��2������m}������
|
|
���ȣ�����A��B��C�����ؼ���
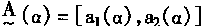

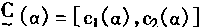
�ⶼ�DZ����䡣����

��ʽ(3��59)����֪ʽ(3��79)������
(5)�����d(Q����Q)
��ʽ(3��76)��(3��77)��(3��78)��֪
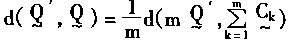 |
(3-81) | |
|
������
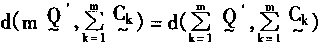
Ҳ��д��
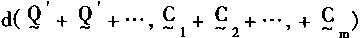
�ʴ�ʽ(3��79)������
 |
(3-82) |
| ��ʽ(3��72)������ |
|
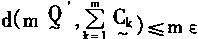 |
(3-83) | |
|
�ٴ�ʽ(3��81)��

|
|
3.2 �Ŵ��㷨 |
|
����Ľ�����һ��������Ż����̣���ͨ��ѡ����̭��ͻȻ���죬�����Ŵ��ȹ��ɲ�����Ӧ�����仯���������֡��Ŵ��㷨�Ǹ����������˼��������ó���һ��ȫ���Ż��㷨��
�Ŵ��㷨�ĸ�����������Bagley J.D��1967������ģ�����ʼ�Ŵ��㷨�����ۺͷ�����ϵͳ���о�����1975�꣬��һ�����Թ�������Michigan��ѧ��J.H.Holland��ʵ�С���ʱ������ҪĿ����˵����Ȼ���˹�ϵͳ������Ӧ���̡�
�Ŵ��㷨���GA(Genetic Algorithm)���ڱ�������һ�ֲ��������������ֱ�������������Ŵ��㷨��ģʽʶ�������硢ͼ����������ѧϰ����ҵ�Ż����ơ�����Ӧ���ơ������ѧ������ѧ�ȷ��涼�õ�Ӧ�á����˹������о��У�����������Ϊ���Ŵ��㷨������Ӧϵͳ��ϸ���Զ����������������˹�����һ�������ǶԽ��ʮ��ļ��㼼�����ش�Ӱ��Ĺؼ���������
3��2��1 �Ŵ��㷨�Ļ�������
�Ŵ��㷨�Ļ���˼���ǻ���Darwin�����ۺ�Mendel���Ŵ�ѧ˵�ġ�
Darwin����������Ҫ������������ԭ��������Ϊÿһ�����ڷ�չ��Խ��Խ��Ӧ����������ÿ������Ļ��������ɺ�����̳У�������ֻ����һЩ���ڸ������±仯���ڻ����仯ʱ��ֻ����Щ����Ӧ�����ĸ����������ܱ���������
Mendel�Ŵ�ѧ˵����Ҫ���ǻ����Ŵ�ԭ��������Ϊ�Ŵ������뷽ʽ����ϸ���У����Ի�����ʽ������Ⱦɫ���ڡ�ÿ�������������λ�ò�����ij���������ʣ����ԣ�ÿ����������ĸ���Ի�������ij����Ӧ�ԡ�����ͻ��ͻ����ӽ��ɲ�������Ӧ�ڻ����ĺ������������ȥ�ӵ���Ȼ��̭����Ӧ�ԸߵĻ���ṹ���Ա���������
�����Ŵ��㷨���ɽ����ۺ��Ŵ�ѧ������������ֱ�������Ż��������ʶ�������㷨��Ҫ�õ����ֽ������Ŵ�ѧ�ĸ����Щ�������£�
һ����(String)
���Ǹ���(Individual)����ʽ�����㷨��Ϊ�����ƴ������Ҷ�Ӧ���Ŵ�ѧ�е�Ⱦɫ��(Chromosome)��
����Ⱥ��(Population)
����ļ��ϳ�ΪȺ�壬����Ⱥ���Ԫ��
����Ⱥ���С(Population Size)
��Ⱥ���и����������ΪȺ��Ĵ�С��
�ġ�����(Gene)
�����Ǵ��е�Ԫ�أ��������ڱ�ʾ�����������������һ����S��1011�������е�1��0��1��1��4��Ԫ�طֱ��Ϊ�������ǵ�ֵ��Ϊ��λ����(Alletes)��
�� �������(Gene Position)
һ�������ڴ��е�λ�ó�Ϊ����λ�ã���ʱҲ��ƻ���λ������λ���ɴ��������Ҽ��㣬�����ڴ�S��1101�У�0�Ļ���λ����3������λ�ö�Ӧ���Ŵ�ѧ�еĵص�(Locus)��
������������ֵ(Gene Feature)
���ô���ʾ����ʱ�����������ֵ�����������Ȩһ�£������ڴ�S=1011�У�����λ��3�е�1�����Ļ�������ֵΪ2������λ��1�е�1�����Ļ�������ֵΪ8��
�ߡ����ṹ�ռ�SS
�ڴ��У�����������������ɵĴ��ļ��ϡ�����������ڽṹ�ռ��н��еġ����ṹ�ռ��Ӧ���Ŵ�ѧ�еĻ�����(Genotype)�ļ��ϡ�
�ˡ������ռ�SP
���Ǵ��ռ�������ϵͳ�е�ӳ�䣬����Ӧ���Ŵ�ѧ�еı�����(Phenotype)�ļ��ϡ�
�š�������
����Ӧ�Ŵ�ѧ�е���λ����(Epistasis)
ʮ����Ӧ��(Fitness)
��ʾijһ������ڻ�������Ӧ�̶ȡ�
�Ŵ��㷨����һЩ�����ĸ����Щ�����ڽ����Ŵ��㷨��ԭ����ִ�й���ʱ���ٽ���˵����
3��2��2�Ŵ��㷨��ԭ��
�Ŵ��㷨GA������Ľ��ʾ�ɡ�Ⱦɫ�塱�����㷨��Ҳ�����Զ����Ʊ���Ĵ������ң���ִ���Ŵ��㷨֮ǰ������һȺ��Ⱦɫ�塱��Ҳ���Ǽ���⡣Ȼ����Щ�������������ġ��������У��������������ԭ����ѡ�������Ӧ�����ġ�Ⱦɫ�塱���и��ƣ���ͨ�����棬������̲�������Ӧ��������һ����Ⱦɫ�塱Ⱥ��������һ��һ���ؽ��������ͻ�����������Ӧ������һ����Ⱦɫ�塱�ϣ���������������Ž⡣
һ���Ŵ��㷨��Ŀ��
���͵��Ŵ��㷨CGA(Canonical Genetic Algorithm)ͨ�����ڽ��������һ��ľ�̬���Ż����⣺
���Ƕ���һȺ����ΪL�Ķ����Ʊ���bi��i��1��2������n����
bi��{0,1}L (3-84)
����Ŀ�꺯��f����f(bi)������
0i)<��
ͬʱ
f(bi)��f(bi+1)
��������ʽ
max{f(bi)|bi��{0,1}L} (3-85)
��bi��
�����ԣ��Ŵ��㷨��һ�����Ż���������ͨ���������Ŵ��������Ӹ�����ԭʼ��Ⱥ�У����Ͻ��������µĽ⣬���������һ���ض��Ĵ�bi������������Ž⡣
�����Ŵ��㷨�Ļ���ԭ��
����ΪL��n�������ƴ�bi(i��1��2������n)������Ŵ��㷨�ij���Ⱥ��Ҳ��Ϊ��ʼȺ�塣��ÿ�����У�ÿ��������λ���Ǹ���Ⱦɫ��Ļ����ݽ��������Ⱥ��ִ�еIJ��������֣�
1��ѡ��(Selection)
���Ǵ�Ⱥ����ѡ�������Ӧ�����ĸ��塣��Щѡ�еĸ������ڷ�ֳ��һ��������ʱҲ����һ����Ϊ����(Reproduction)��������ѡ�����ڷ�ֳ��һ���ĸ���ʱ���Ǹ��ݸ���Ի�������Ӧ�ȶ������䷱ֳ���ģ��ʶ���ʱҲ��Ϊ�Ǿ�������(differential reproduction)��
2������(Crossover)
������ѡ�����ڷ�ֳ��һ���ĸ����У���������ͬ�ĸ������ͬλ�õĻ�����н������Ӷ������µĸ��塣
3������(Mutation)
������ѡ�еĸ����У��Ը����е�ijЩ����ִ������ת�����ڴ�bi�У����ijλ����Ϊ1����������ʱ���ǰ������0�����෴֮��
�Ŵ��㷨��ԭ�����Լ�Ҫ�������£�
choose an intial population
determine the fitness of each individual
perform selection
repeat
perform crossover
perform mutation
determine the fitness of each individual
perform selection
until some stopping criterion applies
������ָ��ij�ֽ�����һ����ָ�������Ӧ�ȴﵽ�����ķ�ֵ�����߸������Ӧ�ȵı仯��Ϊ�㡣
�����Ŵ��㷨�IJ��������
1����ʼ��
ѡ��һ��Ⱥ�壬��ѡ��һ���������ļ���bi��i=1��2��...n�������ʼ��Ⱥ��Ҳ������������ļ��ϡ�һ��ȡn��30-160��
ͨ����������������������ļ���bi,i��1��2��...n����������Ž⽫ͨ����Щ��ʼ���������������
2��ѡ��
������������ԭ��ѡ����һ���ĸ��塣��ѡ��ʱ������Ӧ��Ϊѡ��ԭ����Ӧ�����������������棬����Ӧ����̭����Ȼ����
����Ŀ�꺯��f����f(bi)��Ϊ����bi����Ӧ�ȡ���
 |
(3-86) | |
|
Ϊѡ��biΪ��һ������Ĵ�����
��Ȼ����ʽ(3��86)��֪��
(1)��Ӧ�Ƚϸߵĸ��壬��ֳ��һ������Ŀ�϶ࡣ
(2)��Ӧ�Ƚ�С�ĸ��壬��ֳ��һ������Ŀ���٣���������̭��
�������Ͳ����˶Ի�����Ӧ������ǿ�ĺ���������������Ƕ�����������ѡ��������Ž�Ͻӽ����м�⡣
3������
����ѡ�����ڷ�ֳ��һ���ĸ��壬�����ѡ�������������ͬλ�ã����������P����ѡ�е�λ��ʵ�н�����������̷�ӳ�������Ϣ������Ŀ�����ڲ����µĻ�����ϣ�Ҳ�������µĸ��塣����ʱ����ʵ�е��㽻����㽻�档
�������
S1=100101
S2=010111
ѡ�����ǵ����3λ���н������������
S1=010101
S2=100111
һ����ԣ��������P��ȡֵΪ0.25��0.75��
4������
���������Ŵ��л�������ԭ�����Ա������Pm��ijЩ�����ijЩλִ�б��졣�ڱ���ʱ����ִ�б���Ĵ��Ķ�Ӧλ������1��Ϊ0����0��Ϊ1���������Pm��������켫С�����һ�£����ԣ�Pm��ȡֵ��С��һ��ȡ0.01-0.2��
�������S��101011��
����ĵ�1��4λ�õĻ�����б��죬����
S'=001111
�������첻��������еõ��ô������ǣ����ܱ�֤�㷨���̲�������������ĵ�һȺ�塣��Ϊ�����еĸ���һ��ʱ���������������µĸ���ģ���ʱֻ�ܿ���������µĸ��塣Ҳ����˵������������ȫ���Ż������ʡ�
5��ȫ����������(Convergence to the global optimum)
�����Ÿ������Ӧ�ȴﵽ�����ķ�ֵ���������Ÿ������Ӧ�Ⱥ�Ⱥ����Ӧ�Ȳ�������ʱ�����㷨�ĵ��������������㷨�����������þ���ѡ���桢�������õ�����һ��Ⱥ��ȡ����һ��Ⱥ�壬�����ص���2����ѡ�����������ѭ��ִ�С�
ͼ3��7�б�ʾ���Ŵ��㷨��ִ�й��̡�

ͼ3-7 �Ŵ��㷨ԭ�� |
|
3��2��3�Ŵ��㷨��Ӧ��
�Ŵ��㷨�ںܶ����õ�Ӧ�ã����������о��ĽǶ��Ͽ��ǣ�����ĵ����Ŵ��㷨���������Ӧ�á����Ŵ��㷨Ӧ���У�Ӧ����ȷ���ص�ؼ����⣬���ܶ������㷨�����˽⣬���Ӧ�ã��Լ���һ���о�������
һ���Ŵ��㷨���ص�
1���Ŵ��㷨���������м���ʼɩ���������Ǵӵ����ʼ��
�����Ŵ��㷨�봫ͳ�Ż��㷨�ļ������𡣴�ͳ�Ż��㷨�Ǵӵ�����ʼֵ���������Ž�ģ���������ֲ����Ž⡣�Ŵ��㷨�Ӵ�����ʼ�����������������ȫ�����š�
2���Ŵ��㷨���ʱʹ���ض��������Ϣ���٣������γ�ͨ���㷨����
�����Ŵ��㷨ʹ����Ӧֵ��һ��Ϣ����������������Ҫ�������������ֱ����ص���Ϣ���Ŵ��㷨ֻ����Ӧֵ�ʹ������ͨ����Ϣ���ʼ����ɴ����κ����⡣
3���Ŵ��㷨�м�ǿ���ݴ�����
�Ŵ��㷨�ij�ʼ���������ʹ��д��������Ž���Զ����Ϣ��ͨ��ѡ���桢���������Ѹ���ų������Ž�����Ĵ�������һ��ǿ�ҵ��˲����̣�������һ�������˲����ơ��ʶ����Ŵ��㷨�кܸߵ��ݴ�������
4���Ŵ��㷨�е�ѡ����ͱ��춼�����������������ȷ���ľ�ȷ����
��˵���Ŵ��㷨�Dz�����������������Ž�������ѡ�������������Ž��Ƚ����������������Ž�IJ���������������ȫ�����Ž�ĸ��ǡ�
5���Ŵ��㷨���������IJ�����
�Ŵ��㷨�Ļ���������ͼʽ�����������й��������£�
(1)ͼʽ(Schema)����
һ�������÷��ż�{0��1��*}��ʾ�����Ϊһ����ʽ������*������0��1�����磺H=1x x 0 x x��һ��ͼʽ��
(2)ͼʽ�Ľͳ���
ͼʽ��0��1�ĸ�����Ϊͼʽ�Ľף�����0(H)��ʾ��ͼʽ�е�1λ���ֺ����λ���ּ�ľ����Ϊͼʽ�ij��ȣ�������(H)��ʾ������ͼʽH��1x x0x x����0(H)��2����(H)��4��
(3)Hollandͼʽ����
�ͽף��̳��ȵ�ͼʽ��Ⱥ���Ŵ������н��ᰴָ���������ӡ���Ⱥ��Ĵ�СΪnʱ��ÿ��������ͼʽ��ĿΪ0(n3)��
�Ŵ��㷨���ִ���������Ϊ����������(Implicit Parallelism)����˵���Ŵ��㷨�����ھ��в��д��������ʡ�
�����Ŵ��㷨��Ӧ�ùؼ�
�Ŵ��㷨��Ӧ������ؼ�������������3��
1�����ı��뷽ʽ
�Ȿ����������롣һ�������ĸ��ֲ����ö����Ʊ��룬�����Ӵ���Ȼ����Ӵ�ƴ�ӹ��ɡ�Ⱦɫ�塱���������ȼ�������ʽ���㷨����Ӱ�켫��
2����Ӧ������ȷ��
��Ӧ����(fitness function)Ҳ�ƶ�����(object function)�������������Ʒ�ʵIJ�������������Ҳ��Ϊ����ġ���������һ����������ģ�ͺ�����Ϊ������������ʱ��Ҫ���й��졣
3���Ŵ��㷨���������趨
�Ŵ��㷨����������3������Ⱥ���Сn���������Pc�ͱ������Pm��
Ⱥ���Сn̫Сʱ����������Ž⣬̫������������ʱ�䡣һ��n��30-160���������Pc̫Сʱ������ǰ������̫���������ƻ�����Ӧֵ�Ľṹ��һ��ȡPc=0.25-0.75���������Pm̫Сʱ���Բ����µĻ���ṹ��̫��ʹ�Ŵ��㷨���˵��������������һ��ȡPm��0��01��0��2��
�����Ŵ��㷨���������е�Ӧ��
�Ŵ��㷨���������е�Ӧ����Ҫ��ӳ��3�����棺�����ѧϰ������Ľṹ��ƣ�����ķ�����
1���Ŵ��㷨������ѧϰ�е�Ӧ��
���������У��Ŵ��㷨�����������ѧϰ����ʱ��������������������
(1)ѧϰ������Ż�
���Ŵ��㷨��������ѧϰ����ʵ���Զ��Ż����Ӷ����ѧϰ���ʡ�
(2)����Ȩϵ�����Ż�
���Ŵ��㷨��ȫ���Ż������������Ե��ص����Ȩϵ���Ż��ٶȡ�
2���Ŵ��㷨����������е�Ӧ��
���Ŵ��㷨���һ�������������ṹ��������Ҫ�������ṹ�ı������⣻Ȼ�������ѡ���桢��������ó����Žṹ�����뷽����Ҫ������3�֣�
(1)ֱ�ӱ��뷨
���ǰ�������ṹֱ���ö����ƴ���ʾ�����Ŵ��㷨�У���Ⱦɫ�塱ʵ���Ϻ���������һ��ӳ���ϵ��ͨ���ԡ�Ⱦɫ�塱���Ż���ʵ���˶�������Ż���
(2)���������뷨
������������õı����Ϊ������������������ÿ����Ԫ�������㻥����ʽ����Ϣ��һ��Խ�������Ż���Ⱦɫ�塱���з�����Ȼ���������Ľṹ��
(3)����������
���ַ��������ڡ�Ⱦɫ�塱��ֱ�ӱ���������Ľṹ�����ǰ�һЩ���������������롰Ⱦɫ�塱�У�Ȼ�����Ŵ��㷨����Щ��������Ͻ��иı䣬��������ʺ����������������硣���ַ�������Ȼ�����������������һ�¡�
3���Ŵ��㷨����������е�Ӧ��
�Ŵ��㷨�����ڷ��������硣�����������зֲ��洢���ص㣬һ�����Դ������˽ṹֱ�������书�ܡ��Ŵ��㷨�ɶ���������й��ܷ��������ʷ�����״̬������
�Ŵ��㷨��Ȼ�����ڶ���������ʵ��Ӧ�ã�����Ҳչʾ����DZ���Ϳ���ǰ�������ǣ��Ŵ��㷨���д�����������Ҫ�о���ĿǰҲ���и��ֲ��㡣���ȣ��ڱ����࣬ȡֵ��Χ���������Χʱ�������ٶ��½�����Σ����ҵ����Ž⸽����������ȷȷ�����Ž�λ�ã�����Ŵ��㷨�IJ���ѡ����δ�ж������������Ŵ��㷨������Ҫ��һ���о�����ѧ�������ۣ�
����Ҫ��������֤�����������Ż����������Ӽ�ԭ�����о�Ӳ�������Ŵ��㷨���Լ��Ŵ��㷨��ͨ�ñ�̺���ʽ�ȡ� |
|
3��3 ģ���������ѧϰ |
|
��ģ���������У����ģ����������Ŀǰ���DZ�ʾһ���㷨��������������ѧϰ���⡣��νѧϰ����ָ����ģ��������ͳ���ģ����������Եġ�����һ���У��ֱ������ģ���������ѧϰ������ģ���������ѧϰ������
3��3��1 ��ģ���������ѧϰ�㷨
����ͼ3��1��ʾ��ģ����Ԫģ�͡���ͼ�У�xi��i��O��1������n����ģ�������źţ�Wj��j��0 ��1������n����ģ��Ȩϵ����
��ģ�����������Ԫģ������ʽ(3��3)�������ġ����ڡ�����Ԫ��ʽ(3��4)(3-5)��ʾ�������롱��Ԫ����ʽ(3��6)(3��7)��ʾ��
��Yd�����������ֵ��Yd��[-1��1]����Y��ģ����Ԫ��ʵ�����������������e:
e-Yd-Y��[-1,1]
ִ��ѧϰ��Ŀ�ľ�������Ԫ�е�Ȩϵ��W'���������g��ʹ����������e��С��ѧϰ�ṹ��ͼ��ͼ3��8��ʾ��
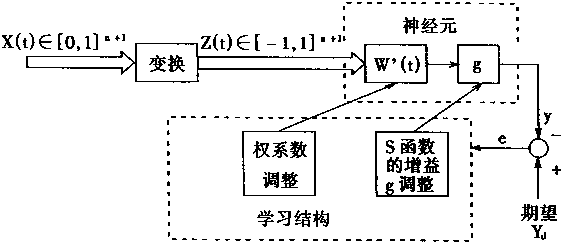
ͼ3-8 ģ����Ԫѧϰ��� |
|
���������ź�����[0��1]n+1��������ռ�ģ����ȱ任��[-1��1]n+1��������ռ䡣��������Ԫ�У���Ԫ�����Y����������ֵYd�Ƚϡ��������e��ѧϰ����������������ֱ��Ȩϵ��W�ͼ�������������g�����ġ�ʹ��Ԫ�����Y��������Yd��
������Ԫ�������Ȩϵ�������ֱ���ʽ(3��8)��ʽ(3��9)��ʾ��
X(t)=[X0(t),X1(t),...,Xn(t)]T��[0,1]n+1
W(t)=[W0(t),W1(t),...,Wn(t)]T��[0,1]n+1
��
Zi(t)=2Xi(t)-1
Wi'(t)=2Wi(t)-1
����
Z(t)=[Z0(t),Z1(t),...,Zn(t)]T��[-1,1]n+1
W'(t)=[W0'(t),W1'(t),...,Wn'(t)]T��[0,1]n+1
ģ����Ԫ��ѧϰ�㷨����
1��Ȩϵ��W'��ѧϰ�㷨
W'(t+1)=W'(t)OR ��W'(t)=S[W'(t),��W'(t)] (3-87)
����
��W'(t)=Z(t) AND e(t)=T|Z(t),e(t)|
2��S����������g��ѧϰ�㷨
g(t+1)=g(t) OR ��g(t)=S|g(t),��g(t)| (3-88)
����
��g(t)=u(t) AND e(t)=T[u(t),e(t)]
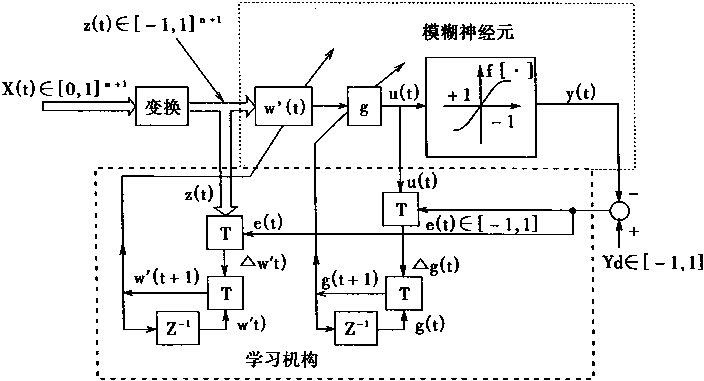
ͼ3-9 ģ����Ԫ��ѧϰ�ṹ |
|
������ʽ(3��87)�У������ģ����ԪȨϵ��ѧϰ���㷨����Ҳ��ʾ��һ��ģ���ṹ��ʵ��ģ�͡������ΪȨϵ�����ⲿ���˺���ͻ����֮���ģ����ϵ����ô��ģ���������ǿ���ͨ���������ѧϰ�ġ�
������ʽ(3��88)�У���gʵ�������ļ����������ȡ���Ϊ����gӰ��S������б�ʣ�������Ҳ��Ӱ����Ԫ�ܼ����������ȡ�
ģ����Ԫ��ѧϰ�ṹ��ͼ3��9����ʾ��
��ͼ3��9�У���������2��ѧϰ���ڣ�һ����Ȩϵ��W'��ѧϰ���ڣ���һ��������g��ѧϰ���ڣ�������������ġ��������������У����е�Z-1������ͼ�DZ�ʾ��ʱһ���������ڣ��ʶ���������ΪW'(t+1)ʱ�����ΪW'(t)������Ϊg(t+1)ʱ�����Ϊg(t)������˵��ʱZ-1��z�����崫�ݺ����ķ��ţ�������˫���ź�z(t)�е��źš�
3��3��2����ģ���������ѧϰ�㷨
����ģ��������Ҳ�Ƴ���ģ�������磬������ģ���������ѧϰ�㷨����������������Ҳͬʱ����ˣ������ⷽ����о������ж��֣�����Щ���������ص㣻�ڲ�ͬ�ij��Ϻ��������и��Ե��ŵ㡣1992�꣬Buckley��Hayashi�����ģ�������㷨��ͬʱ��Ishibuchi��������˻��ڡ��ؼ��ķ�������1994�꣬Buckley��Hayashi���ģ����������Ŵ��㷨��1995�꣬Ishibuchi��������˾�������ģ��Ȩ��ģ���������ѧϰ�㷨�������������һЩ�������㷨��
�ڸ���ѧϰ�㷨�У�����ʵ��������Ǿ�������ģ��Ȩ��ģ���������ѧϰ�㷨�����Ŵ�ѧϰ�㷨��
���ھ�������ģ��Ȩ��ģ���������ѧϰ�㷨�����ȿ���ģ������ģ����ʽ(3��20)��ģ����ʽ(3��23)��ģ��������ӳ��ʽ(3��25)����Щ���㶼����ˮƽ�ؼ��������ִ�еġ�
���ڦ��ؼ���Ϊ�˷�����д�����ﲻ����ʽ(3��58)�ı�ʾ�����������������ʾ������
����ģ����N�Ħ��ؼ�����N[��]��ʾ�������У�
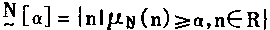 |
(3-89) |
���У�N(n)������������R��ȫ��ʵ������
����ģ������ˮƽ�ؼ���һ�������䣬�ʦ��ؼ�N[��]���Ա�ʾΪ |
|
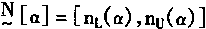 |
(3-90) |
����nL(��)��N[��]������ֵ��
nu(��)��N[��]������ֵ��
���������㷨��ģ�������������д�ɦ��ؼ������� |
|
 |
(3-91) | |
|


|
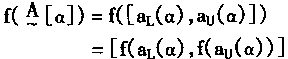 |
(3-93) |
| ��bu(��)>bL(��)>0������У���ʽ(3��92)���Լ�Ϊ |
|
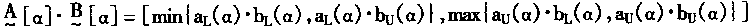
(3-94) | |
|
һ������ģ������������ļ���
����һ�������ǰ�������磬��I��ʾ����㣬H��ʾ���㣬O��ʾ����㡣���������롢�����Ȩϵ���ͷ�ֵ����ģ�������������ˡ����������ģ��������Ȩϵ���ͷ�ֵ������ģ����������ģ����������ͼ3��10��ʾ��
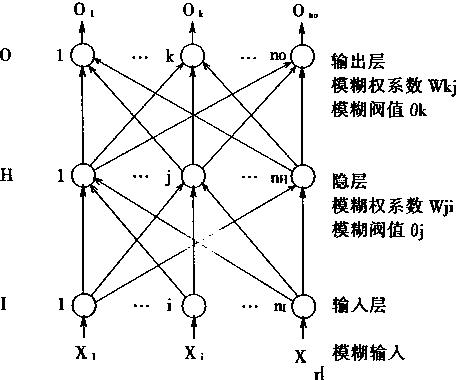
ͼ3-10 ģ�������� |
|
�����ԣ�����ͼ3��10��ʾ���������������������ϵ�����˲�����ΪIi:
Ii=Xi i=1,2,...,nI (3-95)
��������ΪHj��
Hj=f(Uj),j=1,2,...,nH (3-96)
 |
(3-97) |
���������ΪOk��
Ok=f(Uk),k=1,2,...,nO |
(3-98) |
 |
(3-99) | |
|
������(3��95)��(3��99)ʽ�У�Xi��ģ�����룬Wji��Wkj��ģ��Ȩϵ������j����k��ģ����ֵ��
Ϊ������㣬��ͼ3��10��ʾ��ģ���������У�����ˮƽ�ؼ����м��㡣���ڦ��ؼ�����ģ�����������������ϵ����дΪ����ʽ�ӣ�
��������㣬��
Ii[��]=Xi[��] (3-100)
�������㣬��
Hj[��]=f(Uj[��]) (3-101)
 |
(3-102) |
| ��������㣬��
Ok[��]=f(Uk[��]) (3-103) |
|
 |
(3-104) | |
|
������(3��100)��(3��104)ʽ�У����Կ������������ģ�������ؼ�����������룬����ͷ�ֵ�Ħ��ؼ���������ġ��������ģ�����Ħ��ؼ�Xi[��]�ǷǸ��ģ�����
Xi[��]=[XL(��),XU(��)] (3-105)
����
0��XL(��)��XU(��)
�Ӷ�����������㣬���㼰����㣬����������ʽ�Ӽ��㣺
1����������㣺
Ii[��]=Xi[��]=[XiL(��),XiU(��)] (3-106)
2���������㣺
Hj[��]=[hjL(��),hjU(��)]
=[f(UjL(��)),f(UjU(��))] (3-107)
����
 |
(3-108) |
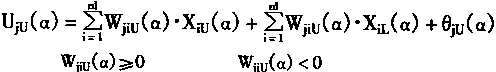 |
(3-109) | |
|
3�����������
Ok[��]=[OkL(��),OkU(��)]
=[f(UkL(��)),f(UkU(��))] (3-110)
����
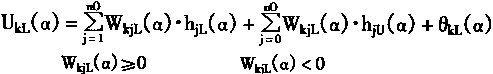 |
(3-111) |
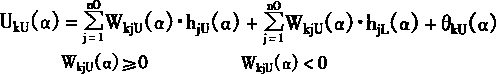 |
(3-112) | |
|
����ģ���������ѧϰ
��ģ���������ѧϰ������Ҫ����Ŀ�꺯����Ȼ�����ѧϰ�㷨��ʽ���ٸ���ѧϰ���衣
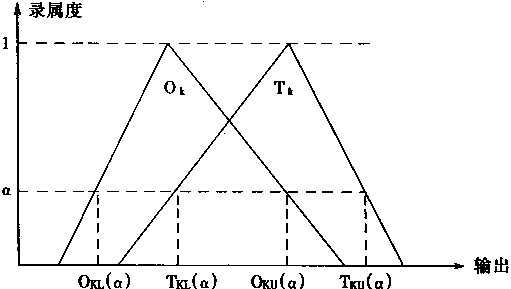
ͼ3-11 Ŀ�꺯�� |
|
1��Ŀ�꺯��
���Ƕ�Ӧ��ģ������Xi�� i��1��2������nI����Ŀ�����Tk�� k��1��2������nO����������ĵ�k�������Ok�Ħ��ؼ��Լ���Ӧ��Ŀ�����Tk�����Զ���Ŀ�꺯��e��
��ͼ3��11�У�ȡOk��Tk�Ħ��ؼ�������ֵ������ֵ������ƽ�������� ��ֵ���м�Ȩ��ΪĿ�꺯��e����
ek(��)=ekL(��)+ekU(��) (3-113)
���У�ekL( ��)��Ok��Tk�� ���ؼ�������ֵ�����ƽ���ġ���Ȩֵ��
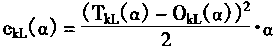 |
(3-114) |
| ekU(��)��Ok��Tk�Ħ��ؼ�������ֵ�����ƽ���� ����Ȩֵ�� |
|
 |
(3-115) |
| �Ӷ�Ok��Tk�Ħ��ؼ���Ŀ�꺯�����Զ���Ϊe( ��) |
|
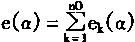 |
(3-116) |
| �����������Xi��Tk��Ŀ�꺯�����Ը������£� |
|
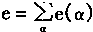 |
(3-117) | |
|
2��ѧϰ�㷨
��������ģ��Ȩϵ��Wkj��Wji����������������ʾ����
Wkj=(WkjL,WkjC,WkjU) (3-118)
���У�WkjL��Ȩϵ������Сֵ��������ؼ�������ֵ��
WkjC��Ȩϵ������ֵ�����䶥������Ӧ��ֵ��
WkjU��Ȩϵ�������ֵ��������ؼ�������ֵ��
Wji=(WjiL,WjiC,WjiU) (3-119)
���в����������Wkj�е���ͬ��
�����ԣ���
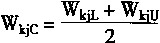 |
(3-120) |
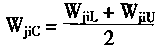 |
(3-121) | |
|
����Wkj�DZ�ʾ����������֮���Ȩϵ���������ȿ�����ѧϰ�㷨�������ݶȷ���������Ŀ�꺯����Wkj����������
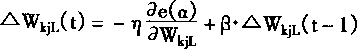 |
(3-122) |
 |
(3-123) | |
|
���У� ����ѧϰ������ �����ij�����
������ʽ(3-122)��(3-123)�У�˵������Ŀ�꺯��e��Ȩϵ������ؼ�����ֵWkjL�Լ�����ֵWkjU���ʶ�Ҳ������Ȩϵ��Wkj��
�����ԣ���ʽ(3��122)(3��123)�У��ؼ�������ȡ��
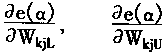
��e( ��)�Ķ����֪��e( ��)�ض���Ȩϵ��Wkj�ĺ������ʶ�Ҳ��Wkj�� ���ؼ���������ֵ�ĺ���������
e( ��)=g(WkjL( ��),WkjU( ��)) (3-124)
��WkjL��WkjU�ֱ���Wkj����ؼ���������ֵ�����֪��
WkjL( ��)��WkjL��WkjU�ĺ�����WkjU( ��)Ҳ��WkjL��WkjU�ĺ�����
��ȫ�ֵĽǶ����У�
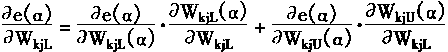 |
(3-125) |
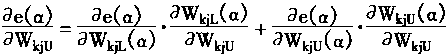 |
(3-126) | |
|
Ϊ����ʽ(3��125)(3��126)�Ľ���������ԣ���Ҫ���WkjL��WkjU��WkjL( ��)��WkjU( ��)֮��Ĺ�ϵ������Ȩϵ��Wkj��һ�����ǶԳ�ģ������������״��ͼ3��12��ʾ��
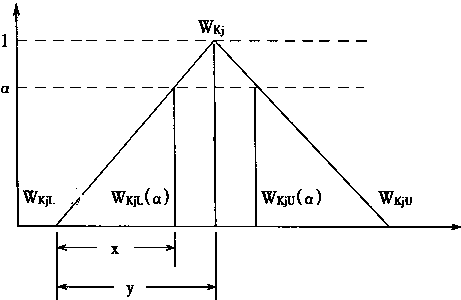
ͼ3-12 WkjL��WkjU��WkjL( ��)��WkjU( ��)�Ĺ�ϵʾ�� |
|
��ͼ3-12�У����Կ�����

���� X=��.Y
ʵ���ϣ�
����

��
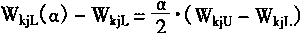
�����
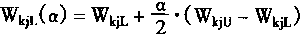 |
(3-127) |
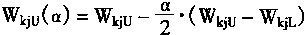 |
(3-128) |
| ��ʽ(3��127)(3��128)��дΪ������ʽ |
|
 |
(3-129) |
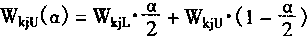 |
(3-130) |
����ʽ������˵��WkjL��WkjU��WkjL( ��)��WkjU( ��)�Ĺ�ϵ��
�Ӷ�ʽ(3��125)(3��126)��Ϊ�� |
|
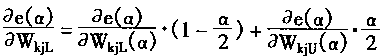 |
(3-131) |
 |
(3-132) | |
|
�����ԣ�Ҫ��ȡae( ��)/aWkjL��ae( ��)/WkjU�Ľ����Ӧ�������ae( ��)/aWkjL( ��)��ae( ��)/WkjU( ��)�Ľ�������ڴ�ʽ(3��110)��(3��115)��֪��e( ��)��UkL( ��)��WkjL( ��)֮�䣬e( ��)��UkU( ��)��WkjU( ��)֮����һ���ĺ�����ϵ���ʶ��У�
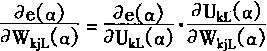 |
(3-133) |
 |
(3-134) | |
|
���ǣ�

���� OkL( ��)=f(UkL( ��))
��
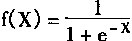
�ʶ�
f'(X)=f(X).(1-f(X))
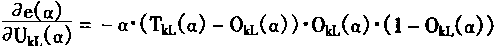 |
(3-135) |
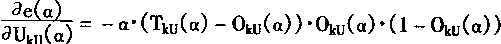 |
(3-136) | |
|
����aUkL( ��)/aWkjL( ��)��aUkU( ��)/aWkjU( ��)��Ӧ����WkjL( ��)��WkjU( ��)��ֵ��ͬ�������
(1)��0 ��WkjL( ��) ��WkjU( ��)ʱ
 |
(3-137) |
 |
(3-138) |
| (2)��WkjL( ��) ��WkjU( ��) ��0ʱ |
|
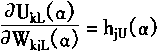 |
(3-139) |
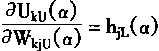 |
(3-140) |
| (3)��WkjL( ��)<0 ��WkjU( ��)ʱ |
|
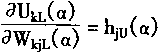 |
(3-141) |
 |
(3-142) | |
|
�����ԣ���ʽ(3��131)��(3��142)�������

��ֵ���Ӷ�ʽ(3��122)��(3��123)�ɽ⡣
��Գ�������ģ��Ȩϵ��Wkj���������湫ʽ����ѧϰУ��
WkjL(t+1)=WkjL(t)+ ��WkjL(t) (3-143)
WkjU(t+1)=WkjU(t)+ ��WkjU(t) (3-144)
 |
(3-145) | |
|
��У��֮���п��ܳ���WkjL>WkjU���������ʱ����
WkjL(t+1)=min{WkjL(t+1),WkjU(t+1)}
WkjU(t+1)=max{WkjL(t+1),WkjU(t+1)}
����ģ��Ȩϵ��Wji��ģ����ֵ ��j�� ��k��Ҳ���Բ���ģ��Ȩϵ��Wkj��У����������У����
3��ѧϰ����
������m��ģ���������������(XP��TP)��P��1��2������m������������ѧϰ�Ľؼ���n������ ��1�� ��2�� ��3��...�� ��n�������������£�ģ���������ѧϰ�㷨���²��裺
(1)��ģ����ϵ����ģ����ֵȡ��ֵ��
(2)�� ���� ��1�� ��2�� ��3��...�� ��n���ظ�ִ�е�(3)����
(3)��I=1��2������m���ظ�ִ�����й��̣�
������㣺��Ӧ��ģ����������Xp���������ģ������Op��������Op�ġ��ؼ������ޡ�
��������Ŀ�꺯��e( ��)��У���������ģ��Ȩϵ����ģ����ֵ��
(4)���Ԥ���Ľ�������δ�����㣬�ص�(2)��������У�������� |
|
3��3��3 ģ����������Ŵ�ѧϰ�㷨 |
|
��ģ���������У�Ҳ���Բ����Ŵ�ѧϰ�㷨�Բ�������ѧϰ������һ���У���һ�����������˵���Ŵ�ѧϰ�㷨��ģ�����������ѧϰ�е������������
һ��һЩ��������
����һ���У����������ǵ�ģ������ʵ��ģ������Ϊ�˼��������Щʵ��ģ������ʾΪ��A��B��������W��V��ģ����A��x���������ȱ�ʾΪA(x)��
ģ����A�����ؼ���ʾΪ��
A[��]={x|A(x)����},0<����1
�����������ģ�����Ķ��壺
��3������a
1����x��a����x��cʱ��N(x)=0��
��x��bʱ��N(x)=1��
2����[a��b]���䣬��(a��0)��(b��1)��y��N(x)��һ��ֱ�߶Σ�
��[b��c]���䣬��(b��1)��(c��0)��y��N(x)��һ��ֱ�߶Ρ�
ͬ�������Ը���������ģ�������壺
��3������a
1����x��a����x��cʱ��N(x)=0��
��x��bʱ��N(x)=1��
2����[a��b]���䣬y��N(x)��һ�����������ߣ�
��[b��c]���䣬y��N(x)��һ�����������ߡ�
����������ģ������������ģ����������ʾΪ��N��(a/b/c)��
���a��0�����N��0��
ģ����N��ģ����ȱ�ʾΪfuzz(N)�������У�
fuzz(N)��b��a
�����fuzz(M)��fuzz(N)�����M��N��ģ����
�����M(x)��N(x)��������x�����ʾΪM��N��
����ģ��������ṹ
����һ���У���������ģ��������������ǰ�����磬�������ˣ�Ȩϵ������ģ������ģ��������Ľṹ��ͼ3��13����ʾ��

ͼ3-13 ģ�������� |
|
��ͼ3��13�У�����X��Ȩϵ��w��v������ģ���������Y��Ŀ��T������������ģ������
���������֮�⣬���е���Ԫ���м�������y��f(x)������f��������R��[-t,t]�ķǵ�����ӳ�䣬t����������R��ʵ����
�������У���i����Ԫ������ΪIi���У�
Ii=X.Wi, 1��i��4 (3.146)
����i����Ԫ�����ΪZi��
Zi=f(Ii), 1
������㣬�����Ԫ������ΪI0
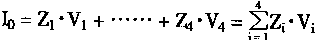 |
(3.148) | |
|
�����������������ΪY
Y=f(I0) (3.149)
Ϊ�˶�ģ�����������ѧϰ�����õ�ѵ������Ϊ
(X1,TI),1��I��L
���У�TI����x1Ϊ����ʱ����������
ѧϰ�У�ʵ�����ΪY1�� 1��I��L��
ͼ3��13����ʾ��ģ���������ѧϰ�������������Ϊx1ʱ����Ѱ���ŵ�Ȩϵ��Wi��Vi��ʹʵ�����Yl�ƽ���T1��1��1��L��
����ģ����������Ŵ�ѧϰ�㷨
�Ŵ��㷨��һ��ֱ���������������������Ҫ����������롢ѡ���桢����ȡ���ԭ����3��2������˵����������ֻ���Ż����̵�Ŀ�꺯����һЩ�������Խ��ܡ�
1��ģ����
��3��13��ʾ��ģ�������磬�Ż���Ŀ������Ѱ���ŵ�Ȩϵ��Wi��Vi��
Wi=(Wi1/Wi2/Wi3) (3.150)
Vi=(Vi1/Vi2/Vi3) (3.151)
����1��i��4
Wi2=(Wi1+Wi3)/2
Vi2=(Vi1+Vi3)/2
������ʽ��֪��ֻҪ֪��Wi1��Wi3��Vi1��Vi3���Ϳ���ȷ��Ȩϵ��Wi��Vi����ˣ��Ŵ��㷨ֻ���ģ��Ȩϵ��Wi��Vi��֧�ּ�������Ѱ�ż��ɡ���ˣ�Ⱥ��ĸ�������ʾΪP��
P=(W11,W13,......,V41,V43) (3.152)
P�ı�����ö���������
2���Ŵ��㷨���йز���
�Ŵ��㷨�IJ�����Ҫ��3�������Ƿֱ���Ⱥ����s�����泵c��������M��һ���ǰ��������ѡȡ���������Щ����ȷ�����£�
S��2000
C=0��8
M��0��0009
3���Ż���Ŀ�꺯��
��Y1�����ؼ�ΪY1[��]����
Yl[��]=[yl1(��),yl2(��)] (3.153)
��Tl�Ħ��ؼ�ΪTl[��]����
Tl[]=[tl1(��),tl2(��)] (3.154)
����{0,0.1,0.1,......,0.9,1.0}
����
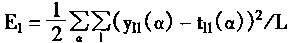 |
(3.155) |
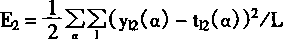 |
(3.156) | |
|
E=E1+E2
�Ŵ��㷨��Ŀ�ľ���Ѱ��ǡ����Ȩϵ��Wi��Vi��ֵ����0��
4��ģ��������ļ�������
ͼ3��13��ʾ��ģ���������У�����������ļ�������f���������£�
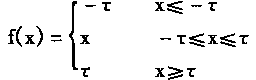 |
(3.157) | |
|
���У�t����������һ�����Ӧ�����ѡ��t��ֵ�����������Ŀ��ģ����T��[-1��1]����֮�ڣ������������t��ֵͨ��ȡ1��
�ġ�ѧϰ���
�����Ŵ��㷨��ͼ3��13��ģ�����������ѧϰ֮�ɵó��ڲ�ͬ�������Ҫ���µ�ѧϰ��������������һЩ�����ѧϰ�����
1����������
(1)��ͬģ����
�����������X1��Ŀ��TI�����ڣ�
fuzz(XI)��fuzz(TI)�� 1��I��L
���������������ͬģ���ȣ���Ƶ�ģ����
(2)��ģ��
�����������X1��Ŀ��T1�����ڣ�
fuzz(XI)uzz(TI), 1��I��L
������Ϊ��ģ����
(3)Ƿģ��
�����������X1��Ŀ��TI������
fuzz(XI)>fuzz(TI),1��I��L
������ΪǷģ����
2����ģ����ѧϰ���
ѵ��������ģ������F�������ʶ���
T=F(X) (3.158)
�����ǵ�ģ��ѧϰ���ʶ�����ѡȡ����Fʹ
fuzz(T)=fuzz(X)
�ʶ���ѡ������ʽ��
T=-X+1 (3.159)
�Ӷ�����X��[-1��1]����ʱ����T����[-2��2]���䡣
����ѵ���������±�3��1��ʾ��
��3-1 ��ģ��ѵ������
|
�� �� |
�� ��X |
�� ��T |
| 1 |
(-1/-0.75/-0.5) |
(1.5/1.75/2) |
| 2 |
(-0.25/0/0.25) |
(0.75/1/1.25) |
| 3 |
(0.5/0.75/1) |
(0/0.25/0.5) | |
|
�ڱ�3��1�У�ģ���������ǻ�������ģ����������(a��b��c)��ʽ��ʾ���ӱ��п����������ǶԳ�����ģ������
��ѧϰʱ������������ļ�������f��ȡʽ(3��157)����������������Ŀ��T����[-2,2]����tȡֵΪ2���������f������һ����ѧϰ��ƫ����Ӷ�ʹ���������ѧϰ-X+1�����õ�T������������£��Ŵ�ѧϰȡ�úܺõĽ�������ң���Ȩϵ��������ʵ����
3����ģ����ѧϰ���
ѵ�����ݲ������¹�ʽ������
T=A.X
���У�X��[-0��5��0��5]���䣬
A��(1��1��5��2)
�ʶ���Ŀ��T����[-1��1]���䡣
��Ȼ�У�fuzz(T)>fuzz(X)������ģ���Ľ����
ѵ�����ݸ������±�3��2��ʾ��
��3-2 ��ģ��ѵ������
| �� �� |
�� ��X |
fuzz(X) |
�� ��T |
fuzz(T) |
| 1 |
(-0.5/-0.25/0) |
0.5 |
(-1/-0.375/0) |
1 |
| 2 |
(-0.25/0/0.25) |
0.5 |
(-0.5/0/0.5) |
1 |
| 3 |
(0/0.25/0.5) |
0.5 |
(0/0.375/1) |
1 | |
|
�ڱ�3��2�У�x������ģ������T��������ģ������
�������������У���������f�е�tȡֵΪ1�����е�Ȩϵ������ģ�������Ŵ��㷨 ��ѵ������ִ�кܺõ�ѧϰ������ʹƫ��E��0��
4��Ƿģ����ѧϰ���
ѵ�����������¹�ʽ������
T=1/X
���У�X����(-m��1)��[1��m]����ȡֵ���ʶ�T����[-1��1]�����С�
��Ȼ��Ƿģ�������fuzz(T)
Ϊ��ѵ������X��ֵ��[1��3]������ѡȡ��T��������ģ������
ѵ�����ݸ������±�3��3��ʾ��
��3-3 Ƿģ��ѵ������
| �� �� |
�� ��X |
fuzz(X) |
�� ��T |
fuzz(T) |
| 1 |
(1/1.25/1.5) |
0.5 |
 |
1/3 |
| 2 |
(1.5/1.75/2) |
0.5 |
 |
1/6 |
| 3 |
(2/2.25/2.5) |
0.5 |
 |
1/10 |
| 4 |
(2.5/2.75/3) |
0.5 |
 |
1/15 | |
|
�������У���������f�е�tȡֵΪ3��
ģ�������粻�ܶ���Щѵ�����ݽ���ѧϰ������Ҫԭ������ʽ(3��157)����ʾ�ļ�������������ѹ�����������������T��1��x���ַ����Ժ����ıƽ������f���÷�����ѹ�����������Ϻý���ѧϰ�� |
|
������ ��ģ������ |
|
��������ȥʵ��ģ���������Ϊ��ģ������(Neuro-Fuzzy Control)����ģ��������������Ӧ�õ�һ����Ҫ�������ֿ����������˵����ܹ������������ѧϰ���Ӷ��ɶ�ģ������ϵͳʵ���Ż���
��ģ�����������ֲ�ͬ��ʵ�ַ�����һ�����ó�����Ԫ��ģ����Ԫ�������ʵ��ģ�����ƣ���һ������ģ����Ԫ�������ʵ�ֿ��ơ�
ģ��������FNN3�ǵ��͵����磬Buckley����֤����FNN3��һ�ֵ���ӳ�䣬�ʶ�FNN3����ͨ�ñƽ����������ģ��������HFNN����ͨ�ñƽ�����
ģ�����ƵĿ���������е��������������ԣ�ģ���������������ģ�����ơ�ģ�������н϶����Mamdani�Լ�Takagi-Sugeno����������Mamdani���������ƹ�����ʽΪ��
Ri��if x is Ai and y is Bi then Z is Ciÿ������Ļ���ǿ��Ϊ��
��i=��Ai(X0)����Bi(y0) (4.1)
���У�X0��Y0Ϊ���롣
��ӿ��ƹ����еõ��Ŀ���Ϊ��
��c(z)��Vi[��i��ci(z)] (4.2)
����Takagi-Sugeno���������ƹ������ʽΪ��
Ri��if x is Ai and y is Bi then Z=fi(x,y)ÿ������Ļ���ǿ��Ϊ
��i=��Ai(X0)����Bi(y0)
������п��ƹ����ƵõĽ��Ϊ
 |
(4.3) | |
|
�����Զ���Mamdani����������ģ����Ԫ�Ϳ��Խ���ģ��������������Takagi-Sugeno����������Ҫ������Ԫ��ģ����Ԫ��ɵ���������ɡ��ʶ�����ͬ��������ʽ��Ӧ��ģ��������������ͬ��
4��1 ��ģ��������
��ģ�����������������繹�ɵ�ģ������������ģ������������ģ�����Ƶĺ��ġ���ģ����������������ǽṹ��ѧϰ���⡣
��ģ���������ĽṹӦ����һ�����������˽ṹ�������Դ���ģ����Ϣ���������ģ��������
��ģ����������ѧϰ����һ�������ģ���������������ѧϰ��
����һ���У�������ģ���������Ľṹ��ѧϰ�㷨��
4��1��1 ����Ԫ��ɵ���ģ��������
����Ԫ��ģ����Ԫ��һ�����ͣ�������Ԫ���Թ���ִ��Mamdani������ģ����������������ģ���������У�ÿ�����ƹ��������һ��ģ��������ʵ�֡�
һ��ģ������ϵͳ�IJ���
����һ��ģ�����ƵĹ��̣����Ҿ�������Լ���IJ�����
��ʱ��tʱ������Ϊu(t)�����Ϊy(t)�������Ϊs����SҲ�������Ŀ��ֵ��
���������ΪT��������ɢʱ��t��T��2T����ʱ��������м�⡣��ƫ�ƫ��仯����ȡ���£�
e(t)=y(t)-s (4.4)
��e(t)=[e(t)-e(t-T)]/T (4.5)
����ģ���������������Ϊe(t)����e(t)��ģ��ֵ���ΪO(t)����ģ����������ΪU(t)��
ģ���������Ŀ��ƹ���Ϊ��
Rr��if e=Ai and ��e=Bi then O=Cp
1��r��g
����ģ���������У��ؼ�������θ�������e����e���õ�0��Ҳ����ʵ��ģ�����ƹ���
��Ai��[a1��b1]��Bj��[a2��b2]��Cp��[a3��b3]������e����e��O�������У�ѡȡ������ɢ�ĵ㣺
1����[a1��b1]��ȡ����ɢ��ΪXi�������У�
Xo=a1 (4.6)
Xi=a1+i(b1-a1)/N1 (4.7)
���У�1��i��N1��N1Ϊ��������
2.��[a2��b2]��ȡ����ɢ��Ϊyi��������
yo=a2 (4.8)
yi=a2+i(b2-a2)/N2 (4.9)
���У�1��i��N2��N2Ϊ��������
3����[a3,b3]��ȡ����ɢ��ΪZi��������
Zo=a3 (4.10)
Zi=a3+i(b3-a3)/N3 (4.11)
���У�13��N3Ϊ��������
���ڸ�����ģ�����ƹ����е�ģ����Ai��Bj��Cp������ɢ�������ȣ�
Ai(xj),0��j��N1
Bj(yk),0��k��N2
Cp(Zi),0��i��N3
����ʵ�ֿ��ƹ����������
����Ԫ��ɵ�ģ����������ͼ4��1����ʾ������m��������Ԫ���ֱ��ʾΪI1��I2����Im��ͬʱ��n�������Ԫ���ֱ��ʾΪQ1��Q2������Qn��
��ѵ�����ݼ�Ϊ����Vk��Ŀ��Dk��1��k��K������Vk��Dk����������
Vk=(Vk1,Vk2,����,Vkm) (4.12)
Dk=(Dk1,Dk2,����,Dkn) (4.13)
�ڸ�������ΪVkʱ�����������Qk��
Qk=(Qk1,Qk2,����,Qkn) (4.14)
��������ԪIj�������ԪQi֮���Ȩϵ��Ϊrji��i��1��2��������n�� j��1��2��������m��
�������ԪQi����ƫ������i��������ʾ��i���������У�
��=(��1,��2,����,��n) (4.15)
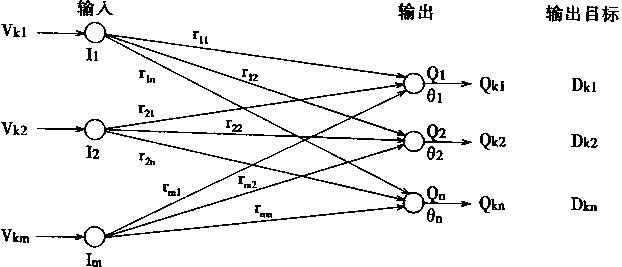
ͼ4-1 ģ�������� |
|
��ͼ4��1�У���Ԫ������Ԫ���ʶ�����������Vk���������

Ҳ������һ��ͨʽ��ʾ�������е�n��ʽ��
Qki=[(Vk1��rli)��......��(Vkm��rmi)]�Ŧ�i (4.16)
1��i��n
��ͼ4��1�У�������Vk������һ������������ƫ���������ɡ���������������
 |
(4.17) | |
|
��������������������������������������
Qk=(VkoR)�Ŧ� (4.18)
����ģ�����������ԣ����������ɿ��ƹ�����ɡ����ڿ��ƹ���
Rr:if e=Ai and ��e=Bj then Q=Cp
1��r��g
�������һ��������ģ��ʵ��һ�����������n��������ģ�������ʵ��n������Ҳ����ʵ��һ��ģ����������
����˵�������һ��������ģ��ʵ��һ�����ƹ���
��ͼ4��1��ʾ��������ɿ���һ��ģ�顣����ʽ(4��6)(4��7)����ʾ��ģ����Ai��ȡ����ɢ����N1+1����ʽ(4��8)(4��9)����ʾ��ģ����Bj��ȡ����ɢ����N2+1����ʽ(4��10)(4��11)����ʾ��ģ����Cp��ȡ����ɢ����N3+1������ͼ4��1��ʾ��������ģ���С�
m=(N1+1)+(N2+1)=N1+N2+2 (4.19)
n=N3+1 (4.20)
�����˵�m����Ԫ�У������е�N1+1����Ԫ��������Ai�����е�N2+1����Ԫ��������Bj���������n����Ԫ����Ŀ��Cp�����Դ˽���ѧϰ���������ѧϰ����ʱ���õ���ʵ��һ�������һ��������ģ�顣ѧϰʱ��
Ai(X0)����I1
Ai(X1)����I2
����
Ai(XN1)����IN1+1
��ͬʱ
Bj(y0)=IN1+2
Bj(y1)=IN1+3
����
Bj(yN2)=Im
���ң����Ŀ��Ϊ��
Cp(Z0)����Q1
Cp(Z1)����Q2
����
Cp(ZN3)����Qn
�ڿ��ƹ����У�һ����g�����������g��������ģ�飬�����ʵ��ģ�������������������������ģ����������
4��1��2 ��ģ����������ѧϰ�㷨
ͼ4��1��ʾ��������������ɵ���ģ�������������øĽ����ݶȷ�����ѧϰ��
�������ѵ������ΪVk��Ŀ��ΪDk��1��k��K�����ң�
Vk=(Vk1,Vk2,��,Vkm)
Dk=(Dk1,Dk2,��,Dkn)
��ͼ4��1��ʾ������������ΪVkʱ��ʵ�����ΪQk��ѧϰ��Ŀ�ģ�������Qk�ƽ���Dk��ʵ���ϣ������������Ȩϵ��rji��ʹ������IJ��Qk����Ŀ��Dk��������֮��Ҳ����ʹʽ(4��18)�е�Qk��Dkʱ�������R������
Dk=(VkoR)�Ŧ� (4.21)
������Dk��Vk��������R��
Ϊ�˽���ѧϰ��ȡĿ�꺯��J
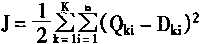 |
(4.22) |
| ѧϰ�㷨�Dz��øĽ����ݶ��㷨������㷨������������ʽ��ʾ |
|
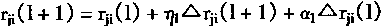 |
(4.23) |
 |
(4.24) | |
|
���У�l��1��2��3�������ǵ�������
��i��i��1��2����ѧϰ���ʣ�
��i��i��1��2���Ƕ���������
��ʽ(4��23)(4��24)�У���rji������i����������
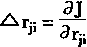 |
(4.25) |
 |
(4.26) |
| ������rji���ɼ������� |
|
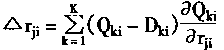 |
(4.27) |
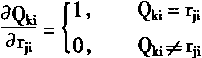 |
(4.28) | |
|
����ʽ(4��28)�����Խ������£��ٶ�m��2��n��1��ͬʱ�����±�k����������V1��V2������V1��Ȩϵ��r1������V2��Ȩϵ��r2�������ƫ����Ϊ����
��V1��0��7��V2��0��3��r1��1��r2��0��5������0�������ʽ(4��18)�У�

�ʶ���


��V1��0��7��V2��0��3��r1��0.6��r2��0��5������0�������ʽ(4��18)�У�

�ʶ���
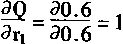

�����ԣ�ʽ(4��28)��������ǡ���ġ�
ͬ������������i���ɼ������£�
 |
(4.29) |
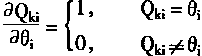 |
(4.30) | |
|
Ϊ�˱�֤rji(l+1)����i(l+1)��ֵ�ܴ���[0��1]���䣬�ʶ��������ӵ�Լ���������£�
1����ʽ(4��23)�У����ʽ���ұߵõ�����ֵС��0������rji(l+1)��0�����ʽ���ұߵõ�����ֵ����1������rji(l+1)��1��
2����ʽ(4��24)�У����ʽ���ұߵõ�����ֵС��0��������i(l+1)��0�����ʽ���ұߵõ�����ֵ����1��������i(l+1)��1��
ʽ(4.23)(4��24)����ʾ��ѧϰ�㷨����ѡ���rji���ij�ֵ��Ϊ���С��ڳ�ֵѡ��ʱһ��ѡ��i=0��
4��1��3 ������Ԫ��ɵ���ģ��������
��ģ�������������ɶ�����Ԫ��ɣ���Щ��Ԫ����������Ԫ������Ԫ������Ԫ��ģ����Ԫ�ȡ���ģ�����������ݲ�ͬ�����������в�ͬ�Ľṹ���������Ԫ��ͬ��������ͬ������������ṹҲ��ͬ��
һ��Mamdani������ģ��������
Mamdani�����������ʽ���£�
Ri��if x1=Ai1 and x2=Ai2 and ...... and xn=Ain then y=Bj
�������ź�Ϊ��ȷֵX0ʱ�У�
X0��{x01��x02��������x0n}
�����ǰ�����������ȣ�
Ai1(x01)��Ai2(x02)��������Ain(x0n)
���ڵ�i������������õ���ǰ�����ʺ϶�Wi��
Wi=Ai1(x01)��Ai2(x02)������������Ain(x0n) (4.31)
��i������������������Ϊ
Wi��Bi
ȫ��������X0����ʱ�õ����������Ϊ
B*��Ui(Wi��Bi) (4.32)
����Mamdani���������þ��������RBF(Radial Basis Function)Ϊ������������Ԫ������Ԫ������Ԫ����������ģ����������Ϊ�˷���˵��������ģ��������������ֻ��4�����ƹ���������
����ģ����������˵����2������x1��x2��1�����y��
����x1�Ŀռ��ģ������Ϊ����(L)����С��(S)������ʾΪA11��L��A21��S��
����x2�Ŀռ��ģ������ҲΪ����(L)����С��(S)������ʾΪA12��L��A22��S��
���y�Ŀռ��ģ������Ϊ����(L)����ƫ��(ML)�����С�(M)����С��(S)��
�Ӷ���4����������
if x1=L and x2=L then y=L
if x1=L and x2=S then y=ML
if x1=S and x2=L then y=M
if x1=S and x2=S then y=S
Ҳ����д�ɣ�
if x1=A11 and x2=A12 then y=B1
if x1=A11 and x2=A22 then y=B2
if x1=A21 and x2=A12 then y=B3
if x1=A21 and x2=A22 then y=B4
�������4�����ƹ������ģ����������ͼ4��2��ʾ��

ͼ4-2 Mamdani������ģ�������� |
|
�������ź�Ϊx10��x20ʱ���Ե�1��4����������ֱ����ǰ�����ʺ϶�ΪW1��W2��W3��W4��
W1=A11(x10)��A12(x20)
W2=A11(x10)��A22(x20)
W3=A21(x10)��A12(x20)
W4=A21(x10)��A22(x20)
�Ӷ�����Ӧ�ĵ�1��4����������������������ֱ��ǣ�
y1=W1��B1
y2=W2��B2
y3=W3��B3
y4=W4��B4
ȫ������������������ս��Ϊ
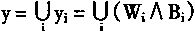 |
(4.33) |
| ���� |
|
 |
(4.34) | |
|
��ͼ4��2�С���ʾ��������һ����5�㣬���������һ��ģ��������������ֱ�˵���������������á�
��1�㣺��������ڵ㣬ֻ��������X1��X2��ֵ��
��2�㣺����ģ�����㡣�������Ԫ���þ��������Ϊ���������ġ����������һ���ø�˹���������κ��������κ����������κ�����������������ڱ���ģ����������������
��˹����(Gaussian function)�ı���ʽ���£�
G(x��a,c)=exp{-[(x-c)/a]2} (4.35)
���У�c�Ǻ��������ģ�
a�Ǻ����Ŀ��ȡ�
��˹��������״��ͼ4��3��ʾ��
���κ���(Bell shape function)�ı���ʽ���£�
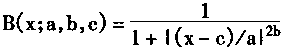 |
(4.36) | |
|
���У�c�Ǻ��������ģ�
a�Ǻ����Ŀ��ȣ�
b�DZ�Ե��б�ʲ�����
���κ�������״��ͼ4��4��ʾ����ͼ��Ҳ�������йز���a��b��c�����塣
ͼ4-3 ��˹����
ͼ4-4 ���κ��� |
|
���κ���(Trapezoidal function)�ı���ʽ����
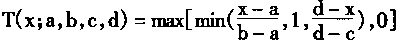 |
(4.37) |
���У�a��������ߵǶ������꣬
b��������߶��Ƕ������꣬
c�������ұ߶��Ƕ������꣬
d�������ұߵǶ������ꡣ
���κ�������״��ͼ4��5��ʾ��
�����κ���(Triangular function)�ı���ʽ���� |
|
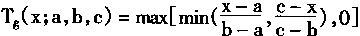 |
(4.38) | |
|
���У�a����������ߵǶ������꣬
b�������ζ��Ƕ������꣬
c���������ұߵ��Ƕ������ꡣ
ͼ4-5 ���κ���
�����κ�������״��ͼ4��6��ʾ

ͼ4-6 �����κ��� |
|
��Ȼ������������о�ȷ�ź�x���룬���ڵ�2��Ϳ����ھ�������������²�����Ӧ��������A(x)��
��3����ɿ��ƹ����ǰ�����ã�����������Ԫ�����ڲ���ÿ��������ʺ϶ȡ���ͼ4��2�У���2�����3��֮�������ӣ���û��Ȩϵ������Ȼ��
W1=A11(x1)��A12(x2)
W2=A11(x1)��A22(x2)
W3=A21(x1)��A12(x2)
W4=A21(x1)��A22(x2)
��4���ǻ���Ԫ����������ɿ��ƹ������Ĺ��ܣ�����ÿ�������Ӧ���������������������3�����4��֮�������Ȩϵ���ǿ��ƹ���ĺ��ģ�������ʶ��У�
y1=W1��B1
y2=W2��B2
y3=W3��B3
y4=W4��B4
��5��������㣬�����ڲ������ƹ�����������������ǻ���Ԫ���ڵ�4��͵�5��֮�������û��Ȩϵ�����ʶ��������У�
����Takagi-Sugeno��������ģ��������
T��S��������ʽ���Ա�ʾ���£�
if x is A and y is B then Z=f(x,y)
Ϊ�˷���˵�����⣬��������4������Ŀ��ƹ���
if x=A1 and y=B1 then Z=a10+a11x+a12y
if x=A1 and y=B2 then Z=a20+a21x+a22y
if x=A2 and y=B1 then Z=a30+a31x+a32y
if x=A2 and y=B2 then Z=a40+a41x+a42y
������4��������ǰ���������ʺ϶�
W1=A1(x)��B1(y)
W2=A2(x)��B2(y)
W3=A3(x)��B3(y)
W4=A4(x)��B4(y)
������4����������������
Z1=a10+a11x+a12y
Z2=a20+a21x+a22y
Z3=a30+a31x+a32y
Z4=a40+a41x+a42y
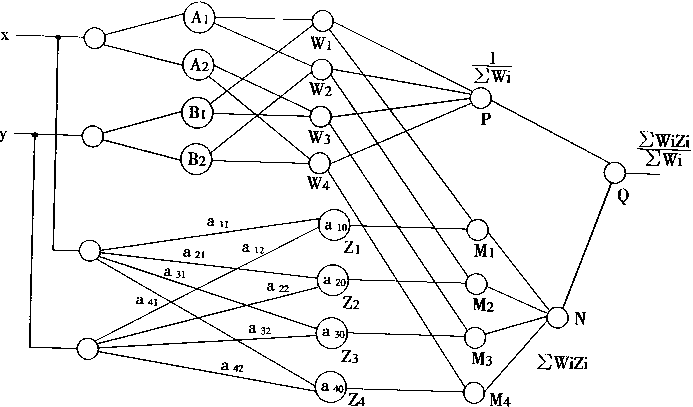
ͼ4��7 Takagi-Sugeno������ģ�������� |
|
������4������������������

|
|
�������T��S����������4���������������ͼ4��7��ʾ����ͼ4��7�е�����ֳ����²��֡��ϲ��ֺ���4�㣬�²���Ҳ��4�㣻���������ֵ������ͨ��һ����ԪQ�������������
����ֱ�˵�������������ֵĹ��ܡ�
1���ϲ�������
��1�㣺������㣬��ֻ��һ������ڵ㣬��������Ԫ��
��2�㣺��ģ�����㡣������Ԫ�ļ����������ø�˹�����Ⱦ��������������һ��ɲ��������������A1(x)��A2(x)��B1(y)��B2(y)��
��3�㣺ִ��ǰ���Ĺ��ܣ�Ҳ������ǰ�����ʺ϶ȡ�����������Ԫ��������
W1=A1(x)��B1(y)
W2=A1(x)��B2(y)
W3=A2(x)��B1(y)
W4=A2(x)��B2(y)
��4�㣻���͵�2��һ����Ҳ�dz�����Ԫ����3��͵�4��֮�������û��Ȩϵ�������ң��ڵ�4�����Ԫ�ļ�������Ϊ��
f(x)=1/x
�ʶ����У�
p=1/��Wi
2���²�������
��1�㣺���ϲ�������һ������һ��ֻ������ڵ㡣
��2�㣺���dz�����Ԫ�������ڵ�1��͵�2��֮���������Ȩϵ����Ȩϵ��Ϊa11��
a21��a31��a41��a12��a22��a32��a42������һ���У���Ԫ�ķ�ֵΪ-a10��-a20��-a30��-a40���ʶ��������
Z1=a10+a11x+a12y
Z2=a20+a21x+a22y
Z3=a30+a31x+a32y
Z4=a40+a41x+a42y
��3�㣺������ȡÿ������������ʺ϶ȣ���3��͵�2��֮�������û��Ȩϵ��������ĵ�3����ϲ�������ĵ�3������Ҳû��Ȩϵ�������ң���һ�����Ԫ�������Ԫ�����У�
M1=W1Z1 M2=W2Z2
M3=W3Z3 M4=W4Z4
��4�㣺���ڶԲ�3��������͡�������һ��������Ԫ����һ��͵�3������û��Ȩϵ�������Ҽ�������f(x)��x�����У�
N=��WiZi
3�����������ԪQ
���������ԪQ��һ�������Ԫ���������ö������ź���˻���Q��P��N������û��Ȩ���������ԣ�Q�����Ϊ

��Ȼ��ͼ4��7��ȫ����ʵ��������������ִ��T��S������4������Ĺ��ܡ�Ҳ��������һ�������T��S��������ģ���������� |
|
4��2��ģ������ϵͳ |
|
��ģ������ϵͳ������������Ϊ������ʵ��ģ���������Ƶ�ϵͳ��
ģ������ϵͳ��һ�������Ե�ȱ�㣺�������ȱ����Ч��ѧϰ���ơ���ģ������ϵͳ������֮�������ڿ������������ѧϰ���Ʋ���ģ������ϵͳԭ�е�ȱ�㣻
��ģ������ϵͳ���Ի����������Ӧģ������ϵͳANFIS(Adaptive Network-based Fuzzy Inference System)��ɵġ�ANFISҲ����Ӧ��ģ������ϵͳ(Adaptive Neuro-Fuzzy Inference System)����ǰ���й��½��������ܵ���ģ��������Ҳ���ǵ��͵�ANFIS��
���͵ķ�������ϵͳ��ͼ��ͼ4��8��ʾ�����ɿ������ͱ��ض�����ɡ����ض���һ����һ���ַ�����������Щ����˵���˱��ض���״̬x(t)�����ԡ������ڿ��������ԣ�ͨ������g��ʾ�侲̬��������Ҳ���DZ��ض���x(t)״̬�Կ�������u(t)��Ӱ�䡣
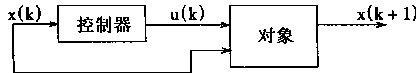
ͼ4-8 ��������ϵͳ��ͼ |
|
���ڿ�ͼ�����������·���
x(k+1)=f(x(k),u(k))
u(k)=g(x(k))
�ڿ��ƹ����У������ĵ������ǣ�Ϊ�˴ﵽԤ�ڵĿ���Ŀ�ģ�����Ҫ�ҳ���Ϊ�������״̬x�ĺ����Ŀ�������u��
�������繹��ģ����������������������ʵ��ģ��ӳ�䣻���Ҷ�һ�����ض�����п��ơ�
����һ���У��Ƚ�����ģ������ϵͳ���йؽṹ���ٽ�����ģ������ϵͳ�ľ���Ӧ�������
4��2��1 ��ģ������ϵͳ�ṹ
��ģ������ϵͳ�Ľṹ�Ǻ������õĿ��Ʒ�ʽ�йصġ���ģ�������ж��ֲ�ͬ�Ŀ��Ʒ�ʽ����Щ��ʽ����ģ�¾�����ƣ�����ƣ�ר��ѧϰ���ƣ��������Ի�����ģ���ƣ�������ʽ���ơ�����һ���֣��ֱ��Ҫ������Щ���Ʒ�ʽ������ϵͳ�Ľṹ��
һ��ģ�¾������
ģ�¾�������ڱ������ǰ����ǵľ�������ܽᣬȻ������ģ��������ģ���˵��йؾ��飬�Ӷ�ʵ�ֶԱ��ض���Ŀ��ơ�ģ��ר�ҵľ�����п�����ģ���������ı�����Ŀ�ġ���һЩ���ӵ�ϵͳ�����绯ѧ��Ӧ���̣�������������ͨϵͳ�ȣ������ר�ҿ��Ժܺõ�ʵ�ֿ��ƣ���ģ������������ģ����Щר�ң�ʵ�ֶԸ���ϵͳ����Ч���ơ�
һ�����ԣ�ר�Ҹ����ľ�������ģ���������ķ�ʽ�����ģ�����������е�ģ������������Ҳ�ϴֲڣ�������Ӧ��ʱ����Ҫ���н϶������������������¶�������������
������ģ��������������ģ�¾�����ƣ�����Բ����������ѧϰ���ƣ����������������Ϣ��������������ݵ�ѧϰ�������Ӷ����Զ����������������¶��塣���ȡ�ýϺ����Ľ����
���ַ��������������ڿ���ϵͳ�������Ŀ��ϵͳ���������ྭ�����ģ�£���ô�����õ���ģ������ϵͳ��ģ��ר��ϵͳ���ʶ������ַ���Ҳ��������ϵͳ��Ϻͷ�����
���������
���������ģ�����Ƶ�һ�ֿ��Ʒ�ʽ�����ֿ��Ʒ�ʽ��������������Ʒ�����
��ģ������Ƶ�������ͼ4��9��ʾ��Ϊ�˼����������豻���豸ֻ��һ�����״̬x(k)��һ������u(k)�����Ʒֳ������Σ���ѧϰ�κ�Ӧ�ýΡ�
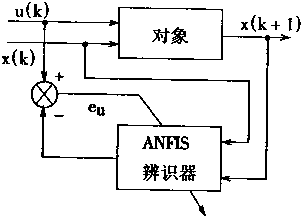
(a) |
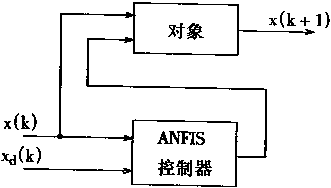
(b) | |
|
ͼ4-9 ��ģ�������
��ѧϰ�Σ�����������뼯�����Եõ����ض�������������Ӧ�����ѧϰ����ͼ4-9(a)��ʾ����ͼ�У�ANFIS����ѧϰ���ض������ģ�͡���ѧϰʱ��������������ź�u(k)�Լ�����ź�x(k)��x(k+1)��Щ��Ϣ��
��Ӧ�ýΣ�ϵͳ�Ľṹ��ͼ4��9(b)��ʾ�����ض������ģ������������ֱ�ӶԱ��ض�����п��ơ�����������ģ���Ǿ�ȷ�ģ�Ҳ����x(k)��x(k+1)��u(k)��ӳ���Ǿ�ȷ�ģ�ȷ�ģ�����u(k)ȥ�Զ�����п��Ʊض��ܲ������x(k+1)����������ƽ�����xd(k)�����ϵͳ�ڿ��ƵĽǶȽ���һ������������ʱϵͳ��
���ֿ��Ʒ���������ֻ��һ��Ψһ��ѧϰ����Ҳ����Ѱ�Ҷ������ģ�͡����Ҫ����һ���Ⱦ������������������ģ�ʹ��ڡ����ǣ��������еĶ��������ģ�ͣ���һ���������������[cu(k)]2����С��������ȷ������ϵͳ�����xd(k)-x(k)��2����С����
Ҫ�˷�������⣬�ɲ���ANFIS������Ӧ�����ϵͳ��
����ר��ѧϰ����
����������ڵ���Ҫ��������������������С��ȡ������ϵͳ�������С��������ģ�������У�ֱ��ʹϵͳ�����С����һ�ַ�������ν��ר��ѧϰ�����������ַ�����ͼ4-10����ʾ��
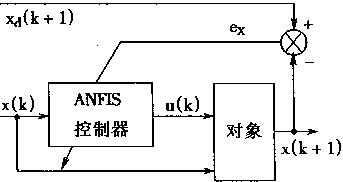
(a) |
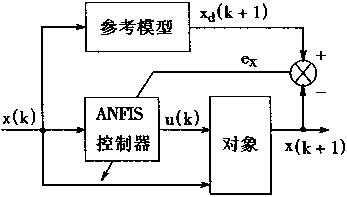
(b) | |
|
ͼ4-10 ��ģ�������
Ϊ��ʹ��������ź�ͨ��ͼ4��10�еĶ����ͼ���ʶ���Ҫ��ȡ���Դ����������ܵ�ģ�͡���ʵ�ϣ�Ϊ�˲���BPѧϰ�㷨����Ҫ֪��������ſɱȾ���(Jacobian matrix)���ڸþ����У���i��j�е�Ԫ�ص��ڶ���ĵ�i����������i������ĵ�����
���������ſɱȾ���������ȡ�������������������ʱ�̶Զ������߽������������仯�������Թ����ſɱȾ���
ר��ѧϰ���ƵĽṹ��ͼ4��10(a)����ʾ�������ź�Ϊxd(k+1)����ANFIS������������ϵͳ�����x(k)��Ȼ���ANFIS���u(k)�Լ�ϵͳ���x(k)��Ϊ��������ˡ��Ѷ������x(k+1)�����ź�xd(k+1)���бȽϣ����������ex���ڶ�ANFIS������У����У�����̲���BP�㷨�������ԣ�����������ϵͳ�������С��ΪĿ�����ѧϰ�ġ�
ͨ�����Dz�ϰ����ÿ��ʱ��kȥ��������Ķ������x(k)���ڲο�ģ����Ӧ�����У����������ϵͳ�����ܿ�����һ��ͨ�������Ե�ģ������ʾ�����ģ�Ϳ��Գɹ����������Ŀ�ġ����ַ�����ͼ4��10(b)����ʾ����ͼ�У���������xd(k+1)ͨ������ģ�Ͳ�����
�ġ��������Ի�����ģ������
������ʱ�����У���̬ϵͳ���˶����̿����õ��͵���ʽ��������
x(n)(t)=f(x(t),x(t),x(2)(t),......,x(n-1)(t))+bu(t) (4.39)
���У�f��δ֪����������
b�ǿ������档
ϵͳ���Ƶ�Ŀ����ʹ״̬����
X=[x,x,x(2),......,x(n-1)]T (4.40)
��������Ĺ켣
Xd=[xd,xd,xd(2),......,xd(n-1)]T (4.41)
��������������Ϊ
e=X-Xd (4.42)
�����Ŀ�������һ������u(t)��ʹ����t������ʱ��e����0��
���f����֪�ģ���ʽ(4��39)���Լ�Ϊ����ϵͳ��������һ���������Ի�ϵͳ��
��f��֪ʱ�������������u(t)��
u(t)=-f(X(t))+Xd(n)+kTe (4.43)
����ԭ�еķ�����ϵͳת��������ϵͳ��
e(n)(t)+k1e(n-1)+����+k(n-1)e+kn��0 (4.44)
���K��[kn��k(n-1)��������k1]T��ǡ��ѡ�����������Ӧ��֤����ʽ(4��44)�ջ�����ϵͳ�����ԡ�
����ʽ(4��39)�У�f��δ֪��������ֱ����Ӧѡ�����u(t)Ϊ��
u(t)=-F(X,p)+xd(n)+kTe+V (4.45)
���У�F�����Աƽ�f�IJ�����������
V�Ǹ������롣
�����ÿ���u(t)ʱ����õ��ıջ�ϵͳ�����������
1����ʽ(4��43)�У�kTe����ʽ(4��44)�����У�
u(t)=-f(X(t))+xd(n) (4.46)
2����ʽ(4��45)��(4��46)����
-f(x(t))+xd(n)��-F(X��p)+xd(n)+kTe+V
�Ӷ���
kTe=F(X,p)-f(X(t))-V
����
e(n)+k1e(n-1)+......+k(n-1)e+ku=(F-f)-V (4.47)
ʽ(4��47)��������ʽ(4��45)��ʾ�Ŀ���ʱ�õ��ıջ�ϵͳ��
�������������������⣺
1����Ҫ���IJ�������P��ʹ���������е�X����F(X��p)��f(x)
2����F�ƽ�f�����������У���Ҫ���ϸ��ӿ���V�Ա�֤�����ȶ��ԡ�
�����һ�����ⲻ�ѣ�����ģ��������Ϳ���ͨ������ѧϰ�ƽ�f��
����ڶ�����������Բ��û�ģ���ơ�
���ֿ��Ʒ�ʽֻ�����ڷ��������Ի���ϵͳ��
�塢�������Ʒ�ʽ
�������Ʒ�ʽ���������ű�����(Gain Scheduling Control)�������������ǿѧϰ(Reinforcement learning)���ȡ������ű�����һ������һ��Sugenoģ��ģ�ͣ����������һ�����ڸ��ӿ���ϵͳ�����ڶ���ģ�Ͳ�����Ļ��Ǻ���Ч�ģ����������ǿѧϰ������
4��2��2���͵���ģ������ϵͳ
��ģ������ϵͳ�����ö�����������ʵ�֡���Щ���������������ǰ�����磬Ҳ�����Ƿ������硣�ȿ�����ģ�������磬Ҳ�����þ����������Ҳ�����õ���������Ӧ������Ϊ������������Ԫ������һ���У�������ʮ�ֵ��͵����ӣ�һ���Dz���ģ��������������ӣ�һ���Dz��õ���������Ӧ�������������ӡ����ǹ����˽ṹ��ͬ����ģ������ϵͳ�������Ǹ����������Բ�ͬ���ص㣬����ѧϰ�϶���ȡ�ýϺõ�Ч����
һ��ģ���������繹�ɵĿ���ϵͳ
����һ�����ü�ģ����������SFIN(Simplified Fuzzy Inference Network)��ɵ���ģ������ϵͳ�����ڲ����������磬�ʶ���ϵͳ�еĿ���������У��ģ����������STFLC(Self-Tuning Fuzzy Logic Controller)����������ϵͳ���м�Ҫ���ܡ�
1����ģ����������
ģ������������ִ��Takagi-Sugeno�����Ŀ����������ǿ�����Ϊ�����뵥����ṹ�����ƹ�����������ʽ��
if X is Ai then yi=fi(X)
����X=[x1,x2,......,xm]T
Ai=[A1i,A2i,......,Ami]
fi(X)=[P0i+P1ix1+......+Pmixm]
i=1,2,......,n��
�ڿ��ƹ����У�X�����룻Ai��ģ������Aki�ǵ�kһ���������xk�ĵ�i��ģ������fi(X)�Ƕ�Ӧ������x�������Pki�ǵ�6�����к������ʽ�е�������ϵ����
���ڵ�i��������ƥ�����Di��ʾ��������
Di=A1i(x1)*A2i(x2)*......*Ami(xm) (4.48)
���У�x1��x2��������xmΪ���뾫ȷ��
A1i(x1)Ϊx1��A1i�������ȣ�����A1i(x2)��������Ami(xm)ͬ����
���еĿ��ƹ�������������Ϊy��
 |
(4.49) |
| ģ����Aki(xk)�����κ������˹������ʾ���ʶ��У� |
|
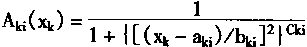 |
(4.50) | |
|
����
Aki(xk)=exp(-{[(xk-aki)/bki]2}cki) (4.51)
���У�aki��bki��cki�Ǻ����IJ������ı���Щ������Ч�������Ӧ�ı仯���ʶ�ģ��������״Ҳ�����仯��
��ϵͳ��һ��˫���뵥���ϵͳʱ����ģ����������Ľṹ��ͼ4��11��ʾ��
��������������������룬ÿ�����뱻���ֳ�3��ģ��������������x1����L1(��)��M1(��)��s1(С)��3��������������������x2����I2(��)��M2(��)��S2(С)��3�������������ʶ���9�����ƹ���
if x1 is L1 and x2 is L2 then y1=f1(x1,x2)
if x1 is L1 and x2 is M2 then y2=f2(x1,x2)
if x1 is L1 and x2 is S2 then y3=f3(x1,x2)
if x1 is M1 and x2 is L2 then y4=f4(x1,x2)
if x1 is M1 and x2 is M2 then y5=f5(x1,x2)
if x1 is M1 and x2 is S2 then y6=f6(x1,x2)
if x1 is S1 and x2 is L2 then y7=f7(x1,x2)
if x1 is S1 and x2 is M2 then y8=f8(x1,x2)
if x1 is S1 and x2 is S2 then y9=f9(x1,x2)
��Ӧ��ͼ4��11�е�ģ�����֣�������ռ䱻���ֳ�9��ģ���ӿռ䣬��ͼ4��12����ʾ��
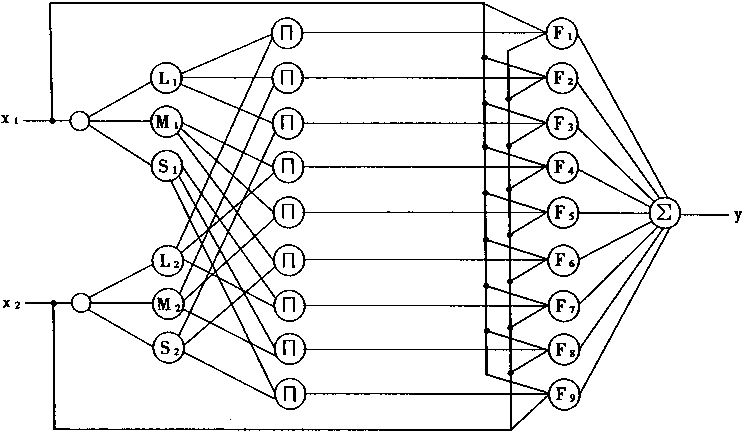
ͼ4-11 ��ģ����������SFIN |
|
ͼ4��11��ʾ��ģ�����������ʾ�Ŀ��ƹ����У�����ֻ���������룬�ʶ���
yi=fi(X)=fi(x1,x2), i=1,2,......,9
���ǣ�yi=p0i+p1ix1+p2ix2 (4.52)
�����ͼ4��11��ʾ����������Ż�������Ӧ���ڿ��ƹ����ǰ���ͺ�������Ż���
���Կ��ƹ������ǰ���Ż�ʱ��Ҳ��������ĵڶ�����Ԫ�����Ż�����ʱҲ���ǶԾ���������IJ���aki��bki��cki�����Ż�������k���������±�ţ���k��1��2��i�ǿ��ƹ��������ţ���i=1��2������9���ӿ��ƹ����п�֪����ģ������
A11=A12=A13=L1 A21=A22=A23=L2
A14=A15=A16=M1 A24=A25=A26=M2
A17=A18=A19=S1 A27=A28=A29=S2
���Կ��ƹ���ĺ�������Ż�ʱ��Ҳ���Ƕ�fi(x1��x2)�е�ϵ��p0i��p1i��p2i�����Ż���

ͼ4-12 ģ���ӿռ� |
|
2����ģ�����������Ż�
���ڼ�ģ����������SFIN�е�X1������ƫ���ź�e(k)��yd(k)-y(k)������yd(k)Ϊ�����źţ�y(k)Ϊ����ʵ������źš���x2������ƫ��仯����e(k)��e(k)-e(k-1)������SFIN���������������������ź���u(k)��u(k)-u(k-1)����SFIN���Կ���һ����������ģ����������
��SFIN���Ƕ����Ż����̡�һ����SFIN��ʼ���ļ���ѧϰ�Ż�����һ��SFIN����������Ӧѧϰ�Ż���
(1)SFIN�ij�ʼ������ѧϰ
��������SFIN��ʼ���Ľ�ʦ�ź����ݡ�
T{[e(i),��e(i)]������u(i)|i=1:N} (4.53)
����e(i)����e(i)������
��u(i)�������
��ʼ����ʦ��������ϵͳ������Ա�Ŀ������ݣ��Ż�ʱ���õ�Ŀ�꺯��ΪI0��
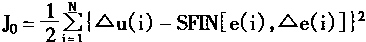 |
(4.54) |
���У�SFIN[e(i)��Ae(i)]��ʾ���ݶ�e(i)��Ae(I)����SFIN֮��õ��������
��W��ʾSFIN�е���ͨ����������������ʽ����У���� |
|
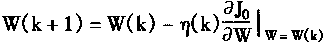 |
(4.55) | |
|
���У���(k)��ѧϰ���ʣ�1>��(k)>0��
(i)ǰ����������
ƫ��e��ȡ��ģ����������ʾΪNe��iƫ��仯����e��ȡ��ģ����������ʾΪN��e��
��������֪ʶ��ƫ��e��ƫ��仯����e�ı߽�ֱ��ǣ�
Se��e��Be
S��e�ܦ�e��B��e
��ǰ���ij�ʼ��������ѡ������
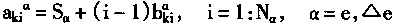
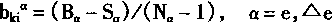

(ii)�����������
���Ͽ�֪����SFIN���п��ƹ���ΪNr����
Nr=Ne*N��e (4.56)
���ڿ��ƹ���ĺ��Ϊyi��fi(x)��p0i+p1ix1+p2ix2��Ҳ���в���p0i��p1i��p2i�����ԣ��ܵĺ������ΪNg��
Ng=3Nr (4.57)
Ҫ��ȡNg����������Ҫ����Ng�����������ʦ���ݶԣ�
{[e(q),��e(q)]������u(q)},q=1:Ng (4.58)
��ͨ����Ng�����ݶԲ����γ�Ng�����̵ķ����飮����ȡ�����Ng��������
����SFIN����Ng��[e(q)��e(q)]��q��1:Ng����ʱ�����ʽ(4��49)�У�
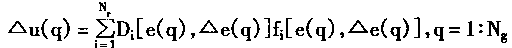 |
(4.59) |
| ������ʽ(4.59)�У���Ҫ��fi�еIJ���p0i,p1i,p2i�����д�� |
|
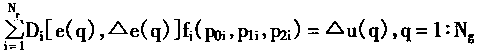 |
(4.60) | |
|
��P��ʾ���fi�IJ���������MΪDi��Ng*Ng����U��[��u(1)����u(2)����������u(Ng)]T����ʽ(4.60)����д�����¾�����ʽ��
MP=U (4.61)
��Ȼ�������ʽ(4��61)������
P=M-1U
�Ӷ��ɵú����������P��Ҳ���ó����������p0i��p1i��p2i��i��1:9��
(2)SFIN����������Ӧѧϰ�Ż�
ģ����������SFIN����Ϊģ���������ģ�������ɵ�ģ������ϵͳ�Ŀ�ͼ��ͼ4-13��ʾ��

ͼ4-13 ģ������ϵͳ |
|
�ڸ�����SFIN�ij�ʼ������֮������Զ�SFIN������������Ӧѧϰ�Ż������Ż�ʱ������������ָ�꣺
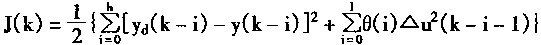 |
(4.62) |
���У�h��ƫ��ƽ���ۼӸ�����
l�Ǽ�Ȩ��������ƽ���ۼӸ�����
��(i)�Ǽ�Ȩ���ӡ�
����ʽ��yd(k-i)-y(k-i)��e(k-i)����ƫ�
��������ӦʱϵͳSFIN�в���W��У��������ʽ |
|
 |
(4.63) | |
|
��ʽ(4��63)�У���J(k)��ƫ����ȡ����
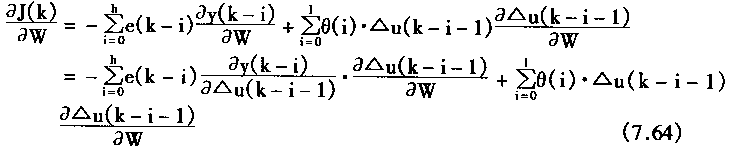
������aJ(k)/aw��a��u(k-i-1)/aw�ɱ���������
 |
(4.65) |
| ������ʽ���У���u(k-i)�ǿɴ�������������õ� |
|
| ��u(k-i)=SFIN[e(k-i),��e(k-i);W(k)] |
(4.66) | |
|
3������ϵͳ�����н��
���ڸ����Ķ�����SFIN��ʵ����ģ�����Ʋ�ȡ����Ľ����
(1)���ض���PL
���ض���PL��ʾ���£�
PL(V1,V2,V3,V4,V5,yd)
���У�yd���趨�������㡣
���ض�������������ϵ����ʽ��ʾ
yk+1=f(yk,yk-1,yk-2)+g(k,yk-3,yk-4,Uk-2)+(1.1+V1)uk-1+(1+V2)uk+Zk (4.67)
����
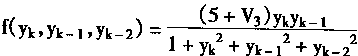 |
(4.68) | |
|
g(k,yk-3,yk-4,Uk-2)=V4Sin[0.08(yk-3+yk-4)]Uk-2+V5cos(0.05k��) (4.69)
g(��)�Ǹ����źţ�
Vi(i��1��2������5)��ʵ������
Zk�ǰ�������������ֵΪ0��1��
(2)ѵ�����ݼ�
������ѵ�����ݼ����4��1��ʾ����һ����30��ѵ�����ݡ���Щ�������ڶ�SFIN���г�ʼ������ѧϰ���Ӷ�ȷ��SFIN�ij�ʼ������
��4-1 ����ѵ����
| k |
E(k) |
��E(k) |
��U(k) |
k |
E(k) |
��E(k) |
��U(k) |
| 1 |
3.0000 |
0.0000 |
0.1893 |
16 |
-0.1472 |
-0.5316 |
0.0462 |
| 2 |
2.8228 |
-0.1772 |
0.1732 |
17 |
-0.2259 |
-0.0787 |
0.0024 |
| 3 |
2.3440 |
-0.4788 |
0.1421 |
18 |
-0.1874 |
0.0385 |
-0.0040 |
| 4 |
1.6426 |
-0.7014 |
0.1063 |
19 |
0.0424 |
0.2298 |
0.0079 |
| 5 |
0.5628 |
-1.0798 |
0.0578 |
20 |
0.1303 |
0.0879 |
0.0116 |
| 6 |
-0.1911 |
-0.7539 |
0.0255 |
21 |
5.0000 |
0.0000 |
0.5576 |
| 7 |
-0.5456 |
-0.3545 |
-0.0058 |
22 |
4.4161 |
-0.5839 |
0.4120 |
| 8 |
-0.2664 |
0.2792 |
-0.0061 |
23 |
3.3792 |
-1.0370 |
0.2718 |
| 9 |
-0.2132 |
0.0532 |
-0.0031 |
24 |
1.5370 |
-1.8442 |
0.1901 |
| 10 |
-0.0111 |
0.2021 |
0.0030 |
25 |
0.3928 |
-1.1442 |
0.0687 |
| 11 |
4.0000 |
0.0000 |
0.3415 |
26 |
-0.3001 |
-0.6930 |
-0.0643 |
| 12 |
3.6478 |
-0.3522 |
0.2901 |
27 |
-0.1572 |
0.1429 |
0.0465 |
| 13 |
2.8956 |
-0.7522 |
0.2093 |
28 |
0.1582 |
0.3154 |
0.0102 |
| 14 |
1.5613 |
-1.3242 |
0.1322 |
29 |
0.2118 |
0.0535 |
0.0367 |
| 15 |
0.3844 |
-1.1769 |
0.0893 |
30 |
0.2653 |
0.0535 |
0.0207 | |
|
(3)����Ӧ����ѧϰ�����
���Ƕ��йصIJ���ѧϰʱ��ѡȡ��ֵ���£�
ǰ���йز�����ƫ��e��ģ��������ae,be,ce��ƫ��仯����e��ģ��������a��e,b��e,c��e,��ѧϰ��Щ����ʱ��ѧϰ�������ֱ�ѡֵΪ
ae,a��e,ce,c��e��ѧϰ��������10-6
be,b��eѧϰ������=10-8
����йز����������ʽ����P������ѧϰ��������0��00125��
��ѧϰʱ���õ�ʽ(4��65)�еIJ���ȡ��
h=1 l=0 ��=15
ͬʱ��ѧϰ��ʽ(4��63)�ĵ�������ȡ3��
ϵͳ���е������ͼ4��14��ʾ��
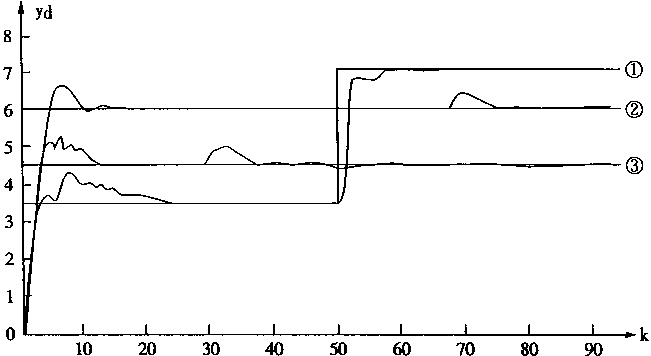
ͼ4-14 �ϴ����ʱSFIN������� |
|
��ͼ4��14�зֱ������3����Ӧ���ߣ���3����Ӧ���߷ֱ����٢ڢ���ǡ�
������Ӧ�����������ǰ��趨����k��50ʱ���иı����Ӧ�������ʱ���ض�������仯���£�
PL(0,0,0,0,0,3.5)����PL(0,0,0,0,0,7.0)
������Ӧ��������������k=70ʱ�����ı�����������Ӧ��������ض�������ı����£�
PL(0,0,0,0,0,6.0)����PL(-0.25,0.45,0.5,0,0,6.0)
������Ӧ���ߢڣ�������k��30ʱ�������ŵ���Ӧ��������ض�������ı�����
PL(0,0,0,0,0,4.5)����PL(0,0,0,0.35,0.25,4.5)
����������ӦURL(Unidirectional Linear Response)��Ԫ���Թ���ģ�������磬�Ӷ����Թ�����ģ��������������һ���н�����URLģ��������ƵĿ���ϵͳ��
1��URLģ������
ULR��Ԫ���������ź�ȡֵΪ��ʱ���������ԣ�������Ϊ��ʱ�����Ϊ�����Ԫ��URL��Ԫ�Ľṹ�����Կ���ͼ4��15˵������ͼ�У�(a)����Ԫ�ṹ���ɼ�����һ����Ԫ��һ���ģ�(b)����Ԫ���ԣ��ɼ���ȡ��ֵʱΪ���ԣ�������ȡ��ֵʱ�����Ϊ�㡣

(a) |
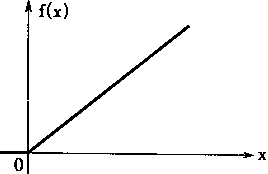
(b) | |
|
ͼ4-15 URL��Ԫ������
��ͼ4��15�У�x1��x2��������xn�������ģ��������Ux1��Ux2��������Uxm�ֱ��Ƕ�Ӧ������������Wi��xi��i��1��2��������n����Ԫ������Ȩϵ�������Ƿ�ֵ��f(x)����Ԫ����������У�
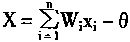 |
(4.70) |
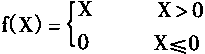 |
(4.71) | |
|
����URL��Ԫ��ɵ�����������磬������ʵ�ָ��ֻ�������ϵ�ģ����������
��1 ��URL����ʵ��ģ���̺���ϵ��
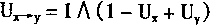
����URL����Ľṹ��ͼ4��16��ʾ����һ����3��URL��Ԫ������Ϊ2�㡣������2��ģ����Ux+Uy��

ͼ4-16 URL���� |
|
�����ԣ���Ϊ���Ux����y=f3������
 |
(4.72) | |
|
��

����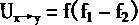
��ͼ4��16�У����Կ���f1��f2����ȡ���£�
f1=f(W1'Ux+W2"Uy-')
f2=f(W1"Ux+W2'Uy-")
��
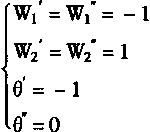
f1=f(-Ux+Uy+1)
f2=f(-Ux+Uy)
��Ȼ
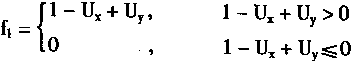

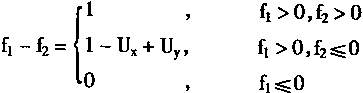
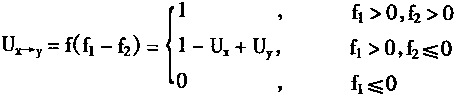 (4.73) (4.73)
|
|
��ʽ(4��73)�п�֪����f1>0��f2��0ʱ��
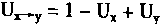
��ʱ��������f2��0������
-Ux+Uy��0
Ҳ���� 1-Ux+Uy��1
�ʶ�ʽ(4��73)����ULR����ʵ�ֵĹ���Ϊ
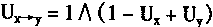
��2 ��ULR����ʵ���н����Ux��y��1��(1-Ux+Uy)��
����ͼ4��16��ͬһULR���磬�����
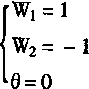
����
Ux��y=f(W1f1-W2f2-��)
=f(f1-f2)

����
f1=f(Ux+Uy)
f2=f(Ux+Uy-1)
��Ȼ
f1=Ux+Uy
 (4.74) (4.74)
|
|
��f2��0ʱ����Ux+Uy-1��0����
Ux+Uy��1
�ʶ���
Ux��y=1��(Ux+Uy)
������URL����ʵ�֡�
2.ULRģ��������
ULRģ������������ULR����ʵ��ģ����������ģ�ͼ4��17������һ������4�����ƹ����ULR���磬������������в��þֲ����ƽ����LMOM(Localized Mean of Maximum Method)���о�ȷ����

ͼ4-17 ULRģ�������� |
|
��ͼ4��17�У�һ����5��ṹ����ÿһ���У���Ԫ����������ͬ�ģ�������ֱ���ܸ�������ã�
(1)��1��
��������ڵ㣬����ִ���κβ�����
(2)��2��
�������������㣬���ǿ��ƹ�����ǰ����ģ�������������������ƹ�����������ʽ��
if x1 is A1i and x2 is A2i then y is Bi
����һ���У���Ԫ������UA1i��UA2i����������������һ���У��õ��Ķ�Ӧ������������ȡ�UA1i(x1)��UA2i(x2)��
��ULR�����У���������������������������һ���У�ÿһ���ڵ�Ҳ����һ��URL���繹�ɵġ�ULR����ʵ���������������Ľṹ��ͼ4��18��ʾ��

ͼ4-18 ULR����ʵ�ֵ������������� |
|
������������������������ķ������£�
������������������������ߵĺ����꽻��c��c�㵽�ұ߶��ǵľ���R��c�㵽��߶��ǵľ���L�����������ʾ���ʶ�������������������ͼ����ͼ4��19��ʾ��
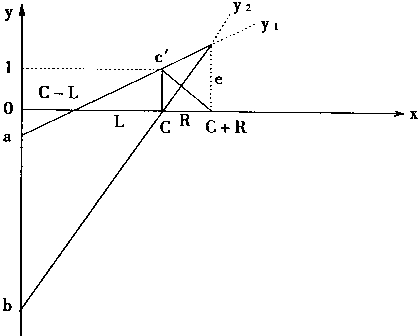
ͼ4-19 ����������������״ |
|
��ͼ4��19���Կ���
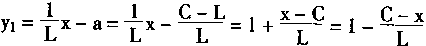 |
(4.75) | |
|
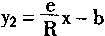
����
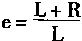
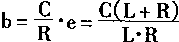
�ʶ�
 |
(4.76) | |
|
����y1������ULR���ԣ�������x<C-Lʱ�����Ϊ0��
����y2������ULR���ԣ�������x<Cʱ�����Ϊ0��
�����y1��y2Ϊ���룬���У�
��x��C-Lʱ�����Ϊ0
��x��Cʱ�����Ϊy1
��x��C+Rʱ�����Ϊy1-y2
��x��C+Rʱ����y1-y2��0�������Ϊ0��
�����ԣ����Եõ�(C-L)��C'����(C+R)������ɵ������Σ�������ͼ4-18�������

����


����y1��y2����ʵ�����������������ܣ�ֻҪ�IJ���R��L��C�������ʵ�ֲ�ͬ����������������
(3)��3��
����ǰ������㣬ִ����С����������һ����ö���ULR�������γɡ���ͼ4-20��ʾ��
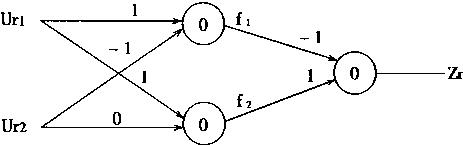
ͼ4-20 ǰ����С������ |
|
��ͼ4-20�У���֪�书��Ϊ��
f1=f(Ur1-Ur2-0)=f(Ur1-Ur2)
f2=f(Ur1-0)=f(Ur1)
Zr=f(-f1+f2-0)=f(-f1+f2)
����ֱ�������ֲ�ͬ�����������
������Ur1<Ur2ʱ
f1=f(Ur1-Ur2)=0
f2=f(Ur1)=Ur1
�Ӷ���
Zr=f(-f1+f2)
=f(0+Ur1)
=Ur1
������Ur1>Ur2ʱ
f1=f(Ur1-Ur2)=Ur1-Ur2
f2=f(Ur1)Ur1
��
Zr=f(-f1+f2)
=f(-Ur1+Ur2+Ur1)
=Ur2
����Ur1=Ur2ʱ
f1=f(Ur1-Ur2)=0
f2=f(Ur1)=Ur1
��
Zr=f(-f1+f2)=f(Ur1)=Ur1
���Ͽ�֪��ͼ4��20��URL����ʵ������С�����㡣
(4)��4��
���Ǻ������㣬��ִ�����ֲ�����һ���ǰ�ǰ����С���������ٶԺ��ģ��������С���㣻��һ�ֲ�����ִ�з�ģ�����������ֲ��������ɾֲ����ƽ����LMOM(Local Mean-of-Maximum)��ģ��������ʵ�ֵġ�
LMOM����������ͼ4��21����˵����
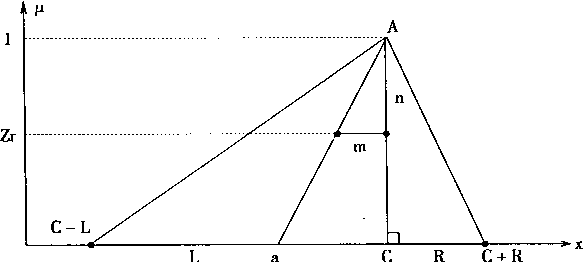
ͼ4-21 LMOM����ģ���� |
|
��ͼ4��21�У�a��������(C-L)��A��(C+R)�ĵױߵ��е㣬��a������Ϊ
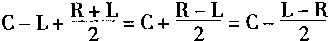
��������Ϊ1ʱ����ģ�����Ľ��ΪC��
��������Ϊ0ʱ����ģ�����Ľ��Ϊ �� ��
��������ΪZrʱ������
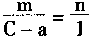
��
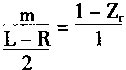

��ģ�����Ľ��Ϊ��(C-m)
 (4.77) (4.77)
����������������Ϊr��ǰ����С�����ΪZr����ģ���������Ur-1(Zr)��ʾ����
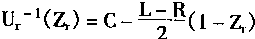 (4.78) (4.78)
��ģ�ﻯ�ɲ�������ͼ4��22�Ľṹ��
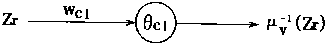
ͼ4-22 ��ģ�����ӵ� |
|
��ͼ��ȡ

��Ȼ��

����

�ʶ�
 (4.79) (4.79)
(5)��5��
�������о��㡣������ù���ǰ������С������Ϊ��Ȩϵ�����Ա�����ĺ����ģ����������м�Ȩ��ȡ��Ȩƽ��ֵΪ����о����F��
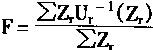 (4.80) (4.80)
|
|
3��ULRģ��������ѧ
ULRģ���������У���ҪѧϰҪ�Ǻ������������ĵ�2��4���㡣
��ѧϰʱ��Ŀ�꺯����Q��ʾ�������������IJ�����P��ʾ��ѧϰ��Ŀ�ľ���ʹĿ�꺯��Q�ﵽ��С��һ��Ŀ�꺯��Q�������������ʵ�������������
���ݶȷ���URL����ĵ�2��4�����ѧϰ�����ǰ�-aQ��aP�����IJ���P����
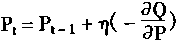 |
(4.81) |
| ����Q��ʱ��Ϊ���ӣ�����ʱҪ���ȿ���aQ��aP��Ҳ��д�� |
|
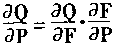 |
(4.82) |
| ����ʽ�У�aQ��aFΪ�˷��������������ʽ��ȡ |
|
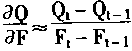 |
(4.83) | |
|
��Ȼ�����ǿ���ֱ����õġ�
����ֱ�Ե�2��4��������������ѧϰ����˵��
���ڵ�4�����������ѧϰ�����㷨���£�
���ڵ�5�����ΪF������
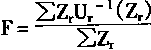
����4�����ΪUr-1(Zr)������

����
 (4.84) (4.84)
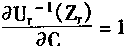 (4.85) (4.85)
 (4.86) (4.86)
 (4.87) (4.87)
���У�Sj�ǵ�j����������Ա�����r�����Ա���ֵ��
��Ȼ������ʽ(4��84)��(4��87)������aF��aP��
���ڵ�2����ԣ����Ҫ��aF��aP����Ӧ���ǣ�
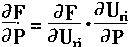 (4.88) (4.88)
���У�Uri�ǵ�2������
����
 (4.89) (4.89)
���У�Ak�ǵ�k�������ǰ�����Ա���


���У�Ur-1(Zr)��Ur-1(Zr)�ĵ�����
ͬʱ������ʽ(4��75)��(4��76)��aUri��aP��������ȡ��
��������ڵ�2�㣻aF��aP���������
��ʽ(4��82)�У�����aQ��aF��aF��aP���ڵ�2��4�����������ʶ��ܶ��������������������ѧϰ��һ��aQ��aF��ȡʵ��ֵ��ֻȡ����ţ����У�

�����
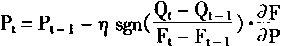
4��ULRģ���������Ե����ڵĿ���
�Ե����ڵĿ��Ʋ�������9�������������ɵĿ��ƹ���ʵ�֣����4��2��ʾ��
|
�� �� |
�Ƕȱ仯������ |
| PO2 |
ZE2 |
NE2 |
|
�� ���� |
PO1 |
PL |
PM |
ZE |
| ZE1 |
PS |
ZE |
NS |
| NE1 |
ZE |
NM |
NL | |
|
�Ƕ����ǵ����ں�ƽ��λ�õļнǣ����ķ�Χȡ-12����+12�����Ƕȱ仯�������ķ�Χȡÿ��-12������-12����S����ÿ��+12������+12����S��
�����ڰ�װ��һ��С���ϣ�Ϊ��ʹ�������ܴ���ƽ��״̬���ʶ�Ҫ��С�����п��ơ�
�Ƕ������Ƕȱ仯�������Լ����Ƶ�ģ��������ȡ�����������������ǵIJ����ֱ����4��3����ʾ��
��4-1 ��������
|
ģ���� |
C |
L |
R |
| PO1
ZE1
NE1 |
0.3
0.0
-0.3 |
0.3
0.3
5000 |
5000
0.3
0.3 |
| PO2
ZE2
NE2 |
1.0
0.0
-1.0 |
1.0
1.0
5000 |
5000
1.0
1.0 |
| PL
PM
PS
ZE
NS
NM
NL |
20.0
10.0
5.0
0.0
-5.0
-10.0
-20.0 |
5.0
5.0
4.0
1.0
5.0
6.0
0.0 |
0.0
6.0
5.0
1.0
4.0
5.0
5.0 | |
|
ģ���������������нǶȺͽǶȱ仯�ʣ����Ƕ���һ����[-1��1]���䡣ʵ�ʿ��ƵĽ����ͼ4��23����ʾ����ͼ�п�֪����ִ���˴�Լ500�����ҹ���������Դﵽƽ��״̬��ͼ�и������dz�ʼ�ǶȲ�ͬʱ�Ĺ�������״̬��
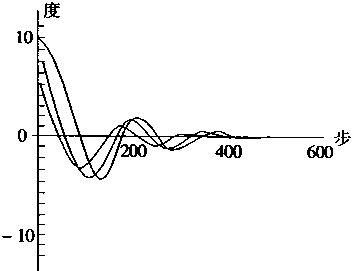
(a) |
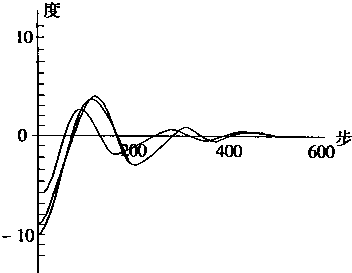
(b) |
|
ͼ4-23 ������ƽ������� | | |
|